ref fix
This commit is contained in:
parent
d67fbad269
commit
3f267fe1b9
|
|
@ -0,0 +1,14 @@
|
|||
build/
|
||||
build-debug/
|
||||
build-*/
|
||||
|
||||
compile_commands.json
|
||||
|
||||
.exrc
|
||||
.cache
|
||||
.DS_Store
|
||||
.stablelm
|
||||
.gpt-2
|
||||
|
||||
src/arm_neon.h
|
||||
tests/arm_neon.h
|
||||
|
|
@ -0,0 +1,77 @@
|
|||
cmake_minimum_required (VERSION 3.0)
|
||||
project(ggml VERSION 0.1.0)
|
||||
|
||||
set(CMAKE_EXPORT_COMPILE_COMMANDS "on")
|
||||
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/bin)
|
||||
set(CMAKE_INSTALL_RPATH "${CMAKE_INSTALL_PREFIX}/lib")
|
||||
|
||||
if(CMAKE_SOURCE_DIR STREQUAL CMAKE_CURRENT_SOURCE_DIR)
|
||||
set(GGML_STANDALONE ON)
|
||||
include(cmake/GitVars.cmake)
|
||||
include(cmake/BuildTypes.cmake)
|
||||
else()
|
||||
set(GGML_STANDALONE OFF)
|
||||
endif()
|
||||
|
||||
# options
|
||||
|
||||
option(GGML_ALL_WARNINGS "ggml: enable all compiler warnings" ON)
|
||||
option(GGML_ALL_WARNINGS_3RD_PARTY "ggml: enable all compiler warnings in 3rd party libs" OFF)
|
||||
|
||||
option(GGML_SANITIZE_THREAD "ggml: enable thread sanitizer" OFF)
|
||||
option(GGML_SANITIZE_ADDRESS "ggml: enable address sanitizer" OFF)
|
||||
option(GGML_SANITIZE_UNDEFINED "ggml: enable undefined sanitizer" OFF)
|
||||
|
||||
option(GGML_BUILD_TESTS "ggml: build tests" ${GGML_STANDALONE})
|
||||
option(GGML_BUILD_EXAMPLES "ggml: build examples" ${GGML_STANDALONE})
|
||||
|
||||
option(GGML_PERF "ggml: enable perf timings" OFF)
|
||||
option(GGML_NO_ACCELERATE "ggml: disable Accelerate framework" OFF)
|
||||
option(GGML_OPENBLAS "ggml: use OpenBLAS" OFF)
|
||||
option(GGML_CUBLAS "ggml: use cuBLAS" OFF)
|
||||
|
||||
# sanitizers
|
||||
|
||||
if (GGML_SANITIZE_THREAD)
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=thread")
|
||||
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=thread")
|
||||
endif()
|
||||
|
||||
if (GGML_SANITIZE_ADDRESS)
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=address -fno-omit-frame-pointer")
|
||||
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=address -fno-omit-frame-pointer")
|
||||
endif()
|
||||
|
||||
if (GGML_SANITIZE_UNDEFINED)
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=undefined")
|
||||
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=undefined")
|
||||
endif()
|
||||
|
||||
#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -ffast-math")
|
||||
#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -march=native")
|
||||
#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mcpu=native")
|
||||
|
||||
# dependencies
|
||||
|
||||
set(CMAKE_C_STANDARD 11)
|
||||
set(CMAKE_CXX_STANDARD 11)
|
||||
|
||||
find_package(Threads REQUIRED)
|
||||
|
||||
# main
|
||||
|
||||
if (NOT CMAKE_BUILD_TYPE AND NOT CMAKE_CONFIGURATION_TYPES)
|
||||
set(CMAKE_BUILD_TYPE Release CACHE STRING "Build type" FORCE)
|
||||
set_property(CACHE CMAKE_BUILD_TYPE PROPERTY STRINGS "Debug" "Release" "RelWithDebInfo")
|
||||
endif ()
|
||||
|
||||
add_subdirectory(src)
|
||||
|
||||
if (GGML_BUILD_TESTS)
|
||||
enable_testing()
|
||||
add_subdirectory(tests)
|
||||
endif ()
|
||||
|
||||
if (GGML_BUILD_EXAMPLES)
|
||||
add_subdirectory(examples)
|
||||
endif ()
|
||||
|
|
@ -0,0 +1,21 @@
|
|||
MIT License
|
||||
|
||||
Copyright (c) 2022 Georgi Gerganov
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
|
|
@ -0,0 +1,106 @@
|
|||
# ggml
|
||||
|
||||
Tensor library for machine learning
|
||||
|
||||
***Note that this project is under development and not ready for production use. \
|
||||
Some of the development is currently happening in the [llama.cpp](https://github.com/ggerganov/llama.cpp) and [whisper.cpp](https://github.com/ggerganov/whisper.cpp) repos***
|
||||
|
||||
## Features
|
||||
|
||||
- Written in C
|
||||
- 16-bit float support
|
||||
- Integer quantization support (4-bit, 5-bit, 8-bit, etc.)
|
||||
- Automatic differentiation
|
||||
- ADAM and L-BFGS optimizers
|
||||
- Optimized for Apple Silicon
|
||||
- On x86 architectures utilizes AVX / AVX2 intrinsics
|
||||
- No third-party dependencies
|
||||
- Zero memory allocations during runtime
|
||||
|
||||
## Roadmap
|
||||
|
||||
- [X] Example of GPT-2 inference [examples/gpt-2](https://github.com/ggerganov/ggml/tree/master/examples/gpt-2)
|
||||
- [X] Example of GPT-J inference [examples/gpt-j](https://github.com/ggerganov/ggml/tree/master/examples/gpt-j)
|
||||
- [X] Example of Whisper inference [examples/whisper](https://github.com/ggerganov/ggml/tree/master/examples/whisper)
|
||||
- [X] Support 4-bit integer quantization https://github.com/ggerganov/ggml/pull/27
|
||||
- [X] Example of Cerebras-GPT inference [examples/gpt-2](https://github.com/ggerganov/ggml/tree/master/examples/gpt-2)
|
||||
- [ ] Example of FLAN-T5 inference https://github.com/ggerganov/ggml/pull/12
|
||||
- [X] Example of LLaMA inference [ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp)
|
||||
- [X] Example of LLaMA training [ggerganov/llama.cpp/examples/baby-llama](https://github.com/ggerganov/llama.cpp/tree/master/examples/baby-llama)
|
||||
- [X] Example of BLOOM inference [NouamaneTazi/bloomz.cpp](https://github.com/NouamaneTazi/bloomz.cpp)
|
||||
- [X] Example of RWKV inference [saharNooby/rwkv.cpp](https://github.com/saharNooby/rwkv.cpp)
|
||||
- [ ] Example of [SAM](https://github.com/facebookresearch/segment-anything) inference
|
||||
- [ ] Idea for GPU support: https://github.com/ggerganov/llama.cpp/discussions/915
|
||||
- [X] Example of StableLM (GPT-NeoX) inference [examples/gpt-neox](https://github.com/ggerganov/ggml/tree/master/examples/gpt-neox)
|
||||
- [X] Example of BERT inference [skeskinen/bert.cpp](https://github.com/skeskinen/bert.cpp)
|
||||
- [X] Example of 💫 StarCoder inference [examples/starcoder](https://github.com/ggerganov/ggml/tree/master/examples/starcoder)
|
||||
- [X] Example of MPT inference [examples/mpt](https://github.com/ggerganov/ggml/tree/master/examples/mpt)
|
||||
- [X] Example of Replit inference [examples/replit](https://github.com/ggerganov/ggml/tree/master/examples/replit)
|
||||
|
||||
## Whisper inference (example)
|
||||
|
||||
With ggml you can efficiently run [Whisper](examples/whisper) inference on the CPU.
|
||||
|
||||
Memory requirements:
|
||||
|
||||
| Model | Disk | Mem |
|
||||
| --- | --- | --- |
|
||||
| tiny | 75 MB | ~280 MB |
|
||||
| base | 142 MB | ~430 MB |
|
||||
| small | 466 MB | ~1.0 GB |
|
||||
| medium | 1.5 GB | ~2.6 GB |
|
||||
| large | 2.9 GB | ~4.7 GB |
|
||||
|
||||
## GPT inference (example)
|
||||
|
||||
With ggml you can efficiently run [GPT-2](examples/gpt-2) and [GPT-J](examples/gpt-j) inference on the CPU.
|
||||
|
||||
Here is how to run the example programs:
|
||||
|
||||
```bash
|
||||
# Build ggml + examples
|
||||
git clone https://github.com/ggerganov/ggml
|
||||
cd ggml
|
||||
mkdir build && cd build
|
||||
cmake ..
|
||||
make -j4 gpt-2 gpt-j
|
||||
|
||||
# Run the GPT-2 small 117M model
|
||||
../examples/gpt-2/download-ggml-model.sh 117M
|
||||
./bin/gpt-2 -m models/gpt-2-117M/ggml-model.bin -p "This is an example"
|
||||
|
||||
# Run the GPT-J 6B model (requires 12GB disk space and 16GB CPU RAM)
|
||||
../examples/gpt-j/download-ggml-model.sh 6B
|
||||
./bin/gpt-j -m models/gpt-j-6B/ggml-model.bin -p "This is an example"
|
||||
|
||||
# Run the Cerebras-GPT 111M model
|
||||
# Download from: https://huggingface.co/cerebras
|
||||
python3 ../examples/gpt-2/convert-cerebras-to-ggml.py /path/to/Cerebras-GPT-111M/
|
||||
./bin/gpt-2 -m /path/to/Cerebras-GPT-111M/ggml-model-f16.bin -p "This is an example"
|
||||
```
|
||||
|
||||
The inference speeds that I get for the different models on my 32GB MacBook M1 Pro are as follows:
|
||||
|
||||
| Model | Size | Time / Token |
|
||||
| --- | --- | --- |
|
||||
| GPT-2 | 117M | 5 ms |
|
||||
| GPT-2 | 345M | 12 ms |
|
||||
| GPT-2 | 774M | 23 ms |
|
||||
| GPT-2 | 1558M | 42 ms |
|
||||
| --- | --- | --- |
|
||||
| GPT-J | 6B | 125 ms |
|
||||
|
||||
For more information, checkout the corresponding programs in the [examples](examples) folder.
|
||||
|
||||
## Using cuBLAS
|
||||
|
||||
```bash
|
||||
# fix the path to point to your CUDA compiler
|
||||
cmake -DGGML_CUBLAS=ON -DCMAKE_CUDA_COMPILER=/usr/local/cuda-12.1/bin/nvcc ..
|
||||
```
|
||||
|
||||
## Resources
|
||||
|
||||
- [GGML - Large Language Models for Everyone](https://github.com/rustformers/llm/blob/main/crates/ggml/README.md): a description of the GGML format provided by the maintainers of the `llm` Rust crate, which provides Rust bindings for GGML
|
||||
- [marella/ctransformers](https://github.com/marella/ctransformers): Python bindings for GGML models.
|
||||
- [go-skynet/go-ggml-transformers.cpp](https://github.com/go-skynet/go-ggml-transformers.cpp): Golang bindings for GGML models
|
||||
|
|
@ -0,0 +1,54 @@
|
|||
# Add new build types
|
||||
|
||||
# ReleaseGG - Release with enabled asserts
|
||||
|
||||
SET(CMAKE_CXX_FLAGS_RELEASEGG
|
||||
"-O3"
|
||||
CACHE STRING "Flags used by the c++ compiler during release builds with enabled asserts."
|
||||
FORCE )
|
||||
SET(CMAKE_C_FLAGS_RELEASEGG
|
||||
"-O3"
|
||||
CACHE STRING "Flags used by the compiler during release builds with enabled asserts."
|
||||
FORCE )
|
||||
SET(CMAKE_EXE_LINKER_FLAGS_RELEASEGG
|
||||
""
|
||||
CACHE STRING "Flags used for linking binaries during release builds with enabled asserts."
|
||||
FORCE )
|
||||
SET(CMAKE_SHARED_LINKER_FLAGS_RELEASEGG
|
||||
""
|
||||
CACHE STRING "Flags used by the shared libraries linker during release builds with enabled asserts."
|
||||
FORCE )
|
||||
MARK_AS_ADVANCED(
|
||||
CMAKE_CXX_FLAGS_RELEASEGG
|
||||
CMAKE_C_FLAGS_RELEASEGG
|
||||
CMAKE_EXE_LINKER_FLAGS_RELEASEGG
|
||||
CMAKE_SHARED_LINKER_FLAGS_RELEASEGG )
|
||||
|
||||
# RelWithDebInfoGG - RelWithDebInfo with enabled asserts
|
||||
|
||||
SET(CMAKE_CXX_FLAGS_RELWITHDEBINFOGG
|
||||
"-O2 -g"
|
||||
CACHE STRING "Flags used by the c++ compiler during release builds with debug symbols and enabled asserts."
|
||||
FORCE )
|
||||
SET(CMAKE_C_FLAGS_RELWITHDEBINFOGG
|
||||
"-O2 -g"
|
||||
CACHE STRING "Flags used by the compiler during release builds with debug symbols and enabled asserts."
|
||||
FORCE )
|
||||
SET(CMAKE_EXE_LINKER_FLAGS_RELWITHDEBINFOGG
|
||||
""
|
||||
CACHE STRING "Flags used for linking binaries during release builds with debug symbols and enabled asserts."
|
||||
FORCE )
|
||||
SET(CMAKE_SHARED_LINKER_FLAGS_RELWITHDEBINFOGG
|
||||
""
|
||||
CACHE STRING "Flags used by the shared libraries linker during release builds with debug symbols and enabled asserts."
|
||||
FORCE )
|
||||
MARK_AS_ADVANCED(
|
||||
CMAKE_CXX_FLAGS_RELWITHDEBINFOGG
|
||||
CMAKE_C_FLAGS_RELWITHDEBINFOGG
|
||||
CMAKE_EXE_LINKER_FLAGS_RELWITHDEBINFOGG
|
||||
CMAKE_SHARED_LINKER_FLAGS_RELWITHDEBINFOGG )
|
||||
|
||||
if (NOT XCODE AND NOT MSVC AND NOT CMAKE_BUILD_TYPE)
|
||||
set(CMAKE_BUILD_TYPE Release CACHE STRING "Build type" FORCE)
|
||||
set_property(CACHE CMAKE_BUILD_TYPE PROPERTY STRINGS "Debug" "Release" "MinSizeRel" "RelWithDebInfo" "ReleaseGG" "RelWithDebInfoGG")
|
||||
endif()
|
||||
|
|
@ -0,0 +1,22 @@
|
|||
find_package(Git)
|
||||
|
||||
# the commit's SHA1
|
||||
execute_process(COMMAND
|
||||
"${GIT_EXECUTABLE}" describe --match=NeVeRmAtCh --always --abbrev=8
|
||||
WORKING_DIRECTORY "${CMAKE_SOURCE_DIR}"
|
||||
OUTPUT_VARIABLE GIT_SHA1
|
||||
ERROR_QUIET OUTPUT_STRIP_TRAILING_WHITESPACE)
|
||||
|
||||
# the date of the commit
|
||||
execute_process(COMMAND
|
||||
"${GIT_EXECUTABLE}" log -1 --format=%ad --date=local
|
||||
WORKING_DIRECTORY "${CMAKE_SOURCE_DIR}"
|
||||
OUTPUT_VARIABLE GIT_DATE
|
||||
ERROR_QUIET OUTPUT_STRIP_TRAILING_WHITESPACE)
|
||||
|
||||
# the subject of the commit
|
||||
execute_process(COMMAND
|
||||
"${GIT_EXECUTABLE}" log -1 --format=%s
|
||||
WORKING_DIRECTORY "${CMAKE_SOURCE_DIR}"
|
||||
OUTPUT_VARIABLE GIT_COMMIT_SUBJECT
|
||||
ERROR_QUIET OUTPUT_STRIP_TRAILING_WHITESPACE)
|
||||
|
|
@ -0,0 +1,28 @@
|
|||
if (GGML_ALL_WARNINGS)
|
||||
if (NOT MSVC)
|
||||
set(cxx_flags
|
||||
# TODO(marella): Add other warnings.
|
||||
-Wunused-variable
|
||||
-Wno-unused-function
|
||||
-Wno-multichar
|
||||
)
|
||||
add_compile_options("$<$<COMPILE_LANGUAGE:CXX>:${cxx_flags}>")
|
||||
endif()
|
||||
endif()
|
||||
|
||||
add_library(common STATIC common.cpp)
|
||||
target_include_directories(common PUBLIC ${CMAKE_CURRENT_SOURCE_DIR})
|
||||
|
||||
add_library(common-ggml STATIC common-ggml.cpp)
|
||||
target_link_libraries(common-ggml PRIVATE ggml)
|
||||
target_include_directories(common-ggml PUBLIC ${CMAKE_CURRENT_SOURCE_DIR})
|
||||
|
||||
add_subdirectory(gpt-2)
|
||||
add_subdirectory(gpt-j)
|
||||
add_subdirectory(whisper)
|
||||
add_subdirectory(mnist)
|
||||
add_subdirectory(gpt-neox)
|
||||
add_subdirectory(dolly-v2)
|
||||
add_subdirectory(replit)
|
||||
add_subdirectory(mpt)
|
||||
add_subdirectory(starcoder)
|
||||
|
|
@ -0,0 +1,235 @@
|
|||
#include "common-ggml.h"
|
||||
|
||||
#include <regex>
|
||||
#include <map>
|
||||
|
||||
static const std::map<std::string, enum ggml_ftype> GGML_FTYPE_MAP = {
|
||||
{"q4_0", GGML_FTYPE_MOSTLY_Q4_0},
|
||||
{"q4_1", GGML_FTYPE_MOSTLY_Q4_1},
|
||||
{"q5_0", GGML_FTYPE_MOSTLY_Q5_0},
|
||||
{"q5_1", GGML_FTYPE_MOSTLY_Q5_1},
|
||||
{"q8_0", GGML_FTYPE_MOSTLY_Q8_0},
|
||||
};
|
||||
|
||||
void ggml_print_ftypes(FILE * fp) {
|
||||
for (auto it = GGML_FTYPE_MAP.begin(); it != GGML_FTYPE_MAP.end(); it++) {
|
||||
fprintf(fp, " type = \"%s\" or %d\n", it->first.c_str(), it->second);
|
||||
}
|
||||
}
|
||||
|
||||
enum ggml_ftype ggml_parse_ftype(const char * str) {
|
||||
enum ggml_ftype ftype;
|
||||
if (str[0] == 'q') {
|
||||
const auto it = GGML_FTYPE_MAP.find(str);
|
||||
if (it == GGML_FTYPE_MAP.end()) {
|
||||
fprintf(stderr, "%s: unknown ftype '%s'\n", __func__, str);
|
||||
return GGML_FTYPE_UNKNOWN;
|
||||
}
|
||||
ftype = it->second;
|
||||
} else {
|
||||
ftype = (enum ggml_ftype) atoi(str);
|
||||
}
|
||||
|
||||
return ftype;
|
||||
}
|
||||
|
||||
bool ggml_common_quantize_0(
|
||||
std::ifstream & finp,
|
||||
std::ofstream & fout,
|
||||
const ggml_ftype ftype,
|
||||
const std::vector<std::string> & to_quant,
|
||||
const std::vector<std::string> & to_skip) {
|
||||
|
||||
ggml_type qtype = GGML_TYPE_F32;
|
||||
|
||||
switch (ftype) {
|
||||
case GGML_FTYPE_MOSTLY_Q4_0: qtype = GGML_TYPE_Q4_0; break;
|
||||
case GGML_FTYPE_MOSTLY_Q4_1: qtype = GGML_TYPE_Q4_1; break;
|
||||
case GGML_FTYPE_MOSTLY_Q5_0: qtype = GGML_TYPE_Q5_0; break;
|
||||
case GGML_FTYPE_MOSTLY_Q5_1: qtype = GGML_TYPE_Q5_1; break;
|
||||
case GGML_FTYPE_MOSTLY_Q8_0: qtype = GGML_TYPE_Q8_0; break;
|
||||
case GGML_FTYPE_UNKNOWN:
|
||||
case GGML_FTYPE_ALL_F32:
|
||||
case GGML_FTYPE_MOSTLY_F16:
|
||||
case GGML_FTYPE_MOSTLY_Q4_1_SOME_F16:
|
||||
{
|
||||
fprintf(stderr, "%s: invalid model type %d\n", __func__, ftype);
|
||||
return false;
|
||||
}
|
||||
};
|
||||
|
||||
if (!ggml_is_quantized(qtype)) {
|
||||
fprintf(stderr, "%s: invalid quantization type %d (%s)\n", __func__, qtype, ggml_type_name(qtype));
|
||||
return false;
|
||||
}
|
||||
|
||||
size_t total_size_org = 0;
|
||||
size_t total_size_new = 0;
|
||||
|
||||
std::vector<float> work;
|
||||
|
||||
std::vector<uint8_t> data_u8;
|
||||
std::vector<ggml_fp16_t> data_f16;
|
||||
std::vector<float> data_f32;
|
||||
|
||||
std::vector<int64_t> hist_all(1 << 4, 0);
|
||||
|
||||
while (true) {
|
||||
int32_t n_dims;
|
||||
int32_t length;
|
||||
int32_t ttype;
|
||||
|
||||
finp.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
|
||||
finp.read(reinterpret_cast<char *>(&length), sizeof(length));
|
||||
finp.read(reinterpret_cast<char *>(&ttype), sizeof(ttype));
|
||||
|
||||
if (finp.eof()) {
|
||||
break;
|
||||
}
|
||||
|
||||
int32_t nelements = 1;
|
||||
int32_t ne[4] = { 1, 1, 1, 1 };
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
finp.read (reinterpret_cast<char *>(&ne[i]), sizeof(ne[i]));
|
||||
nelements *= ne[i];
|
||||
}
|
||||
|
||||
std::string name(length, 0);
|
||||
finp.read (&name[0], length);
|
||||
|
||||
printf("%64s - [%5d, %5d, %5d], type = %6s ", name.data(), ne[0], ne[1], ne[2], ggml_type_name((ggml_type) ttype));
|
||||
|
||||
bool quantize = false;
|
||||
|
||||
// check if we should quantize this tensor
|
||||
for (const auto & s : to_quant) {
|
||||
if (std::regex_match(name, std::regex(s))) {
|
||||
quantize = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// check if we should skip this tensor
|
||||
for (const auto & s : to_skip) {
|
||||
if (std::regex_match(name, std::regex(s))) {
|
||||
quantize = false;
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// quantize only 2D tensors
|
||||
quantize &= (n_dims == 2);
|
||||
|
||||
if (quantize) {
|
||||
if (ttype != GGML_TYPE_F32 && ttype != GGML_TYPE_F16) {
|
||||
fprintf(stderr, "%s: unsupported ttype %d (%s) for integer quantization\n", __func__, ttype, ggml_type_name((ggml_type) ttype));
|
||||
return false;
|
||||
}
|
||||
|
||||
if (ttype == GGML_TYPE_F16) {
|
||||
data_f16.resize(nelements);
|
||||
finp.read(reinterpret_cast<char *>(data_f16.data()), nelements * sizeof(ggml_fp16_t));
|
||||
data_f32.resize(nelements);
|
||||
for (int i = 0; i < nelements; ++i) {
|
||||
data_f32[i] = ggml_fp16_to_fp32(data_f16[i]);
|
||||
}
|
||||
} else {
|
||||
data_f32.resize(nelements);
|
||||
finp.read(reinterpret_cast<char *>(data_f32.data()), nelements * sizeof(float));
|
||||
}
|
||||
|
||||
ttype = qtype;
|
||||
} else {
|
||||
const int bpe = (ttype == 0) ? sizeof(float) : sizeof(uint16_t);
|
||||
|
||||
data_u8.resize(nelements*bpe);
|
||||
finp.read(reinterpret_cast<char *>(data_u8.data()), nelements * bpe);
|
||||
}
|
||||
|
||||
fout.write(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
|
||||
fout.write(reinterpret_cast<char *>(&length), sizeof(length));
|
||||
fout.write(reinterpret_cast<char *>(&ttype), sizeof(ttype));
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
fout.write(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i]));
|
||||
}
|
||||
fout.write(&name[0], length);
|
||||
|
||||
if (quantize) {
|
||||
work.resize(nelements); // for quantization
|
||||
|
||||
size_t cur_size = 0;
|
||||
std::vector<int64_t> hist_cur(1 << 4, 0);
|
||||
|
||||
switch ((ggml_type) ttype) {
|
||||
case GGML_TYPE_Q4_0:
|
||||
{
|
||||
cur_size = ggml_quantize_q4_0(data_f32.data(), work.data(), nelements, ne[0], hist_cur.data());
|
||||
} break;
|
||||
case GGML_TYPE_Q4_1:
|
||||
{
|
||||
cur_size = ggml_quantize_q4_1(data_f32.data(), work.data(), nelements, ne[0], hist_cur.data());
|
||||
} break;
|
||||
case GGML_TYPE_Q5_0:
|
||||
{
|
||||
cur_size = ggml_quantize_q5_0(data_f32.data(), work.data(), nelements, ne[0], hist_cur.data());
|
||||
} break;
|
||||
case GGML_TYPE_Q5_1:
|
||||
{
|
||||
cur_size = ggml_quantize_q5_1(data_f32.data(), work.data(), nelements, ne[0], hist_cur.data());
|
||||
} break;
|
||||
case GGML_TYPE_Q8_0:
|
||||
{
|
||||
cur_size = ggml_quantize_q8_0(data_f32.data(), work.data(), nelements, ne[0], hist_cur.data());
|
||||
} break;
|
||||
case GGML_TYPE_F32:
|
||||
case GGML_TYPE_F16:
|
||||
case GGML_TYPE_I8:
|
||||
case GGML_TYPE_I16:
|
||||
case GGML_TYPE_I32:
|
||||
case GGML_TYPE_Q8_1:
|
||||
case GGML_TYPE_COUNT:
|
||||
{
|
||||
fprintf(stderr, "%s: unsupported quantization type %d (%s)\n", __func__, ttype, ggml_type_name((ggml_type) ttype));
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
fout.write(reinterpret_cast<char *>(work.data()), cur_size);
|
||||
total_size_new += cur_size;
|
||||
|
||||
printf("size = %8.2f MB -> %8.2f MB | hist: ", nelements * sizeof(float)/1024.0/1024.0, cur_size/1024.0/1024.0);
|
||||
for (int i = 0; i < (int) hist_cur.size(); ++i) {
|
||||
hist_all[i] += hist_cur[i];
|
||||
}
|
||||
|
||||
for (int i = 0; i < (int) hist_cur.size(); ++i) {
|
||||
printf("%5.3f ", hist_cur[i] / (float)nelements);
|
||||
}
|
||||
printf("\n");
|
||||
} else {
|
||||
printf("size = %8.3f MB\n", data_u8.size()/1024.0/1024.0);
|
||||
fout.write(reinterpret_cast<char *>(data_u8.data()), data_u8.size());
|
||||
total_size_new += data_u8.size();
|
||||
}
|
||||
|
||||
total_size_org += nelements * sizeof(float);
|
||||
}
|
||||
|
||||
printf("%s: model size = %8.2f MB\n", __func__, total_size_org/1024.0/1024.0);
|
||||
printf("%s: quant size = %8.2f MB | ftype = %d (%s)\n", __func__, total_size_new/1024.0/1024.0, ftype, ggml_type_name(qtype));
|
||||
|
||||
{
|
||||
int64_t sum_all = 0;
|
||||
for (int i = 0; i < (int) hist_all.size(); ++i) {
|
||||
sum_all += hist_all[i];
|
||||
}
|
||||
|
||||
printf("%s: hist: ", __func__);
|
||||
for (int i = 0; i < (int) hist_all.size(); ++i) {
|
||||
printf("%5.3f ", hist_all[i] / (float)sum_all);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
|
@ -0,0 +1,18 @@
|
|||
#pragma once
|
||||
|
||||
#include "ggml.h"
|
||||
|
||||
#include <fstream>
|
||||
#include <vector>
|
||||
#include <string>
|
||||
|
||||
enum ggml_ftype ggml_parse_ftype(const char * str);
|
||||
|
||||
void ggml_print_ftypes(FILE * fp = stderr);
|
||||
|
||||
bool ggml_common_quantize_0(
|
||||
std::ifstream & finp,
|
||||
std::ofstream & fout,
|
||||
const ggml_ftype ftype,
|
||||
const std::vector<std::string> & to_quant,
|
||||
const std::vector<std::string> & to_skip);
|
||||
|
|
@ -0,0 +1,668 @@
|
|||
#include "common.h"
|
||||
|
||||
// third-party utilities
|
||||
// use your favorite implementations
|
||||
#define DR_WAV_IMPLEMENTATION
|
||||
#include "dr_wav.h"
|
||||
|
||||
#include <cmath>
|
||||
#include <fstream>
|
||||
#include <regex>
|
||||
#include <locale>
|
||||
#include <codecvt>
|
||||
|
||||
#ifndef M_PI
|
||||
#define M_PI 3.14159265358979323846
|
||||
#endif
|
||||
|
||||
bool gpt_params_parse(int argc, char ** argv, gpt_params & params) {
|
||||
for (int i = 1; i < argc; i++) {
|
||||
std::string arg = argv[i];
|
||||
|
||||
if (arg == "-s" || arg == "--seed") {
|
||||
params.seed = std::stoi(argv[++i]);
|
||||
} else if (arg == "-t" || arg == "--threads") {
|
||||
params.n_threads = std::stoi(argv[++i]);
|
||||
} else if (arg == "-p" || arg == "--prompt") {
|
||||
params.prompt = argv[++i];
|
||||
} else if (arg == "-n" || arg == "--n_predict") {
|
||||
params.n_predict = std::stoi(argv[++i]);
|
||||
} else if (arg == "--top_k") {
|
||||
params.top_k = std::max(1, std::stoi(argv[++i]));
|
||||
} else if (arg == "--top_p") {
|
||||
params.top_p = std::stof(argv[++i]);
|
||||
} else if (arg == "--temp") {
|
||||
params.temp = std::stof(argv[++i]);
|
||||
} else if (arg == "-b" || arg == "--batch_size") {
|
||||
params.n_batch = std::stoi(argv[++i]);
|
||||
} else if (arg == "-m" || arg == "--model") {
|
||||
params.model = argv[++i];
|
||||
} else if (arg == "-h" || arg == "--help") {
|
||||
gpt_print_usage(argc, argv, params);
|
||||
exit(0);
|
||||
} else if (arg == "-f" || arg == "--file") {
|
||||
if (++i > argc) {
|
||||
fprintf(stderr, "Invalid file param");
|
||||
break;
|
||||
}
|
||||
std::ifstream file(argv[i]);
|
||||
if (!file) {
|
||||
fprintf(stderr, "error: failed to open file '%s'\n", argv[i]);
|
||||
break;
|
||||
}
|
||||
std::copy(std::istreambuf_iterator<char>(file), std::istreambuf_iterator<char>(), back_inserter(params.prompt));
|
||||
if (params.prompt.back() == '\n') {
|
||||
params.prompt.pop_back();
|
||||
}
|
||||
} else {
|
||||
fprintf(stderr, "error: unknown argument: %s\n", arg.c_str());
|
||||
gpt_print_usage(argc, argv, params);
|
||||
exit(0);
|
||||
}
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
void gpt_print_usage(int /*argc*/, char ** argv, const gpt_params & params) {
|
||||
fprintf(stderr, "usage: %s [options]\n", argv[0]);
|
||||
fprintf(stderr, "\n");
|
||||
fprintf(stderr, "options:\n");
|
||||
fprintf(stderr, " -h, --help show this help message and exit\n");
|
||||
fprintf(stderr, " -s SEED, --seed SEED RNG seed (default: -1)\n");
|
||||
fprintf(stderr, " -t N, --threads N number of threads to use during computation (default: %d)\n", params.n_threads);
|
||||
fprintf(stderr, " -p PROMPT, --prompt PROMPT\n");
|
||||
fprintf(stderr, " prompt to start generation with (default: random)\n");
|
||||
fprintf(stderr, " -f FNAME, --file FNAME\n");
|
||||
fprintf(stderr, " load prompt from a file\n");
|
||||
fprintf(stderr, " -n N, --n_predict N number of tokens to predict (default: %d)\n", params.n_predict);
|
||||
fprintf(stderr, " --top_k N top-k sampling (default: %d)\n", params.top_k);
|
||||
fprintf(stderr, " --top_p N top-p sampling (default: %.1f)\n", params.top_p);
|
||||
fprintf(stderr, " --temp N temperature (default: %.1f)\n", params.temp);
|
||||
fprintf(stderr, " -b N, --batch_size N batch size for prompt processing (default: %d)\n", params.n_batch);
|
||||
fprintf(stderr, " -m FNAME, --model FNAME\n");
|
||||
fprintf(stderr, " model path (default: %s)\n", params.model.c_str());
|
||||
fprintf(stderr, "\n");
|
||||
}
|
||||
|
||||
std::string gpt_random_prompt(std::mt19937 & rng) {
|
||||
const int r = rng() % 10;
|
||||
switch (r) {
|
||||
case 0: return "So";
|
||||
case 1: return "Once upon a time";
|
||||
case 2: return "When";
|
||||
case 3: return "The";
|
||||
case 4: return "After";
|
||||
case 5: return "If";
|
||||
case 6: return "import";
|
||||
case 7: return "He";
|
||||
case 8: return "She";
|
||||
case 9: return "They";
|
||||
default: return "To";
|
||||
}
|
||||
|
||||
return "The";
|
||||
}
|
||||
|
||||
std::string trim(const std::string & s) {
|
||||
std::regex e("^\\s+|\\s+$");
|
||||
return std::regex_replace(s, e, "");
|
||||
}
|
||||
|
||||
std::string replace(const std::string & s, const std::string & from, const std::string & to) {
|
||||
std::string result = s;
|
||||
size_t pos = 0;
|
||||
while ((pos = result.find(from, pos)) != std::string::npos) {
|
||||
result.replace(pos, from.length(), to);
|
||||
pos += to.length();
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
void gpt_vocab::add_special_token(const std::string & token) {
|
||||
special_tokens.push_back(token);
|
||||
}
|
||||
|
||||
std::map<std::string, int32_t> json_parse(const std::string & fname) {
|
||||
std::map<std::string, int32_t> result;
|
||||
|
||||
// read file into string
|
||||
std::string json;
|
||||
{
|
||||
std::ifstream ifs(fname);
|
||||
if (!ifs) {
|
||||
fprintf(stderr, "Failed to open %s\n", fname.c_str());
|
||||
exit(1);
|
||||
}
|
||||
|
||||
json = std::string((std::istreambuf_iterator<char>(ifs)),
|
||||
(std::istreambuf_iterator<char>()));
|
||||
}
|
||||
|
||||
if (json[0] != '{') {
|
||||
return result;
|
||||
}
|
||||
|
||||
// parse json
|
||||
{
|
||||
bool has_key = false;
|
||||
bool in_token = false;
|
||||
|
||||
std::string str_key = "";
|
||||
std::string str_val = "";
|
||||
|
||||
int n = json.size();
|
||||
for (int i = 1; i < n; ++i) {
|
||||
if (!in_token) {
|
||||
if (json[i] == ' ') continue;
|
||||
if (json[i] == '"') {
|
||||
in_token = true;
|
||||
continue;
|
||||
}
|
||||
} else {
|
||||
if (json[i] == '\\' && i+1 < n) {
|
||||
if (has_key == false) {
|
||||
str_key += json[i];
|
||||
} else {
|
||||
str_val += json[i];
|
||||
}
|
||||
++i;
|
||||
} else if (json[i] == '"') {
|
||||
if (has_key == false) {
|
||||
has_key = true;
|
||||
++i;
|
||||
while (json[i] == ' ') ++i;
|
||||
++i; // :
|
||||
while (json[i] == ' ') ++i;
|
||||
if (json[i] != '\"') {
|
||||
while (json[i] != ',' && json[i] != '}') {
|
||||
str_val += json[i++];
|
||||
}
|
||||
has_key = false;
|
||||
} else {
|
||||
in_token = true;
|
||||
continue;
|
||||
}
|
||||
} else {
|
||||
has_key = false;
|
||||
}
|
||||
|
||||
str_key = ::replace(str_key, "\\u0120", " " ); // \u0120 -> space
|
||||
str_key = ::replace(str_key, "\\u010a", "\n"); // \u010a -> new line
|
||||
str_key = ::replace(str_key, "\\\"", "\""); // \\\" -> "
|
||||
|
||||
try {
|
||||
result[str_key] = std::stoi(str_val);
|
||||
} catch (...) {
|
||||
//fprintf(stderr, "%s: ignoring key '%s' with value '%s'\n", fname.c_str(), str_key.c_str(), str_val.c_str());
|
||||
|
||||
}
|
||||
str_key = "";
|
||||
str_val = "";
|
||||
in_token = false;
|
||||
continue;
|
||||
}
|
||||
if (has_key == false) {
|
||||
str_key += json[i];
|
||||
} else {
|
||||
str_val += json[i];
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
std::string convert_to_utf8(const std::wstring & input) {
|
||||
std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;
|
||||
return converter.to_bytes(input);
|
||||
}
|
||||
|
||||
std::wstring convert_to_wstring(const std::string & input) {
|
||||
std::wstring_convert<std::codecvt_utf8<wchar_t>> converter;
|
||||
return converter.from_bytes(input);
|
||||
}
|
||||
|
||||
std::vector<gpt_vocab::id> gpt_tokenize(const gpt_vocab & vocab, const std::string & text) {
|
||||
std::vector<std::string> words;
|
||||
|
||||
// first split the text into words
|
||||
{
|
||||
std::string str = text;
|
||||
std::string pat = R"('s|'t|'re|'ve|'m|'ll|'d| ?[[:alpha:]]+| ?[[:digit:]]+| ?[^\s[:alpha:][:digit:]]+|\s+(?!\S)|\s+)";
|
||||
|
||||
// Generate the subpattern from the special_tokens vector if it's not empty
|
||||
if (!vocab.special_tokens.empty()) {
|
||||
std::string special_tokens_subpattern;
|
||||
for (const auto & token : vocab.special_tokens) {
|
||||
if (!special_tokens_subpattern.empty()) {
|
||||
special_tokens_subpattern += "|";
|
||||
}
|
||||
special_tokens_subpattern += token;
|
||||
}
|
||||
|
||||
// Modify the regex pattern with the generated special tokens subpattern
|
||||
pat = special_tokens_subpattern + "|" + pat;
|
||||
}
|
||||
|
||||
std::regex re(pat);
|
||||
std::smatch m;
|
||||
|
||||
while (std::regex_search(str, m, re)) {
|
||||
for (auto x : m) {
|
||||
words.push_back(x);
|
||||
}
|
||||
str = m.suffix();
|
||||
}
|
||||
}
|
||||
|
||||
// find the longest tokens that form the words:
|
||||
std::vector<gpt_vocab::id> tokens;
|
||||
for (const auto & word : words) {
|
||||
if (word.size() == 0) continue;
|
||||
|
||||
int i = 0;
|
||||
int n = word.size();
|
||||
while (i < n) {
|
||||
int j = n;
|
||||
while (j > i) {
|
||||
auto it = vocab.token_to_id.find(word.substr(i, j-i));
|
||||
if (it != vocab.token_to_id.end()) {
|
||||
tokens.push_back(it->second);
|
||||
i = j;
|
||||
j = n;
|
||||
continue;
|
||||
}
|
||||
--j;
|
||||
}
|
||||
if (i == n) {
|
||||
break;
|
||||
}
|
||||
if (j == i) {
|
||||
auto sub = word.substr(i, 1);
|
||||
if (vocab.token_to_id.find(sub) != vocab.token_to_id.end()) {
|
||||
tokens.push_back(vocab.token_to_id.at(sub));
|
||||
} else {
|
||||
fprintf(stderr, "%s: unknown token '%s'\n", __func__, sub.data());
|
||||
}
|
||||
++i;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return tokens;
|
||||
}
|
||||
|
||||
bool gpt_vocab_init(const std::string & fname, gpt_vocab & vocab) {
|
||||
printf("%s: loading vocab from '%s'\n", __func__, fname.c_str());
|
||||
|
||||
vocab.token_to_id = ::json_parse(fname);
|
||||
|
||||
for (const auto & kv : vocab.token_to_id) {
|
||||
vocab.id_to_token[kv.second] = kv.first;
|
||||
}
|
||||
|
||||
printf("%s: vocab size = %d\n", __func__, (int) vocab.token_to_id.size());
|
||||
|
||||
// print the vocabulary
|
||||
//for (auto kv : vocab.token_to_id) {
|
||||
// printf("'%s' -> %d\n", kv.first.data(), kv.second);
|
||||
//}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
gpt_vocab::id gpt_sample_top_k_top_p(
|
||||
const gpt_vocab & vocab,
|
||||
const float * logits,
|
||||
int top_k,
|
||||
double top_p,
|
||||
double temp,
|
||||
std::mt19937 & rng) {
|
||||
int n_logits = vocab.id_to_token.size();
|
||||
|
||||
std::vector<std::pair<double, gpt_vocab::id>> logits_id;
|
||||
logits_id.reserve(n_logits);
|
||||
|
||||
{
|
||||
const double scale = 1.0/temp;
|
||||
for (int i = 0; i < n_logits; ++i) {
|
||||
logits_id.push_back(std::make_pair(logits[i]*scale, i));
|
||||
}
|
||||
}
|
||||
|
||||
// find the top K tokens
|
||||
std::partial_sort(
|
||||
logits_id.begin(),
|
||||
logits_id.begin() + top_k, logits_id.end(),
|
||||
[](const std::pair<double, gpt_vocab::id> & a, const std::pair<double, gpt_vocab::id> & b) {
|
||||
return a.first > b.first;
|
||||
});
|
||||
|
||||
logits_id.resize(top_k);
|
||||
|
||||
double maxl = -INFINITY;
|
||||
for (const auto & kv : logits_id) {
|
||||
maxl = std::max(maxl, kv.first);
|
||||
}
|
||||
|
||||
// compute probs for the top K tokens
|
||||
std::vector<double> probs;
|
||||
probs.reserve(logits_id.size());
|
||||
|
||||
double sum = 0.0;
|
||||
for (const auto & kv : logits_id) {
|
||||
double p = exp(kv.first - maxl);
|
||||
probs.push_back(p);
|
||||
sum += p;
|
||||
}
|
||||
|
||||
// normalize the probs
|
||||
for (auto & p : probs) {
|
||||
p /= sum;
|
||||
}
|
||||
|
||||
if (top_p < 1.0f) {
|
||||
double cumsum = 0.0f;
|
||||
for (int i = 0; i < top_k; i++) {
|
||||
cumsum += probs[i];
|
||||
if (cumsum >= top_p) {
|
||||
top_k = i + 1;
|
||||
probs.resize(top_k);
|
||||
logits_id.resize(top_k);
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
cumsum = 1.0/cumsum;
|
||||
for (int i = 0; i < (int) probs.size(); i++) {
|
||||
probs[i] *= cumsum;
|
||||
}
|
||||
}
|
||||
|
||||
//printf("\n");
|
||||
//for (int i = 0; i < (int) probs.size(); i++) {
|
||||
// printf("%d: '%s' %f\n", i, vocab.id_to_token.at(logits_id[i].second).c_str(), probs[i]);
|
||||
//}
|
||||
//exit(0);
|
||||
|
||||
std::discrete_distribution<> dist(probs.begin(), probs.end());
|
||||
int idx = dist(rng);
|
||||
|
||||
return logits_id[idx].second;
|
||||
}
|
||||
|
||||
gpt_vocab::id gpt_sample_top_k_top_p_repeat(
|
||||
const gpt_vocab & vocab,
|
||||
const float * logits,
|
||||
const int32_t * last_n_tokens_data,
|
||||
size_t last_n_tokens_data_size,
|
||||
int top_k,
|
||||
double top_p,
|
||||
double temp,
|
||||
int repeat_last_n,
|
||||
float repeat_penalty,
|
||||
std::mt19937 & rng) {
|
||||
|
||||
int n_logits = vocab.id_to_token.size();
|
||||
|
||||
const auto * plogits = logits;
|
||||
|
||||
const auto last_n_tokens = std::vector<int32_t>(last_n_tokens_data, last_n_tokens_data + last_n_tokens_data_size);
|
||||
|
||||
if (temp <= 0) {
|
||||
// select the token with the highest logit directly
|
||||
float max_logit = plogits[0];
|
||||
gpt_vocab::id max_id = 0;
|
||||
|
||||
for (int i = 1; i < n_logits; ++i) {
|
||||
if (plogits[i] > max_logit) {
|
||||
max_logit = plogits[i];
|
||||
max_id = i;
|
||||
}
|
||||
}
|
||||
return max_id;
|
||||
}
|
||||
|
||||
|
||||
std::vector<std::pair<double, gpt_vocab::id>> logits_id;
|
||||
logits_id.reserve(n_logits);
|
||||
|
||||
{
|
||||
const float scale = 1.0f/temp;
|
||||
for (int i = 0; i < n_logits; ++i) {
|
||||
// repetition penalty from ctrl paper (https://arxiv.org/abs/1909.05858)
|
||||
// credit https://github.com/facebookresearch/llama/compare/main...shawwn:llama:main
|
||||
if (repeat_last_n > 0 && std::find(last_n_tokens.end()-repeat_last_n, last_n_tokens.end(), i) != last_n_tokens.end()) {
|
||||
// if score < 0 then repetition penalty has to multiplied to reduce the previous token probability
|
||||
if (plogits[i] < 0.0f) {
|
||||
logits_id.push_back(std::make_pair(plogits[i]*scale*repeat_penalty, i));
|
||||
} else {
|
||||
logits_id.push_back(std::make_pair(plogits[i]*scale/repeat_penalty, i));
|
||||
}
|
||||
} else {
|
||||
logits_id.push_back(std::make_pair(plogits[i]*scale, i));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// find the top K tokens
|
||||
std::partial_sort(
|
||||
logits_id.begin(),
|
||||
logits_id.begin() + top_k, logits_id.end(),
|
||||
[](const std::pair<double, gpt_vocab::id> & a, const std::pair<double, gpt_vocab::id> & b) {
|
||||
return a.first > b.first;
|
||||
});
|
||||
|
||||
logits_id.resize(top_k);
|
||||
|
||||
double maxl = -INFINITY;
|
||||
for (const auto & kv : logits_id) {
|
||||
maxl = std::max(maxl, kv.first);
|
||||
}
|
||||
|
||||
// compute probs for the top K tokens
|
||||
std::vector<double> probs;
|
||||
probs.reserve(logits_id.size());
|
||||
|
||||
double sum = 0.0;
|
||||
for (const auto & kv : logits_id) {
|
||||
double p = exp(kv.first - maxl);
|
||||
probs.push_back(p);
|
||||
sum += p;
|
||||
}
|
||||
|
||||
// normalize the probs
|
||||
for (auto & p : probs) {
|
||||
p /= sum;
|
||||
}
|
||||
|
||||
if (top_p < 1.0f) {
|
||||
double cumsum = 0.0f;
|
||||
for (int i = 0; i < top_k; i++) {
|
||||
cumsum += probs[i];
|
||||
if (cumsum >= top_p) {
|
||||
top_k = i + 1;
|
||||
probs.resize(top_k);
|
||||
logits_id.resize(top_k);
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
cumsum = 1.0/cumsum;
|
||||
for (int i = 0; i < (int) probs.size(); i++) {
|
||||
probs[i] *= cumsum;
|
||||
}
|
||||
}
|
||||
|
||||
// printf("\n");
|
||||
// for (int i = 0; i < (int) probs.size(); i++) {
|
||||
// for (int i = 0; i < 10; i++) {
|
||||
// printf("%d: '%s' %f\n", i, vocab.id_to_token.at(logits_id[i].second).c_str(), probs[i]);
|
||||
// }
|
||||
|
||||
std::discrete_distribution<> dist(probs.begin(), probs.end());
|
||||
int idx = dist(rng);
|
||||
|
||||
return logits_id[idx].second;
|
||||
|
||||
}
|
||||
|
||||
bool read_wav(const std::string & fname, std::vector<float>& pcmf32, std::vector<std::vector<float>>& pcmf32s, bool stereo) {
|
||||
drwav wav;
|
||||
std::vector<uint8_t> wav_data; // used for pipe input from stdin
|
||||
|
||||
if (fname == "-") {
|
||||
{
|
||||
uint8_t buf[1024];
|
||||
while (true)
|
||||
{
|
||||
const size_t n = fread(buf, 1, sizeof(buf), stdin);
|
||||
if (n == 0) {
|
||||
break;
|
||||
}
|
||||
wav_data.insert(wav_data.end(), buf, buf + n);
|
||||
}
|
||||
}
|
||||
|
||||
if (drwav_init_memory(&wav, wav_data.data(), wav_data.size(), nullptr) == false) {
|
||||
fprintf(stderr, "error: failed to open WAV file from stdin\n");
|
||||
return false;
|
||||
}
|
||||
|
||||
fprintf(stderr, "%s: read %zu bytes from stdin\n", __func__, wav_data.size());
|
||||
}
|
||||
else if (drwav_init_file(&wav, fname.c_str(), nullptr) == false) {
|
||||
fprintf(stderr, "error: failed to open '%s' as WAV file\n", fname.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
if (wav.channels != 1 && wav.channels != 2) {
|
||||
fprintf(stderr, "%s: WAV file '%s' must be mono or stereo\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
if (stereo && wav.channels != 2) {
|
||||
fprintf(stderr, "%s: WAV file '%s' must be stereo for diarization\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
if (wav.sampleRate != COMMON_SAMPLE_RATE) {
|
||||
fprintf(stderr, "%s: WAV file '%s' must be %i kHz\n", __func__, fname.c_str(), COMMON_SAMPLE_RATE/1000);
|
||||
return false;
|
||||
}
|
||||
|
||||
if (wav.bitsPerSample != 16) {
|
||||
fprintf(stderr, "%s: WAV file '%s' must be 16-bit\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
const uint64_t n = wav_data.empty() ? wav.totalPCMFrameCount : wav_data.size()/(wav.channels*wav.bitsPerSample/8);
|
||||
|
||||
std::vector<int16_t> pcm16;
|
||||
pcm16.resize(n*wav.channels);
|
||||
drwav_read_pcm_frames_s16(&wav, n, pcm16.data());
|
||||
drwav_uninit(&wav);
|
||||
|
||||
// convert to mono, float
|
||||
pcmf32.resize(n);
|
||||
if (wav.channels == 1) {
|
||||
for (uint64_t i = 0; i < n; i++) {
|
||||
pcmf32[i] = float(pcm16[i])/32768.0f;
|
||||
}
|
||||
} else {
|
||||
for (uint64_t i = 0; i < n; i++) {
|
||||
pcmf32[i] = float(pcm16[2*i] + pcm16[2*i + 1])/65536.0f;
|
||||
}
|
||||
}
|
||||
|
||||
if (stereo) {
|
||||
// convert to stereo, float
|
||||
pcmf32s.resize(2);
|
||||
|
||||
pcmf32s[0].resize(n);
|
||||
pcmf32s[1].resize(n);
|
||||
for (uint64_t i = 0; i < n; i++) {
|
||||
pcmf32s[0][i] = float(pcm16[2*i])/32768.0f;
|
||||
pcmf32s[1][i] = float(pcm16[2*i + 1])/32768.0f;
|
||||
}
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
void high_pass_filter(std::vector<float> & data, float cutoff, float sample_rate) {
|
||||
const float rc = 1.0f / (2.0f * M_PI * cutoff);
|
||||
const float dt = 1.0f / sample_rate;
|
||||
const float alpha = dt / (rc + dt);
|
||||
|
||||
float y = data[0];
|
||||
|
||||
for (size_t i = 1; i < data.size(); i++) {
|
||||
y = alpha * (y + data[i] - data[i - 1]);
|
||||
data[i] = y;
|
||||
}
|
||||
}
|
||||
|
||||
bool vad_simple(std::vector<float> & pcmf32, int sample_rate, int last_ms, float vad_thold, float freq_thold, bool verbose) {
|
||||
const int n_samples = pcmf32.size();
|
||||
const int n_samples_last = (sample_rate * last_ms) / 1000;
|
||||
|
||||
if (n_samples_last >= n_samples) {
|
||||
// not enough samples - assume no speech
|
||||
return false;
|
||||
}
|
||||
|
||||
if (freq_thold > 0.0f) {
|
||||
high_pass_filter(pcmf32, freq_thold, sample_rate);
|
||||
}
|
||||
|
||||
float energy_all = 0.0f;
|
||||
float energy_last = 0.0f;
|
||||
|
||||
for (int i = 0; i < n_samples; i++) {
|
||||
energy_all += fabsf(pcmf32[i]);
|
||||
|
||||
if (i >= n_samples - n_samples_last) {
|
||||
energy_last += fabsf(pcmf32[i]);
|
||||
}
|
||||
}
|
||||
|
||||
energy_all /= n_samples;
|
||||
energy_last /= n_samples_last;
|
||||
|
||||
if (verbose) {
|
||||
fprintf(stderr, "%s: energy_all: %f, energy_last: %f, vad_thold: %f, freq_thold: %f\n", __func__, energy_all, energy_last, vad_thold, freq_thold);
|
||||
}
|
||||
|
||||
if (energy_last > vad_thold*energy_all) {
|
||||
return false;
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
float similarity(const std::string & s0, const std::string & s1) {
|
||||
const size_t len0 = s0.size() + 1;
|
||||
const size_t len1 = s1.size() + 1;
|
||||
|
||||
std::vector<int> col(len1, 0);
|
||||
std::vector<int> prevCol(len1, 0);
|
||||
|
||||
for (size_t i = 0; i < len1; i++) {
|
||||
prevCol[i] = i;
|
||||
}
|
||||
|
||||
for (size_t i = 0; i < len0; i++) {
|
||||
col[0] = i;
|
||||
for (size_t j = 1; j < len1; j++) {
|
||||
col[j] = std::min(std::min(1 + col[j - 1], 1 + prevCol[j]), prevCol[j - 1] + (i > 0 && s0[i - 1] == s1[j - 1] ? 0 : 1));
|
||||
}
|
||||
col.swap(prevCol);
|
||||
}
|
||||
|
||||
const float dist = prevCol[len1 - 1];
|
||||
|
||||
return 1.0f - (dist / std::max(s0.size(), s1.size()));
|
||||
}
|
||||
|
|
@ -0,0 +1,141 @@
|
|||
// Various helper functions and utilities
|
||||
|
||||
#pragma once
|
||||
|
||||
#include <string>
|
||||
#include <map>
|
||||
#include <vector>
|
||||
#include <random>
|
||||
#include <thread>
|
||||
|
||||
#define COMMON_SAMPLE_RATE 16000
|
||||
|
||||
//
|
||||
// CLI argument parsing
|
||||
//
|
||||
|
||||
struct gpt_params {
|
||||
int32_t seed = -1; // RNG seed
|
||||
int32_t n_threads = std::min(4, (int32_t) std::thread::hardware_concurrency());
|
||||
int32_t n_predict = 200; // new tokens to predict
|
||||
|
||||
// sampling parameters
|
||||
int32_t top_k = 40;
|
||||
float top_p = 0.9f;
|
||||
float temp = 0.9f;
|
||||
|
||||
int32_t n_batch = 8; // batch size for prompt processing
|
||||
|
||||
std::string model = "models/gpt-2-117M/ggml-model.bin"; // model path
|
||||
std::string prompt;
|
||||
};
|
||||
|
||||
bool gpt_params_parse(int argc, char ** argv, gpt_params & params);
|
||||
|
||||
void gpt_print_usage(int argc, char ** argv, const gpt_params & params);
|
||||
|
||||
std::string gpt_random_prompt(std::mt19937 & rng);
|
||||
|
||||
//
|
||||
// Vocab utils
|
||||
//
|
||||
|
||||
std::string trim(const std::string & s);
|
||||
|
||||
std::string replace(
|
||||
const std::string & s,
|
||||
const std::string & from,
|
||||
const std::string & to);
|
||||
|
||||
struct gpt_vocab {
|
||||
using id = int32_t;
|
||||
using token = std::string;
|
||||
|
||||
std::map<token, id> token_to_id;
|
||||
std::map<id, token> id_to_token;
|
||||
std::vector<std::string> special_tokens;
|
||||
|
||||
void add_special_token(const std::string & token);
|
||||
};
|
||||
|
||||
// poor-man's JSON parsing
|
||||
std::map<std::string, int32_t> json_parse(const std::string & fname);
|
||||
|
||||
std::string convert_to_utf8(const std::wstring & input);
|
||||
|
||||
std::wstring convert_to_wstring(const std::string & input);
|
||||
|
||||
// split text into tokens
|
||||
//
|
||||
// ref: https://github.com/openai/gpt-2/blob/a74da5d99abaaba920de8131d64da2862a8f213b/src/encoder.py#L53
|
||||
//
|
||||
// Regex (Python):
|
||||
// r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
|
||||
//
|
||||
// Regex (C++):
|
||||
// R"('s|'t|'re|'ve|'m|'ll|'d| ?[[:alpha:]]+| ?[[:digit:]]+| ?[^\s[:alpha:][:digit:]]+|\s+(?!\S)|\s+)"
|
||||
//
|
||||
std::vector<gpt_vocab::id> gpt_tokenize(const gpt_vocab & vocab, const std::string & text);
|
||||
|
||||
// load the tokens from encoder.json
|
||||
bool gpt_vocab_init(const std::string & fname, gpt_vocab & vocab);
|
||||
|
||||
// sample next token given probabilities for each embedding
|
||||
//
|
||||
// - consider only the top K tokens
|
||||
// - from them, consider only the top tokens with cumulative probability > P
|
||||
//
|
||||
// TODO: not sure if this implementation is correct
|
||||
// TODO: temperature is not implemented
|
||||
//
|
||||
gpt_vocab::id gpt_sample_top_k_top_p(
|
||||
const gpt_vocab & vocab,
|
||||
const float * logits,
|
||||
int top_k,
|
||||
double top_p,
|
||||
double temp,
|
||||
std::mt19937 & rng);
|
||||
|
||||
gpt_vocab::id gpt_sample_top_k_top_p_repeat(
|
||||
const gpt_vocab & vocab,
|
||||
const float * logits,
|
||||
const int32_t * last_n_tokens_data,
|
||||
size_t last_n_tokens_data_size,
|
||||
int top_k,
|
||||
double top_p,
|
||||
double temp,
|
||||
int repeat_last_n,
|
||||
float repeat_penalty,
|
||||
std::mt19937 & rng);
|
||||
|
||||
//
|
||||
// Audio utils
|
||||
//
|
||||
|
||||
// Read WAV audio file and store the PCM data into pcmf32
|
||||
// The sample rate of the audio must be equal to COMMON_SAMPLE_RATE
|
||||
// If stereo flag is set and the audio has 2 channels, the pcmf32s will contain 2 channel PCM
|
||||
bool read_wav(
|
||||
const std::string & fname,
|
||||
std::vector<float> & pcmf32,
|
||||
std::vector<std::vector<float>> & pcmf32s,
|
||||
bool stereo);
|
||||
|
||||
// Apply a high-pass frequency filter to PCM audio
|
||||
// Suppresses frequencies below cutoff Hz
|
||||
void high_pass_filter(
|
||||
std::vector<float> & data,
|
||||
float cutoff,
|
||||
float sample_rate);
|
||||
|
||||
// Basic voice activity detection (VAD) using audio energy adaptive threshold
|
||||
bool vad_simple(
|
||||
std::vector<float> & pcmf32,
|
||||
int sample_rate,
|
||||
int last_ms,
|
||||
float vad_thold,
|
||||
float freq_thold,
|
||||
bool verbose);
|
||||
|
||||
// compute similarity between two strings using Levenshtein distance
|
||||
float similarity(const std::string & s0, const std::string & s1);
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
#
|
||||
# dollyv2
|
||||
|
||||
set(TEST_TARGET dollyv2)
|
||||
add_executable(${TEST_TARGET} main.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
||||
#
|
||||
# dollyv2-quantize
|
||||
|
||||
set(TEST_TARGET dollyv2-quantize)
|
||||
add_executable(${TEST_TARGET} quantize.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
|
@ -0,0 +1,184 @@
|
|||
# Dolly-V2
|
||||
|
||||
Transformer architecture: GPT-NeoX
|
||||
|
||||
Modeled from examples/stablelm
|
||||
|
||||
Ref: https://github.com/databrickslabs/dolly
|
||||
|
||||
Ref: https://github.com/stability-AI/stableLM/#stablelm-alpha
|
||||
|
||||
## Usage
|
||||
|
||||
```bash
|
||||
# get the repo and build it
|
||||
git clone https://github.com/ggerganov/ggml
|
||||
cd ggml
|
||||
mkdir build && cd build
|
||||
cmake ..
|
||||
make -j
|
||||
|
||||
# get the Dolly-V2 3B model
|
||||
git clone https://huggingface.co/databricks/dolly-v2-3b
|
||||
|
||||
# convert model to FP16
|
||||
python3 ../examples/dolly-v2/convert-h5-to-ggml.py ./dolly-v2-3b/ 1
|
||||
|
||||
# run inference using FP16 precision
|
||||
./bin/dollyv2 -m ./dolly-v2-3b/ggml-model-f16.bin -p "State the meaning of life." -t 6 -n 64
|
||||
|
||||
main: seed = 1683218142
|
||||
dollyv2_model_load: loading model from './dolly-v2-3b/ggml-model-f16.bin' - please wait ...
|
||||
dollyv2_model_load: n_vocab = 50280
|
||||
dollyv2_model_load: n_ctx = 2048
|
||||
dollyv2_model_load: n_embd = 2560
|
||||
dollyv2_model_load: n_head = 32
|
||||
dollyv2_model_load: n_layer = 32
|
||||
dollyv2_model_load: n_rot = 20
|
||||
dollyv2_model_load: ftype = 1
|
||||
dollyv2_model_load: ggml ctx size = 7374.91 MB
|
||||
dollyv2_model_load: memory_size = 640.00 MB, n_mem = 65536
|
||||
dollyv2_model_load: ................................................ done
|
||||
dollyv2_model_load: model size = 5295.10 MB / num tensors = 388
|
||||
main: number of tokens in prompt = 32
|
||||
main: token[0] = 30003, Below
|
||||
main: token[1] = 310, is
|
||||
main: token[2] = 271, an
|
||||
main: token[3] = 9775, instruction
|
||||
main: token[4] = 326, that
|
||||
main: token[5] = 8631, describes
|
||||
main: token[6] = 247, a
|
||||
main: token[7] = 4836, task
|
||||
main: token[8] = 964, .
|
||||
main: token[9] = 19566, Write
|
||||
main: token[10] = 247, a
|
||||
main: token[11] = 2380, response
|
||||
main: token[12] = 326, that
|
||||
main: token[13] = 20420, appropriately
|
||||
main: token[14] = 29141, completes
|
||||
main: token[15] = 253, the
|
||||
main: token[16] = 2748, request
|
||||
main: token[17] = 964, .
|
||||
main: token[18] = 187,
|
||||
|
||||
main: token[19] = 187,
|
||||
|
||||
main: token[20] = 50278, ### Instruction:
|
||||
main: token[21] = 187,
|
||||
|
||||
main: token[22] = 5443, State
|
||||
main: token[23] = 253, the
|
||||
main: token[24] = 4495, meaning
|
||||
main: token[25] = 273, of
|
||||
main: token[26] = 1495, life
|
||||
main: token[27] = 964, .
|
||||
main: token[28] = 187,
|
||||
|
||||
main: token[29] = 187,
|
||||
|
||||
main: token[30] = 50279, ### Response:
|
||||
main: token[31] = 187,
|
||||
|
||||
|
||||
Below is an instruction that describes a task. Write a response that appropriately completes the request.
|
||||
|
||||
### Instruction:
|
||||
State the meaning of life.
|
||||
|
||||
### Response:
|
||||
The meaning of life is to love and be loved.
|
||||
|
||||
### End
|
||||
|
||||
main: mem per token = 16136720 bytes
|
||||
main: load time = 2202.58 ms
|
||||
main: sample time = 2.57 ms
|
||||
main: predict time = 1497.14 ms / 33.27 ms per token
|
||||
main: total time = 6187.27 ms
|
||||
```
|
||||
|
||||
## 5-bit integer quantization mode
|
||||
|
||||
```bash
|
||||
# quantize the model to 5-bits using Q5_0 quantization
|
||||
./bin/dollyv2-quantize ./dolly-v2-3b/ggml-model-f16.bin ./dolly-v2-3b/ggml-model-q5_0.bin q5_0
|
||||
|
||||
# run the quantized model
|
||||
./bin/dollyv2 -m ./dolly-v2-3b/ggml-model-q5_0.bin -p "State the meaning of life." -t 6 -n 64
|
||||
|
||||
main: seed = 1683218518
|
||||
dollyv2_model_load: loading model from './dolly-v2-3b/ggml-model-q5_0.bin' - please wait ...
|
||||
dollyv2_model_load: n_vocab = 50280
|
||||
dollyv2_model_load: n_ctx = 2048
|
||||
dollyv2_model_load: n_embd = 2560
|
||||
dollyv2_model_load: n_head = 32
|
||||
dollyv2_model_load: n_layer = 32
|
||||
dollyv2_model_load: n_rot = 20
|
||||
dollyv2_model_load: ftype = 8
|
||||
dollyv2_model_load: ggml ctx size = 3902.68 MB
|
||||
dollyv2_model_load: memory_size = 640.00 MB, n_mem = 65536
|
||||
dollyv2_model_load: ................................................ done
|
||||
dollyv2_model_load: model size = 1822.87 MB / num tensors = 388
|
||||
main: number of tokens in prompt = 32
|
||||
main: token[0] = 30003, Below
|
||||
main: token[1] = 310, is
|
||||
main: token[2] = 271, an
|
||||
main: token[3] = 9775, instruction
|
||||
main: token[4] = 326, that
|
||||
main: token[5] = 8631, describes
|
||||
main: token[6] = 247, a
|
||||
main: token[7] = 4836, task
|
||||
main: token[8] = 964, .
|
||||
main: token[9] = 19566, Write
|
||||
main: token[10] = 247, a
|
||||
main: token[11] = 2380, response
|
||||
main: token[12] = 326, that
|
||||
main: token[13] = 20420, appropriately
|
||||
main: token[14] = 29141, completes
|
||||
main: token[15] = 253, the
|
||||
main: token[16] = 2748, request
|
||||
main: token[17] = 964, .
|
||||
main: token[18] = 187,
|
||||
|
||||
main: token[19] = 187,
|
||||
|
||||
main: token[20] = 50278, ### Instruction:
|
||||
main: token[21] = 187,
|
||||
|
||||
main: token[22] = 5443, State
|
||||
main: token[23] = 253, the
|
||||
main: token[24] = 4495, meaning
|
||||
main: token[25] = 273, of
|
||||
main: token[26] = 1495, life
|
||||
main: token[27] = 964, .
|
||||
main: token[28] = 187,
|
||||
|
||||
main: token[29] = 187,
|
||||
|
||||
main: token[30] = 50279, ### Response:
|
||||
main: token[31] = 187,
|
||||
|
||||
|
||||
Below is an instruction that describes a task. Write a response that appropriately completes the request.
|
||||
|
||||
### Instruction:
|
||||
State the meaning of life.
|
||||
|
||||
### Response:
|
||||
The meaning of life is the discovery of the true self.
|
||||
|
||||
### End
|
||||
|
||||
main: mem per token = 16127760 bytes
|
||||
main: load time = 1011.09 ms
|
||||
main: sample time = 2.79 ms
|
||||
main: predict time = 1271.62 ms / 27.64 ms per token
|
||||
main: total time = 2802.51 ms
|
||||
```
|
||||
|
||||
## Notes
|
||||
|
||||
- No guarantees for correctness
|
||||
- The tokenizer is currently hacked - probably works only for English
|
||||
- Non-parallel residual is not supported
|
||||
- Contributions and improvements are welcome
|
||||
|
|
@ -0,0 +1,116 @@
|
|||
import sys
|
||||
import struct
|
||||
import json
|
||||
import numpy as np
|
||||
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
if len(sys.argv) < 3:
|
||||
print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n")
|
||||
print(" ftype == 0 -> float32")
|
||||
print(" ftype == 1 -> float16")
|
||||
sys.exit(1)
|
||||
|
||||
# output in the same directory as the model
|
||||
dir_model = sys.argv[1]
|
||||
fname_out = sys.argv[1] + "/ggml-model.bin"
|
||||
|
||||
with open(dir_model + "/tokenizer.json", "r", encoding="utf-8") as f:
|
||||
encoder = json.load(f)
|
||||
|
||||
with open(dir_model + "/config.json", "r", encoding="utf-8") as f:
|
||||
hparams = json.load(f)
|
||||
|
||||
# possible data types
|
||||
# ftype == 0 -> float32
|
||||
# ftype == 1 -> float16
|
||||
#
|
||||
# map from ftype to string
|
||||
ftype_str = ["f32", "f16"]
|
||||
|
||||
ftype = 1
|
||||
if len(sys.argv) > 2:
|
||||
ftype = int(sys.argv[2])
|
||||
if ftype < 0 or ftype > 1:
|
||||
print("Invalid ftype: " + str(ftype))
|
||||
sys.exit(1)
|
||||
fname_out = sys.argv[1] + "/ggml-model-" + ftype_str[ftype] + ".bin"
|
||||
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(dir_model)
|
||||
model = AutoModelForCausalLM.from_pretrained(dir_model, low_cpu_mem_usage=True)
|
||||
#print (model)
|
||||
|
||||
#print(tokenizer.encode('I believe the meaning of life is'))
|
||||
|
||||
list_vars = model.state_dict()
|
||||
for name in list_vars.keys():
|
||||
print(name, list_vars[name].shape, list_vars[name].dtype)
|
||||
|
||||
fout = open(fname_out, "wb")
|
||||
|
||||
print(hparams)
|
||||
|
||||
fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex
|
||||
fout.write(struct.pack("i", hparams["vocab_size"]))
|
||||
fout.write(struct.pack("i", hparams["max_position_embeddings"]))
|
||||
fout.write(struct.pack("i", hparams["hidden_size"]))
|
||||
fout.write(struct.pack("i", hparams["num_attention_heads"]))
|
||||
fout.write(struct.pack("i", hparams["num_hidden_layers"]))
|
||||
fout.write(struct.pack("i", int(hparams["rotary_pct"]*(hparams["hidden_size"]//hparams["num_attention_heads"]))))
|
||||
fout.write(struct.pack("i", hparams["use_parallel_residual"]))
|
||||
fout.write(struct.pack("i", ftype))
|
||||
|
||||
# TODO: temporary hack to not deal with implementing the tokenizer
|
||||
dot_token = tokenizer.encode('.')[0]
|
||||
for i in range(hparams["vocab_size"]):
|
||||
text = tokenizer.decode([dot_token, i]).encode('utf-8')
|
||||
# remove the first byte (it's always '.')
|
||||
text = text[1:]
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
|
||||
for name in list_vars.keys():
|
||||
data = list_vars[name].squeeze().numpy()
|
||||
print("Processing variable: " + name + " with shape: ", data.shape)
|
||||
|
||||
# we don't need these
|
||||
if name.endswith(".attention.masked_bias") or \
|
||||
name.endswith(".attention.bias") or \
|
||||
name.endswith(".attention.rotary_emb.inv_freq"):
|
||||
print(" Skipping variable: " + name)
|
||||
continue
|
||||
|
||||
n_dims = len(data.shape);
|
||||
|
||||
# ftype == 0 -> float32, ftype == 1 -> float16
|
||||
ftype_cur = 0;
|
||||
if ftype != 0:
|
||||
if name[-7:] == ".weight" and n_dims == 2:
|
||||
print(" Converting to float16")
|
||||
data = data.astype(np.float16)
|
||||
ftype_cur = 1
|
||||
else:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype_cur = 0
|
||||
else:
|
||||
if data.dtype != np.float32:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype_cur = 0
|
||||
|
||||
# header
|
||||
str = name.encode('utf-8')
|
||||
fout.write(struct.pack("iii", n_dims, len(str), ftype_cur))
|
||||
for i in range(n_dims):
|
||||
fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
|
||||
fout.write(str);
|
||||
|
||||
# data
|
||||
data.tofile(fout)
|
||||
|
||||
fout.close()
|
||||
|
||||
print("Done. Output file: " + fname_out)
|
||||
print("")
|
||||
|
|
@ -0,0 +1,813 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
#include "common-ggml.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <cinttypes>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
// default hparams (Dolly-V2 3B)
|
||||
struct dollyv2_hparams {
|
||||
int32_t n_vocab = 50254; // tokenizer.vocab_size
|
||||
int32_t n_ctx = 2048; // model.config.max_position_embeddings
|
||||
int32_t n_embd = 2560; // model.config.hidden_size
|
||||
int32_t n_head = 32; // model.config.num_attention_heads
|
||||
int32_t n_layer = 32; // model.config.num_hidden_layers
|
||||
int32_t n_rot = 20; // rotary_pct[25%] * (n_embd / n_head)
|
||||
int32_t par_res = 1; // 1 = true, 0 = false
|
||||
int32_t ftype = GGML_FTYPE_MOSTLY_F16;
|
||||
};
|
||||
|
||||
const std::string INSTRUCTION_KEY = "### Instruction:";
|
||||
const std::string RESPONSE_KEY = "### Response:";
|
||||
const std::string END_KEY = "### End";
|
||||
const std::string INTRO_BLURB = "Below is an instruction that describes a task. Write a response that appropriately completes the request.";
|
||||
|
||||
// dollyv2 prompt format
|
||||
std::string prompt_for_generation(const std::string& instruction) {
|
||||
return INTRO_BLURB + "\n\n" + INSTRUCTION_KEY + "\n" + instruction + "\n\n" + RESPONSE_KEY + "\n";
|
||||
}
|
||||
|
||||
struct dollyv2_layer {
|
||||
// pre normalization
|
||||
struct ggml_tensor * ln_1_g;
|
||||
struct ggml_tensor * ln_1_b;
|
||||
|
||||
// attention
|
||||
struct ggml_tensor * c_attn_attn_w;
|
||||
struct ggml_tensor * c_attn_attn_b;
|
||||
|
||||
struct ggml_tensor * c_attn_proj_w;
|
||||
struct ggml_tensor * c_attn_proj_b;
|
||||
|
||||
// post normalization
|
||||
struct ggml_tensor * ln_2_g;
|
||||
struct ggml_tensor * ln_2_b;
|
||||
|
||||
// ff
|
||||
struct ggml_tensor * c_mlp_fc_w;
|
||||
struct ggml_tensor * c_mlp_fc_b;
|
||||
|
||||
struct ggml_tensor * c_mlp_proj_w;
|
||||
struct ggml_tensor * c_mlp_proj_b;
|
||||
};
|
||||
|
||||
struct dollyv2_model {
|
||||
dollyv2_hparams hparams;
|
||||
|
||||
// normalization
|
||||
struct ggml_tensor * ln_f_g;
|
||||
struct ggml_tensor * ln_f_b;
|
||||
|
||||
struct ggml_tensor * wte; // position embedding
|
||||
|
||||
struct ggml_tensor * lmh_g; // language model head
|
||||
//struct ggml_tensor * lmh_b; // language model bias
|
||||
|
||||
std::vector<dollyv2_layer> layers;
|
||||
|
||||
// key + value memory
|
||||
struct ggml_tensor * memory_k;
|
||||
struct ggml_tensor * memory_v;
|
||||
|
||||
//
|
||||
struct ggml_context * ctx;
|
||||
std::map<std::string, struct ggml_tensor *> tensors;
|
||||
};
|
||||
|
||||
// load the model's weights from a file
|
||||
bool dollyv2_model_load(const std::string & fname, dollyv2_model & model, gpt_vocab & vocab) {
|
||||
printf("%s: loading model from '%s' - please wait ...\n", __func__, fname.c_str());
|
||||
|
||||
auto fin = std::ifstream(fname, std::ios::binary);
|
||||
if (!fin) {
|
||||
fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
fin.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// load hparams
|
||||
{
|
||||
auto & hparams = model.hparams;
|
||||
|
||||
fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
fin.read((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
fin.read((char *) &hparams.n_rot, sizeof(hparams.n_rot));
|
||||
fin.read((char *) &hparams.par_res, sizeof(hparams.par_res));
|
||||
fin.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx);
|
||||
printf("%s: n_embd = %d\n", __func__, hparams.n_embd);
|
||||
printf("%s: n_head = %d\n", __func__, hparams.n_head);
|
||||
printf("%s: n_layer = %d\n", __func__, hparams.n_layer);
|
||||
printf("%s: n_rot = %d\n", __func__, hparams.n_rot);
|
||||
printf("%s: par_res = %d\n", __func__, hparams.par_res);
|
||||
printf("%s: ftype = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr = %d\n", __func__, qntvr);
|
||||
|
||||
hparams.ftype %= GGML_QNT_VERSION_FACTOR;
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
const int32_t n_vocab = model.hparams.n_vocab;
|
||||
|
||||
std::string word;
|
||||
std::vector<char> buf(128);
|
||||
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
fin.read((char *) &len, sizeof(len));
|
||||
|
||||
buf.resize(len);
|
||||
fin.read((char *) buf.data(), len);
|
||||
word.assign(buf.data(), len);
|
||||
|
||||
vocab.token_to_id[word] = i;
|
||||
vocab.id_to_token[i] = word;
|
||||
}
|
||||
|
||||
vocab.add_special_token("### End");
|
||||
vocab.add_special_token("### Instruction:");
|
||||
vocab.add_special_token("### Response:");
|
||||
}
|
||||
|
||||
// for the big tensors, we have the option to store the data in 16-bit floats or quantized
|
||||
// in order to save memory and also to speed up the computation
|
||||
ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype));
|
||||
if (wtype == GGML_TYPE_COUNT) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n",
|
||||
__func__, fname.c_str(), model.hparams.ftype);
|
||||
return false;
|
||||
}
|
||||
|
||||
auto & ctx = model.ctx;
|
||||
|
||||
size_t ctx_size = 0;
|
||||
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
ctx_size += n_embd*ggml_type_sizef(GGML_TYPE_F32); // ln_f_g
|
||||
ctx_size += n_embd*ggml_type_sizef(GGML_TYPE_F32); // ln_f_b
|
||||
|
||||
ctx_size += n_embd*n_vocab*ggml_type_sizef(wtype); // wte
|
||||
|
||||
ctx_size += n_embd*n_vocab*ggml_type_sizef(wtype); // lmh_g
|
||||
//ctx_size += n_vocab*ggml_type_sizef(GGML_TYPE_F32); // lmh_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_1_g
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_1_b
|
||||
|
||||
ctx_size += n_layer*(3*n_embd*n_embd*ggml_type_sizef(wtype)); // c_attn_attn_w
|
||||
ctx_size += n_layer*( 3*n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_attn_attn_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*n_embd*ggml_type_sizef(wtype)); // c_attn_proj_w
|
||||
ctx_size += n_layer*(n_embd*n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_attn_proj_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_2_g
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_2_b
|
||||
|
||||
ctx_size += n_layer*(4*n_embd*n_embd*ggml_type_sizef(wtype)); // c_mlp_fc_w
|
||||
ctx_size += n_layer*( 4*n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_mlp_fc_b
|
||||
|
||||
ctx_size += n_layer*(4*n_embd*n_embd*ggml_type_sizef(wtype)); // c_mlp_proj_w
|
||||
ctx_size += n_layer*( n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_mlp_proj_b
|
||||
|
||||
ctx_size += n_ctx*n_layer*n_embd*ggml_type_sizef(GGML_TYPE_F32); // memory_k
|
||||
ctx_size += n_ctx*n_layer*n_embd*ggml_type_sizef(GGML_TYPE_F32); // memory_v
|
||||
|
||||
ctx_size += (6 + 16*n_layer)*512; // object overhead
|
||||
|
||||
printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0));
|
||||
}
|
||||
|
||||
// create the ggml context
|
||||
{
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = ctx_size,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
model.ctx = ggml_init(params);
|
||||
if (!model.ctx) {
|
||||
fprintf(stderr, "%s: ggml_init() failed\n", __func__);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// prepare memory for the weights
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
model.layers.resize(n_layer);
|
||||
|
||||
model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab);
|
||||
|
||||
model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
model.lmh_g = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab);
|
||||
//model.lmh_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_vocab);
|
||||
|
||||
// map by name
|
||||
model.tensors["gpt_neox.embed_in.weight"] = model.wte;
|
||||
|
||||
model.tensors["gpt_neox.final_layer_norm.weight"] = model.ln_f_g;
|
||||
model.tensors["gpt_neox.final_layer_norm.bias"] = model.ln_f_b;
|
||||
|
||||
model.tensors["embed_out.weight"] = model.lmh_g;
|
||||
//model.tensors["lm_head.bias"] = model.lmh_b;
|
||||
|
||||
for (int i = 0; i < n_layer; ++i) {
|
||||
auto & layer = model.layers[i];
|
||||
|
||||
layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.c_attn_attn_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 3*n_embd);
|
||||
layer.c_attn_attn_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 3*n_embd);
|
||||
|
||||
layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd);
|
||||
layer.c_attn_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.ln_2_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
layer.ln_2_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd);
|
||||
layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd);
|
||||
|
||||
layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd);
|
||||
layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
// map by name
|
||||
|
||||
// unmapped: attention.rotary_emb, mlp.act
|
||||
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".input_layernorm.weight"] = layer.ln_1_g;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".input_layernorm.bias"] = layer.ln_1_b;
|
||||
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.query_key_value.weight"] = layer.c_attn_attn_w;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.query_key_value.bias"] = layer.c_attn_attn_b;
|
||||
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.dense.weight"] = layer.c_attn_proj_w;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.dense.bias"] = layer.c_attn_proj_b;
|
||||
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".post_attention_layernorm.weight"] = layer.ln_2_g;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".post_attention_layernorm.bias"] = layer.ln_2_b;
|
||||
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_h_to_4h.weight"] = layer.c_mlp_fc_w;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_h_to_4h.bias"] = layer.c_mlp_fc_b;
|
||||
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_4h_to_h.weight"] = layer.c_mlp_proj_w;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_4h_to_h.bias"] = layer.c_mlp_proj_b;
|
||||
}
|
||||
}
|
||||
|
||||
// key + value memory
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
|
||||
const int64_t n_mem = n_layer*n_ctx;
|
||||
const int64_t n_elements = n_embd*n_mem;
|
||||
|
||||
model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements);
|
||||
model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements);
|
||||
|
||||
const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v);
|
||||
|
||||
printf("%s: memory_size = %8.2f MB, n_mem = %" PRId64 "\n", __func__, memory_size/1024.0/1024.0, n_mem);
|
||||
}
|
||||
|
||||
// load weights
|
||||
{
|
||||
int n_tensors = 0;
|
||||
size_t total_size = 0;
|
||||
|
||||
printf("%s: ", __func__);
|
||||
|
||||
while (true) {
|
||||
int32_t n_dims;
|
||||
int32_t length;
|
||||
int32_t ttype;
|
||||
|
||||
fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
|
||||
fin.read(reinterpret_cast<char *>(&length), sizeof(length));
|
||||
fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype));
|
||||
|
||||
if (fin.eof()) {
|
||||
break;
|
||||
}
|
||||
|
||||
int32_t nelements = 1;
|
||||
int32_t ne[2] = { 1, 1 };
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i]));
|
||||
nelements *= ne[i];
|
||||
}
|
||||
|
||||
std::string name(length, 0);
|
||||
fin.read(&name[0], length);
|
||||
|
||||
if (model.tensors.find(name.data()) == model.tensors.end()) {
|
||||
fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.data());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto tensor = model.tensors[name.data()];
|
||||
if (ggml_nelements(tensor) != nelements) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.data());
|
||||
return false;
|
||||
}
|
||||
|
||||
if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%5d, %5d], expected [%5d, %5d]\n",
|
||||
__func__, name.data(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]);
|
||||
return false;
|
||||
}
|
||||
|
||||
// for debugging
|
||||
if (0) {
|
||||
printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.data(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor));
|
||||
}
|
||||
|
||||
const size_t bpe = ggml_type_size(ggml_type(ttype));
|
||||
|
||||
if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n",
|
||||
__func__, name.data(), ggml_nbytes(tensor), nelements*bpe);
|
||||
return false;
|
||||
}
|
||||
|
||||
fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor));
|
||||
|
||||
total_size += ggml_nbytes(tensor);
|
||||
if (++n_tensors % 8 == 0) {
|
||||
printf(".");
|
||||
fflush(stdout);
|
||||
}
|
||||
}
|
||||
|
||||
printf(" done\n");
|
||||
|
||||
printf("%s: model size = %8.2f MB / num tensors = %d\n", __func__, total_size/1024.0/1024.0, n_tensors);
|
||||
}
|
||||
|
||||
fin.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// feed-forward network
|
||||
ggml_tensor * gpt_neox_ff(
|
||||
const dollyv2_layer &layer,
|
||||
ggml_context * ctx0,
|
||||
ggml_tensor * inp) {
|
||||
ggml_tensor * cur = ggml_norm(ctx0, inp);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, layer.ln_2_g, cur),
|
||||
cur),
|
||||
ggml_repeat(ctx0, layer.ln_2_b, cur));
|
||||
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
layer.c_mlp_fc_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, layer.c_mlp_fc_b, cur),
|
||||
cur);
|
||||
|
||||
// GELU activation
|
||||
cur = ggml_gelu(ctx0, cur);
|
||||
|
||||
// projection
|
||||
// cur = proj_w*cur + proj_b
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
layer.c_mlp_proj_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, layer.c_mlp_proj_b, cur),
|
||||
cur);
|
||||
return cur;
|
||||
}
|
||||
|
||||
// evaluate the transformer
|
||||
//
|
||||
// - model: the model
|
||||
// - n_threads: number of threads to use
|
||||
// - n_past: the context size so far
|
||||
// - embd_inp: the embeddings of the tokens in the context
|
||||
// - embd_w: the predicted logits for the next token
|
||||
//
|
||||
bool dollyv2_eval(
|
||||
const dollyv2_model & model,
|
||||
const int n_threads,
|
||||
const int n_past,
|
||||
const std::vector<gpt_vocab::id> & embd_inp,
|
||||
std::vector<float> & embd_w,
|
||||
size_t & mem_per_token) {
|
||||
const int N = embd_inp.size();
|
||||
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_head = hparams.n_head;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
const int n_rot = hparams.n_rot;
|
||||
|
||||
static size_t buf_size = 256u*1024*1024;
|
||||
static void * buf = malloc(buf_size);
|
||||
|
||||
if (mem_per_token > 0 && mem_per_token*N > buf_size) {
|
||||
const size_t buf_size_new = 1.1*(mem_per_token*N); // add 10% to account for ggml object overhead
|
||||
//printf("\n%s: reallocating buffer from %zu to %zu bytes\n", __func__, buf_size, buf_size_new);
|
||||
|
||||
// reallocate
|
||||
buf_size = buf_size_new;
|
||||
buf = realloc(buf, buf_size);
|
||||
if (buf == nullptr) {
|
||||
fprintf(stderr, "%s: failed to allocate %zu bytes\n", __func__, buf_size);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = buf_size,
|
||||
.mem_buffer = buf,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
struct ggml_cgraph gf = { };
|
||||
gf.n_threads = n_threads;
|
||||
|
||||
struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N);
|
||||
memcpy(embd->data, embd_inp.data(), N*ggml_element_size(embd));
|
||||
|
||||
// wte
|
||||
struct ggml_tensor * inpL = ggml_get_rows(ctx0, model.wte, embd);
|
||||
|
||||
for (int il = 0; il < n_layer; ++il) {
|
||||
struct ggml_tensor * cur;
|
||||
|
||||
// self-attention
|
||||
{
|
||||
{
|
||||
cur = ggml_norm(ctx0, inpL);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].ln_1_g, cur),
|
||||
cur),
|
||||
ggml_repeat(ctx0, model.layers[il].ln_1_b, cur));
|
||||
}
|
||||
|
||||
// compute QKV
|
||||
{
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_attn_attn_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_attn_attn_b, cur),
|
||||
cur);
|
||||
}
|
||||
|
||||
struct ggml_tensor * Qcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 0*sizeof(float)*n_embd/n_head));
|
||||
struct ggml_tensor * Kcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 1*sizeof(float)*n_embd/n_head));
|
||||
struct ggml_tensor * Vcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 2*sizeof(float)*n_embd/n_head));
|
||||
|
||||
// using mode = 2 for GPT-NeoX mode
|
||||
Qcur = ggml_rope_inplace(ctx0, Qcur, n_past, n_rot, 2);
|
||||
Kcur = ggml_rope_inplace(ctx0, Kcur, n_past, n_rot, 2);
|
||||
|
||||
// store key and value to memory
|
||||
{
|
||||
Vcur = ggml_transpose(ctx0, ggml_reshape_2d(ctx0, Vcur, n_embd, N));
|
||||
|
||||
struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past));
|
||||
struct ggml_tensor * v = ggml_view_2d(ctx0, model.memory_v, N, n_embd,
|
||||
( n_ctx)*ggml_element_size(model.memory_v),
|
||||
(il*n_ctx)*ggml_element_size(model.memory_v)*n_embd + n_past*ggml_element_size(model.memory_v));
|
||||
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Kcur, k));
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Vcur, v));
|
||||
}
|
||||
|
||||
// Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3)
|
||||
struct ggml_tensor * Q =
|
||||
ggml_permute(ctx0,
|
||||
Qcur,
|
||||
0, 2, 1, 3);
|
||||
|
||||
// K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3)
|
||||
struct ggml_tensor * K =
|
||||
ggml_permute(ctx0,
|
||||
ggml_reshape_3d(ctx0,
|
||||
ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd),
|
||||
n_embd/n_head, n_head, n_past + N),
|
||||
0, 2, 1, 3);
|
||||
|
||||
// K * Q
|
||||
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q);
|
||||
|
||||
// KQ_scaled = KQ / sqrt(n_embd/n_head)
|
||||
struct ggml_tensor * KQ_scaled =
|
||||
ggml_scale_inplace(ctx0,
|
||||
KQ,
|
||||
ggml_new_f32(ctx0, 1.0f/sqrt(float(n_embd)/n_head))
|
||||
);
|
||||
|
||||
// KQ_masked = mask_past(KQ_scaled)
|
||||
struct ggml_tensor * KQ_masked = ggml_diag_mask_inf_inplace(ctx0, KQ_scaled, n_past);
|
||||
|
||||
// KQ = soft_max(KQ_masked)
|
||||
struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked);
|
||||
|
||||
// V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous()
|
||||
struct ggml_tensor * V =
|
||||
ggml_view_3d(ctx0, model.memory_v,
|
||||
n_past + N, n_embd/n_head, n_head,
|
||||
n_ctx*ggml_element_size(model.memory_v),
|
||||
n_ctx*ggml_element_size(model.memory_v)*n_embd/n_head,
|
||||
il*n_ctx*ggml_element_size(model.memory_v)*n_embd);
|
||||
|
||||
// KQV = transpose(V) * KQ_soft_max
|
||||
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max);
|
||||
|
||||
// KQV_merged = KQV.permute(0, 2, 1, 3)
|
||||
struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3);
|
||||
|
||||
// cur = KQV_merged.contiguous().view(n_embd, N)
|
||||
cur = ggml_cpy(ctx0,
|
||||
KQV_merged,
|
||||
ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N));
|
||||
|
||||
// projection
|
||||
{
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_attn_proj_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0, ggml_repeat(ctx0, model.layers[il].c_attn_proj_b, cur), cur);
|
||||
}
|
||||
}
|
||||
|
||||
if (hparams.par_res == 0) {
|
||||
struct ggml_tensor * inpFF = ggml_add(ctx0, cur, inpL);
|
||||
|
||||
cur = gpt_neox_ff(model.layers[il], ctx0, inpFF);
|
||||
|
||||
// input for next layer
|
||||
inpL = ggml_add(ctx0, cur, inpFF);
|
||||
} else {
|
||||
struct ggml_tensor * inpFF = cur;
|
||||
|
||||
// this is independent of the self-attention result, so it could be done in parallel to the self-attention
|
||||
// note here we pass inpL instead of cur
|
||||
cur = gpt_neox_ff(model.layers[il], ctx0, inpL);
|
||||
|
||||
// layer input + FF
|
||||
cur = ggml_add(ctx0, cur, inpFF);
|
||||
|
||||
// input for next layer
|
||||
inpL = ggml_add(ctx0, cur, inpL);
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
// norm
|
||||
{
|
||||
inpL = ggml_norm(ctx0, inpL);
|
||||
|
||||
// inpL = ln_f_g*inpL + ln_f_b
|
||||
inpL = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.ln_f_g, inpL),
|
||||
inpL),
|
||||
ggml_repeat(ctx0, model.ln_f_b, inpL));
|
||||
}
|
||||
|
||||
// lm_head
|
||||
{
|
||||
inpL = ggml_mul_mat(ctx0, model.lmh_g, inpL);
|
||||
|
||||
//inpL = ggml_add(ctx0,
|
||||
// ggml_repeat(ctx0, model.lmh_b, inpL),
|
||||
// inpL);
|
||||
}
|
||||
|
||||
// logits -> probs
|
||||
//inpL = ggml_soft_max_inplace(ctx0, inpL);
|
||||
|
||||
// run the computation
|
||||
ggml_build_forward_expand(&gf, inpL);
|
||||
ggml_graph_compute (ctx0, &gf);
|
||||
|
||||
//if (n_past%100 == 0) {
|
||||
// ggml_graph_print (&gf);
|
||||
// ggml_graph_dump_dot(&gf, NULL, "gpt-2.dot");
|
||||
//}
|
||||
|
||||
//embd_w.resize(n_vocab*N);
|
||||
//memcpy(embd_w.data(), ggml_get_data(inpL), sizeof(float)*n_vocab*N);
|
||||
|
||||
// return result for just the last token
|
||||
embd_w.resize(n_vocab);
|
||||
memcpy(embd_w.data(), (float *) ggml_get_data(inpL) + (n_vocab*(N-1)), sizeof(float)*n_vocab);
|
||||
|
||||
if (mem_per_token == 0) {
|
||||
mem_per_token = ggml_used_mem(ctx0)/N;
|
||||
}
|
||||
//printf("used_mem = %zu\n", ggml_used_mem(ctx0));
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
int main(int argc, char ** argv) {
|
||||
ggml_time_init();
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
gpt_params params;
|
||||
params.model = "models/dolly-v2-3b/ggml-model-f16.bin";
|
||||
|
||||
if (gpt_params_parse(argc, argv, params) == false) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
if (params.seed < 0) {
|
||||
params.seed = time(NULL);
|
||||
}
|
||||
|
||||
printf("%s: seed = %d\n", __func__, params.seed);
|
||||
|
||||
std::mt19937 rng(params.seed);
|
||||
if (params.prompt.empty()) {
|
||||
params.prompt = gpt_random_prompt(rng);
|
||||
}
|
||||
|
||||
const std::string prompt = prompt_for_generation(params.prompt);
|
||||
|
||||
int64_t t_load_us = 0;
|
||||
|
||||
gpt_vocab vocab;
|
||||
dollyv2_model model;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!dollyv2_model_load(params.model, model, vocab)) {
|
||||
fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_load_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
int n_past = 0;
|
||||
|
||||
int64_t t_sample_us = 0;
|
||||
int64_t t_predict_us = 0;
|
||||
|
||||
std::vector<float> logits;
|
||||
|
||||
// tokenize the prompt
|
||||
std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, prompt);
|
||||
|
||||
params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size());
|
||||
|
||||
printf("%s: number of tokens in prompt = %zu\n", __func__, embd_inp.size());
|
||||
for (int i = 0; i < embd_inp.size(); i++) {
|
||||
printf("%s: token[%d] = %6d, %s\n", __func__, i, embd_inp[i], vocab.id_to_token.at(embd_inp[i]).c_str());
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
std::vector<gpt_vocab::id> embd;
|
||||
|
||||
// determine the required inference memory per token:
|
||||
size_t mem_per_token = 0;
|
||||
dollyv2_eval(model, params.n_threads, 0, { 0, 1, 2, 3 }, logits, mem_per_token);
|
||||
|
||||
const int32_t end_token = vocab.token_to_id["### End"];
|
||||
|
||||
for (int i = embd.size(); i < embd_inp.size() + params.n_predict; i++) {
|
||||
// predict
|
||||
if (embd.size() > 0) {
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!dollyv2_eval(model, params.n_threads, n_past, embd, logits, mem_per_token)) {
|
||||
printf("Failed to predict\n");
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_predict_us += ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
n_past += embd.size();
|
||||
embd.clear();
|
||||
|
||||
if (i >= embd_inp.size()) {
|
||||
// sample next token
|
||||
const int top_k = params.top_k;
|
||||
const float top_p = params.top_p;
|
||||
const float temp = params.temp;
|
||||
|
||||
const int n_vocab = model.hparams.n_vocab;
|
||||
|
||||
gpt_vocab::id id = 0;
|
||||
|
||||
{
|
||||
const int64_t t_start_sample_us = ggml_time_us();
|
||||
|
||||
id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng);
|
||||
|
||||
t_sample_us += ggml_time_us() - t_start_sample_us;
|
||||
}
|
||||
|
||||
// add it to the context
|
||||
embd.push_back(id);
|
||||
|
||||
} else {
|
||||
// if here, it means we are still processing the input prompt
|
||||
for (int k = i; k < embd_inp.size(); k++) {
|
||||
embd.push_back(embd_inp[k]);
|
||||
if (embd.size() > params.n_batch) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
i += embd.size() - 1;
|
||||
}
|
||||
|
||||
// display text
|
||||
for (auto id : embd) {
|
||||
printf("%s", vocab.id_to_token[id].c_str());
|
||||
}
|
||||
fflush(stdout);
|
||||
|
||||
// end of text token
|
||||
if (embd.back() == 0 || (end_token > 0 && embd.back() == end_token)) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n\n");
|
||||
printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token);
|
||||
printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f);
|
||||
printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f);
|
||||
printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us/1000.0f, t_predict_us/1000.0f/n_past);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f);
|
||||
}
|
||||
|
||||
ggml_free(model.ctx);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,178 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
#include "common-ggml.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <regex>
|
||||
|
||||
// default hparams (dollyv2 3B)
|
||||
struct dollyv2_hparams {
|
||||
int32_t n_vocab = 50254; // tokenizer.vocab_size
|
||||
int32_t n_ctx = 2048; // model.config.max_position_embeddings
|
||||
int32_t n_embd = 2560; // model.config.hidden_size
|
||||
int32_t n_head = 32; // model.config.num_attention_heads
|
||||
int32_t n_layer = 32; // model.config.num_hidden_layers
|
||||
int32_t n_rot = 20; // rotary_pct[25%] * (n_embd / n_head)
|
||||
int32_t par_res = 1; // 1 = true, 0 = false
|
||||
int32_t ftype = GGML_FTYPE_MOSTLY_F16;
|
||||
};
|
||||
|
||||
// quantize a model
|
||||
bool dollyv2_model_quantize(const std::string & fname_inp, const std::string & fname_out, ggml_ftype ftype) {
|
||||
gpt_vocab vocab;
|
||||
|
||||
printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str());
|
||||
|
||||
auto finp = std::ifstream(fname_inp, std::ios::binary);
|
||||
if (!finp) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto fout = std::ofstream(fname_out, std::ios::binary);
|
||||
if (!fout) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname_out.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
finp.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
fout.write((char *) &magic, sizeof(magic));
|
||||
}
|
||||
|
||||
dollyv2_hparams hparams;
|
||||
|
||||
// load hparams
|
||||
{
|
||||
finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
finp.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
finp.read((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
finp.read((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
finp.read((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
finp.read((char *) &hparams.n_rot, sizeof(hparams.n_rot));
|
||||
finp.read((char *) &hparams.par_res, sizeof(hparams.par_res));
|
||||
finp.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype;
|
||||
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx);
|
||||
printf("%s: n_embd = %d\n", __func__, hparams.n_embd);
|
||||
printf("%s: n_head = %d\n", __func__, hparams.n_head);
|
||||
printf("%s: n_layer = %d\n", __func__, hparams.n_layer);
|
||||
printf("%s: par_res = %d\n", __func__, hparams.par_res);
|
||||
printf("%s: ftype (src) = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr (src) = %d\n", __func__, qntvr_src);
|
||||
printf("%s: ftype (dst) = %d\n", __func__, ftype_dst);
|
||||
printf("%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION);
|
||||
|
||||
fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fout.write((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
fout.write((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
fout.write((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
fout.write((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
fout.write((char *) &hparams.n_rot, sizeof(hparams.n_rot));
|
||||
fout.write((char *) &hparams.par_res, sizeof(hparams.par_res));
|
||||
fout.write((char *) &ftype_dst, sizeof(ftype_dst));
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
const int32_t n_vocab = hparams.n_vocab;
|
||||
|
||||
std::string word;
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
finp.read ((char *) &len, sizeof(len));
|
||||
fout.write((char *) &len, sizeof(len));
|
||||
|
||||
word.resize(len);
|
||||
finp.read ((char *) word.data(), len);
|
||||
fout.write((char *) word.data(), len);
|
||||
|
||||
vocab.token_to_id[word] = i;
|
||||
vocab.id_to_token[i] = word;
|
||||
}
|
||||
}
|
||||
|
||||
// regexes of tensor names to be quantized
|
||||
const std::vector<std::string> to_quant = {
|
||||
".*weight",
|
||||
};
|
||||
|
||||
if (!ggml_common_quantize_0(finp, fout, ftype, to_quant, {})) {
|
||||
fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
finp.close();
|
||||
fout.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// usage:
|
||||
// ./dollyv2-quantize models/dolly-v2-3B/ggml-model.bin models/dolly-v2-3B/ggml-model-quant.bin type
|
||||
//
|
||||
int main(int argc, char ** argv) {
|
||||
if (argc != 4) {
|
||||
fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n", argv[0]);
|
||||
ggml_print_ftypes(stderr);
|
||||
return 1;
|
||||
}
|
||||
|
||||
// needed to initialize f16 tables
|
||||
{
|
||||
struct ggml_init_params params = { 0, NULL, false };
|
||||
struct ggml_context * ctx = ggml_init(params);
|
||||
ggml_free(ctx);
|
||||
}
|
||||
|
||||
const std::string fname_inp = argv[1];
|
||||
const std::string fname_out = argv[2];
|
||||
|
||||
const ggml_ftype ftype = ggml_parse_ftype(argv[3]);
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
int64_t t_quantize_us = 0;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!dollyv2_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) {
|
||||
fprintf(stderr, "%s: failed to quantize model from '%s'\n", __func__, fname_inp.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_quantize_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n");
|
||||
printf("%s: quantize time = %8.2f ms\n", __func__, t_quantize_us/1000.0f);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,13 @@
|
|||
#
|
||||
# gpt-2
|
||||
|
||||
set(TEST_TARGET gpt-2)
|
||||
add_executable(${TEST_TARGET} main.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
||||
#
|
||||
# gpt-2-quantize
|
||||
|
||||
set(TEST_TARGET gpt-2-quantize)
|
||||
add_executable(${TEST_TARGET} quantize.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
|
@ -0,0 +1,158 @@
|
|||
# gpt-2
|
||||
|
||||
This is a C++ example running GPT-2 inference using the [ggml](https://github.com/ggerganov/ggml) library.
|
||||
|
||||
The program runs on the CPU - no video card is required.
|
||||
|
||||
The [Cerebras-GPT](https://huggingface.co/cerebras) models are also supported.
|
||||
|
||||
The example supports the following GPT-2 models:
|
||||
|
||||
| Model | Description | Disk Size |
|
||||
| --- | --- | --- |
|
||||
| 117M | Small model | 240 MB |
|
||||
| 345M | Medium model | 680 MB |
|
||||
| 774M | Large model | 1.5 GB |
|
||||
| 1558M | XL model | 3.0 GB |
|
||||
|
||||
Sample performance on MacBook M1 Pro:
|
||||
|
||||
| Model | Size | Time / Token |
|
||||
| --- | --- | --- |
|
||||
| GPT-2 | 117M | 5 ms |
|
||||
| GPT-2 | 345M | 12 ms |
|
||||
| GPT-2 | 774M | 23 ms |
|
||||
| GPT-2 | 1558M | 42 ms |
|
||||
|
||||
*TODO: add tables for Cerebras-GPT models*
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
$ ./bin/gpt-2 -h
|
||||
usage: ./bin/gpt-2 [options]
|
||||
|
||||
options:
|
||||
-h, --help show this help message and exit
|
||||
-s SEED, --seed SEED RNG seed (default: -1)
|
||||
-t N, --threads N number of threads to use during computation (default: 8)
|
||||
-p PROMPT, --prompt PROMPT
|
||||
prompt to start generation with (default: random)
|
||||
-n N, --n_predict N number of tokens to predict (default: 200)
|
||||
--top_k N top-k sampling (default: 40)
|
||||
--top_p N top-p sampling (default: 0.9)
|
||||
--temp N temperature (default: 1.0)
|
||||
-b N, --batch_size N batch size for prompt processing (default: 8)
|
||||
-m FNAME, --model FNAME
|
||||
model path (default: models/gpt-2-117M/ggml-model.bin)
|
||||
|
||||
$ ./bin/gpt-2
|
||||
gpt2_model_load: loading model from 'models/gpt-2-117M/ggml-model.bin'
|
||||
gpt2_model_load: n_vocab = 50257
|
||||
gpt2_model_load: n_ctx = 1024
|
||||
gpt2_model_load: n_embd = 768
|
||||
gpt2_model_load: n_head = 12
|
||||
gpt2_model_load: n_layer = 12
|
||||
gpt2_model_load: f16 = 1
|
||||
gpt2_model_load: ggml ctx size = 311.12 MB
|
||||
gpt2_model_load: memory size = 72.00 MB, n_mem = 12288
|
||||
gpt2_model_load: model size = 239.08 MB
|
||||
main: number of tokens in prompt = 1
|
||||
|
||||
So this is going to be the end of the line for us.
|
||||
|
||||
If the Dolphins continue to do their business, it's possible that the team could make a bid to bring in new defensive coordinator Scott Linehan.
|
||||
|
||||
Linehan's job is a little daunting, but he's a great coach and an excellent coach. I don't believe we're going to make the playoffs.
|
||||
|
||||
We're going to have to work hard to keep our heads down and get ready to go.<|endoftext|>
|
||||
|
||||
main: mem per token = 2048612 bytes
|
||||
main: load time = 106.32 ms
|
||||
main: sample time = 7.10 ms
|
||||
main: predict time = 506.40 ms / 5.06 ms per token
|
||||
main: total time = 629.84 ms
|
||||
```
|
||||
|
||||
## Downloading and converting the original models (GPT-2)
|
||||
|
||||
You can download the original model files using the [download-model.sh](download-model.sh) Bash script. The models are
|
||||
in Tensorflow format, so in order to use them with ggml, you need to convert them to appropriate format. This is done
|
||||
via the [convert-ckpt-to-ggml.py](convert-ckpt-to-ggml.py) python script.
|
||||
|
||||
Here is the entire process for the GPT-2 117M model (download from official site + conversion):
|
||||
|
||||
```
|
||||
cd ggml/build
|
||||
../examples/gpt-2/download-model.sh 117M
|
||||
|
||||
Downloading model 117M ...
|
||||
models/gpt-2-117M/checkpoint 100%[=============================>] 77 --.-KB/s in 0s
|
||||
models/gpt-2-117M/encoder.json 100%[=============================>] 1018K 1.20MB/s in 0.8s
|
||||
models/gpt-2-117M/hparams.json 100%[=============================>] 90 --.-KB/s in 0s
|
||||
models/gpt-2-117M/model.ckpt.data-00000-of-00001 100%[=============================>] 474.70M 1.21MB/s in 8m 39s
|
||||
models/gpt-2-117M/model.ckpt.index 100%[=============================>] 5.09K --.-KB/s in 0s
|
||||
models/gpt-2-117M/model.ckpt.meta 100%[=============================>] 460.11K 806KB/s in 0.6s
|
||||
models/gpt-2-117M/vocab.bpe 100%[=============================>] 445.62K 799KB/s in 0.6s
|
||||
Done! Model '117M' saved in 'models/gpt-2-117M/'
|
||||
|
||||
Run the convert-ckpt-to-ggml.py script to convert the model to ggml format.
|
||||
|
||||
python /Users/john/ggml/examples/gpt-2/convert-ckpt-to-ggml.py models/gpt-2-117M/ 1
|
||||
|
||||
```
|
||||
|
||||
This conversion requires that you have python and Tensorflow installed on your computer. Still, if you want to avoid
|
||||
this, you can download the already converted ggml models as described below.
|
||||
|
||||
## Downloading and converting the original models (Cerebras-GPT)
|
||||
|
||||
Clone the respective repository from here: https://huggingface.co/cerebras
|
||||
|
||||
Use the [convert-cerebras-to-ggml.py](convert-cerebras-to-ggml.py) script to convert the model to `ggml` format:
|
||||
|
||||
```
|
||||
cd ggml/build
|
||||
git clone https://huggingface.co/cerebras/Cerebras-GPT-111M models/
|
||||
python ../examples/gpt-2/convert-cerebras-to-ggml.py models/Cerebras-GPT-111M/
|
||||
|
||||
```
|
||||
|
||||
## Downloading the ggml model directly (GPT-2)
|
||||
|
||||
For convenience, I will be hosting the converted ggml model files in order to make it easier to run the examples. This
|
||||
way, you can directly download a single binary file and start using it. No python or Tensorflow is required.
|
||||
|
||||
Here is how to get the 117M ggml model:
|
||||
|
||||
```
|
||||
cd ggml/build
|
||||
../examples/gpt-2/download-ggml-model.sh 117M
|
||||
|
||||
Downloading ggml model 117M ...
|
||||
models/gpt-2-117M/ggml-model.bin 100%[===============================>] 239.58M 8.52MB/s in 28s
|
||||
Done! Model '117M' saved in 'models/gpt-2-117M/ggml-model.bin'
|
||||
You can now use it like this:
|
||||
|
||||
$ ./bin/gpt-2 -m models/gpt-2-117M/ggml-model.bin -p "This is an example"
|
||||
|
||||
```
|
||||
|
||||
At some point, I might decide to stop hosting these models. So in that case, simply revert to the manual process above.
|
||||
|
||||
## Quantizing the models
|
||||
|
||||
You can also try to quantize the `ggml` models via 4-bit integer quantization.
|
||||
Keep in mind that for smaller models, this will render them completely useless.
|
||||
You generally want to quantize larger models.
|
||||
|
||||
```
|
||||
# quantize GPT-2 F16 to Q4_0 (faster but less precise)
|
||||
./bin/gpt-2-quantize models/gpt-2-1558M/ggml-model-f16.bin models/gpt-2-1558M/ggml-model-q4_0.bin 2
|
||||
./bin/gpt-2 -m models/gpt-2-1558M/ggml-model-q4_0.bin -p "This is an example"
|
||||
|
||||
# quantize Cerebras F16 to Q4_1 (slower but more precise)
|
||||
./bin/gpt-2-quantize models/Cerebras-GPT-6.7B/ggml-model-f16.bin models/Cerebras-GPT-6.7B/ggml-model-q4_1.bin 3
|
||||
./bin/gpt-2 -m models/Cerebras-GPT-6.7B/ggml-model-q4_1.bin -p "This is an example"
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,183 @@
|
|||
# Convert Cerebras models to ggml format
|
||||
#
|
||||
# ref: https://www.cerebras.net/blog/cerebras-gpt-a-family-of-open-compute-efficient-large-language-models/
|
||||
#
|
||||
|
||||
import sys
|
||||
import struct
|
||||
import json
|
||||
import torch
|
||||
import numpy as np
|
||||
import re
|
||||
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
# ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py
|
||||
def bytes_to_unicode():
|
||||
"""
|
||||
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
||||
The reversible bpe codes work on unicode strings.
|
||||
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
||||
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
||||
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
||||
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
||||
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
||||
"""
|
||||
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
|
||||
cs = bs[:]
|
||||
n = 0
|
||||
for b in range(2**8):
|
||||
if b not in bs:
|
||||
bs.append(b)
|
||||
cs.append(2**8+n)
|
||||
n += 1
|
||||
cs = [chr(n) for n in cs]
|
||||
return dict(zip(bs, cs))
|
||||
|
||||
if len(sys.argv) < 2:
|
||||
print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n")
|
||||
sys.exit(1)
|
||||
|
||||
# output in the same directory as the model
|
||||
dir_model = sys.argv[1]
|
||||
fname_out = sys.argv[1] + "/ggml-model-f16.bin"
|
||||
|
||||
with open(dir_model + "/vocab.json", "r", encoding="utf-8") as f:
|
||||
encoder = json.load(f)
|
||||
|
||||
with open(dir_model + "/config.json", "r", encoding="utf-8") as f:
|
||||
hparams = json.load(f)
|
||||
|
||||
# use 16-bit or 32-bit floats
|
||||
use_f16 = True
|
||||
if len(sys.argv) > 2:
|
||||
use_f16 = False
|
||||
fname_out = sys.argv[1] + "/ggml-model-f32.bin"
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(dir_model, low_cpu_mem_usage=True)
|
||||
#print (model)
|
||||
|
||||
list_vars = model.state_dict()
|
||||
#print (list_vars)
|
||||
|
||||
print(hparams)
|
||||
|
||||
fout = open(fname_out, "wb")
|
||||
|
||||
fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex
|
||||
fout.write(struct.pack("i", hparams["vocab_size"]))
|
||||
fout.write(struct.pack("i", hparams["n_positions"]))
|
||||
fout.write(struct.pack("i", hparams["n_embd"]))
|
||||
fout.write(struct.pack("i", hparams["n_head"]))
|
||||
fout.write(struct.pack("i", hparams["n_layer"]))
|
||||
fout.write(struct.pack("i", use_f16))
|
||||
|
||||
byte_encoder = bytes_to_unicode()
|
||||
byte_decoder = {v:k for k, v in byte_encoder.items()}
|
||||
|
||||
fout.write(struct.pack("i", len(encoder)))
|
||||
|
||||
for key in encoder:
|
||||
text = bytearray([byte_decoder[c] for c in key])
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
|
||||
for name in list_vars.keys():
|
||||
data = list_vars[name].squeeze().numpy()
|
||||
print("Processing variable: " + name + " with shape: ", data.shape)
|
||||
|
||||
# rename headers to keep compatibility
|
||||
if name == "transformer.ln_f.weight":
|
||||
name = "model/ln_f/g"
|
||||
elif name == "transformer.ln_f.bias":
|
||||
name = "model/ln_f/b"
|
||||
elif name == "transformer.wte.weight":
|
||||
name = "model/wte"
|
||||
elif name == "transformer.wpe.weight":
|
||||
name = "model/wpe"
|
||||
elif name == "lm_head.weight":
|
||||
name = "model/lm_head"
|
||||
elif re.match(r"transformer.h\.\d+\.ln_1\.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_1/g"
|
||||
elif re.match(r"transformer.h\.\d+\.ln_1\.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_1/b"
|
||||
elif re.match(r"transformer.h\.\d+\.attn\.c_attn\.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_attn/w"
|
||||
elif re.match(r"transformer.h\.\d+\.attn\.c_attn\.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_attn/b"
|
||||
elif re.match(r"transformer.h\.\d+\.attn\.c_proj\.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_proj/w"
|
||||
elif re.match(r"transformer.h.\d+.attn.c_proj.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_proj/b"
|
||||
elif re.match(r"transformer.h.\d+.ln_2.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_2/g"
|
||||
elif re.match(r"transformer.h.\d+.ln_2.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_2/b"
|
||||
elif re.match(r"transformer.h.\d+.mlp.c_fc.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_fc/w"
|
||||
elif re.match(r"transformer.h.\d+.mlp.c_fc.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_fc/b"
|
||||
elif re.match(r"transformer.h.\d+.mlp.c_proj.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_proj/w"
|
||||
elif re.match(r"transformer.h.\d+.mlp.c_proj.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_proj/b"
|
||||
else:
|
||||
print("Unrecognized variable name. %s", name)
|
||||
|
||||
# we don't need these
|
||||
if name.endswith("attn.masked_bias") or name.endswith(".attn.bias"):
|
||||
print(" Skipping variable: " + name)
|
||||
continue
|
||||
|
||||
n_dims = len(data.shape);
|
||||
|
||||
# ftype == 0 -> float32, ftype == 1 -> float16
|
||||
ftype = 0;
|
||||
if use_f16:
|
||||
if (name == "model/wte" or name == "model/lm_head" or name[-2:] == "/g" or name[-2:] == "/w") and n_dims == 2:
|
||||
print(" Converting to float16")
|
||||
data = data.astype(np.float16)
|
||||
ftype = 1
|
||||
else:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype = 0
|
||||
|
||||
# for efficiency - transpose the projection matrices
|
||||
# "model/h.*/attn/c_attn/w"
|
||||
# "model/h.*/attn/c_proj/w"
|
||||
# "model/h.*/mlp/c_fc/w"
|
||||
# "model/h.*/mlp/c_proj/w"
|
||||
if name[-14:] == "/attn/c_attn/w" or \
|
||||
name[-14:] == "/attn/c_proj/w" or \
|
||||
name[-11:] == "/mlp/c_fc/w" or \
|
||||
name[-13:] == "/mlp/c_proj/w":
|
||||
print(" Transposing")
|
||||
data = data.transpose()
|
||||
|
||||
# header
|
||||
str = name.encode('utf-8')
|
||||
fout.write(struct.pack("iii", n_dims, len(str), ftype))
|
||||
for i in range(n_dims):
|
||||
fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
|
||||
fout.write(str);
|
||||
|
||||
# data
|
||||
data.tofile(fout)
|
||||
|
||||
fout.close()
|
||||
|
||||
print("Done. Output file: " + fname_out)
|
||||
print("")
|
||||
|
|
@ -0,0 +1,159 @@
|
|||
# Convert a model checkpoint to a ggml compatible file
|
||||
#
|
||||
# Load the model using TensorFlow.
|
||||
# Iterate over all variables and write them to a binary file.
|
||||
#
|
||||
# For each variable, write the following:
|
||||
# - Number of dimensions (int)
|
||||
# - Name length (int)
|
||||
# - Dimensions (int[n_dims])
|
||||
# - Name (char[name_length])
|
||||
# - Data (float[n_dims])
|
||||
#
|
||||
# By default, the bigger matrices are converted to 16-bit floats.
|
||||
# This can be disabled by adding the "use-f32" CLI argument.
|
||||
#
|
||||
# At the start of the ggml file we write the model parameters
|
||||
# and vocabulary.
|
||||
#
|
||||
|
||||
import sys
|
||||
import json
|
||||
import struct
|
||||
import numpy as np
|
||||
import tensorflow as tf
|
||||
|
||||
# ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py
|
||||
def bytes_to_unicode():
|
||||
"""
|
||||
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
||||
The reversible bpe codes work on unicode strings.
|
||||
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
||||
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
||||
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
||||
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
||||
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
||||
"""
|
||||
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
|
||||
cs = bs[:]
|
||||
n = 0
|
||||
for b in range(2**8):
|
||||
if b not in bs:
|
||||
bs.append(b)
|
||||
cs.append(2**8+n)
|
||||
n += 1
|
||||
cs = [chr(n) for n in cs]
|
||||
return dict(zip(bs, cs))
|
||||
|
||||
# helper method to convert a numpy array to different float types
|
||||
def convert_to_ftype(data, ftype):
|
||||
# fp16
|
||||
if ftype == 1:
|
||||
return data.astype(np.float16)
|
||||
|
||||
assert False, "Invalid ftype: " + str(ftype)
|
||||
|
||||
if len(sys.argv) < 3:
|
||||
print("Usage: convert-ckpt-to-ggml.py dir-model ftype\n")
|
||||
print(" ftype == 0 -> float32")
|
||||
print(" ftype == 1 -> float16")
|
||||
sys.exit(1)
|
||||
|
||||
# output in the same directory as the model
|
||||
dir_model = sys.argv[1]
|
||||
fname_out = sys.argv[1] + "/ggml-model.bin"
|
||||
|
||||
with open(dir_model + "/encoder.json", "r", encoding="utf-8") as f:
|
||||
encoder = json.load(f)
|
||||
|
||||
with open(dir_model + "/hparams.json", "r", encoding="utf-8") as f:
|
||||
hparams = json.load(f)
|
||||
|
||||
# possible data types
|
||||
# ftype == 0 -> float32
|
||||
# ftype == 1 -> float16
|
||||
#
|
||||
# map from ftype to string
|
||||
ftype_str = ["f32", "f16"]
|
||||
|
||||
ftype = 1
|
||||
if len(sys.argv) > 2:
|
||||
ftype = int(sys.argv[2])
|
||||
if ftype < 0 or ftype > 1:
|
||||
print("Invalid ftype: " + str(ftype))
|
||||
sys.exit(1)
|
||||
fname_out = sys.argv[1] + "/ggml-model-" + ftype_str[ftype] + ".bin"
|
||||
|
||||
list_vars = tf.train.list_variables(dir_model)
|
||||
|
||||
fout = open(fname_out, "wb")
|
||||
|
||||
fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex
|
||||
fout.write(struct.pack("i", hparams["n_vocab"]))
|
||||
fout.write(struct.pack("i", hparams["n_ctx"]))
|
||||
fout.write(struct.pack("i", hparams["n_embd"]))
|
||||
fout.write(struct.pack("i", hparams["n_head"]))
|
||||
fout.write(struct.pack("i", hparams["n_layer"]))
|
||||
fout.write(struct.pack("i", ftype))
|
||||
|
||||
byte_encoder = bytes_to_unicode()
|
||||
byte_decoder = {v:k for k, v in byte_encoder.items()}
|
||||
|
||||
fout.write(struct.pack("i", len(encoder)))
|
||||
|
||||
for key in encoder:
|
||||
text = bytearray([byte_decoder[c] for c in key])
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
|
||||
for name, shape in list_vars:
|
||||
print("Processing variable: " + name + " with shape: ", shape)
|
||||
|
||||
data = tf.train.load_variable(dir_model, name).squeeze()
|
||||
n_dims = len(data.shape);
|
||||
|
||||
# for efficiency - transpose the projection matrices
|
||||
# "model/h.*/attn/c_attn/w"
|
||||
# "model/h.*/attn/c_proj/w"
|
||||
# "model/h.*/mlp/c_fc/w"
|
||||
# "model/h.*/mlp/c_proj/w"
|
||||
if name[-14:] == "/attn/c_attn/w" or \
|
||||
name[-14:] == "/attn/c_proj/w" or \
|
||||
name[-11:] == "/mlp/c_fc/w" or \
|
||||
name[-13:] == "/mlp/c_proj/w":
|
||||
print(" Transposing")
|
||||
data = data.transpose()
|
||||
|
||||
dshape = data.shape
|
||||
|
||||
ftype_cur = 0
|
||||
if ftype != 0:
|
||||
# match name:
|
||||
# "model/wte"
|
||||
# "model/h.*/attn/c_attn/w"
|
||||
# "model/h.*/attn/c_proj/w"
|
||||
# "model/h.*/mlp/c_fc/w"
|
||||
# "model/h.*/mlp/c_proj/w"
|
||||
if name == "model/wte" or name[-2:] == "/w":
|
||||
print(" Converting to " + ftype_str[ftype])
|
||||
data = convert_to_ftype(data, ftype)
|
||||
ftype_cur = ftype
|
||||
else:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype_cur = 0
|
||||
|
||||
# header
|
||||
str = name.encode('utf-8')
|
||||
fout.write(struct.pack("iii", n_dims, len(str), ftype_cur))
|
||||
for i in range(n_dims):
|
||||
fout.write(struct.pack("i", dshape[n_dims - 1 - i]))
|
||||
fout.write(str);
|
||||
|
||||
# data
|
||||
data.tofile(fout)
|
||||
|
||||
fout.close()
|
||||
|
||||
print("Done. Output file: " + fname_out)
|
||||
print("")
|
||||
|
|
@ -0,0 +1,195 @@
|
|||
# Convert GPT-2 h5 transformer model to ggml format
|
||||
#
|
||||
# Load the model using GPT2Model.
|
||||
# Iterate over all variables and write them to a binary file.
|
||||
#
|
||||
# For each variable, write the following:
|
||||
# - Number of dimensions (int)
|
||||
# - Name length (int)
|
||||
# - Dimensions (int[n_dims])
|
||||
# - Name (char[name_length])
|
||||
# - Data (float[n_dims])
|
||||
#
|
||||
# By default, the bigger matrices are converted to 16-bit floats.
|
||||
# This can be disabled by adding the "use-f32" CLI argument.
|
||||
#
|
||||
# At the start of the ggml file we write the model parameters
|
||||
# and vocabulary.
|
||||
#
|
||||
|
||||
import sys
|
||||
import struct
|
||||
import json
|
||||
import numpy as np
|
||||
import re
|
||||
|
||||
from transformers import GPT2Model
|
||||
|
||||
# ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py
|
||||
def bytes_to_unicode():
|
||||
"""
|
||||
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
||||
The reversible bpe codes work on unicode strings.
|
||||
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
||||
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
||||
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
||||
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
||||
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
||||
"""
|
||||
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
|
||||
cs = bs[:]
|
||||
n = 0
|
||||
for b in range(2**8):
|
||||
if b not in bs:
|
||||
bs.append(b)
|
||||
cs.append(2**8+n)
|
||||
n += 1
|
||||
cs = [chr(n) for n in cs]
|
||||
return dict(zip(bs, cs))
|
||||
|
||||
if len(sys.argv) < 2:
|
||||
print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n")
|
||||
sys.exit(1)
|
||||
|
||||
# output in the same directory as the model
|
||||
dir_model = sys.argv[1]
|
||||
fname_out = sys.argv[1] + "/ggml-model.bin"
|
||||
|
||||
with open(dir_model + "/vocab.json", "r", encoding="utf-8") as f:
|
||||
encoder = json.load(f)
|
||||
|
||||
with open(dir_model + "/added_tokens.json", "r", encoding="utf-8") as f:
|
||||
encoder_added = json.load(f)
|
||||
|
||||
with open(dir_model + "/config.json", "r", encoding="utf-8") as f:
|
||||
hparams = json.load(f)
|
||||
|
||||
# use 16-bit or 32-bit floats
|
||||
use_f16 = True
|
||||
if len(sys.argv) > 2:
|
||||
use_f16 = False
|
||||
fname_out = sys.argv[1] + "/ggml-model-f32.bin"
|
||||
|
||||
model = GPT2Model.from_pretrained(dir_model, low_cpu_mem_usage=True)
|
||||
#print (model)
|
||||
|
||||
list_vars = model.state_dict()
|
||||
#print (list_vars)
|
||||
|
||||
fout = open(fname_out, "wb")
|
||||
|
||||
fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex
|
||||
fout.write(struct.pack("i", hparams["vocab_size"]))
|
||||
fout.write(struct.pack("i", hparams["n_positions"]))
|
||||
fout.write(struct.pack("i", hparams["n_embd"]))
|
||||
fout.write(struct.pack("i", hparams["n_head"]))
|
||||
fout.write(struct.pack("i", hparams["n_layer"]))
|
||||
#fout.write(struct.pack("i", hparams["rotary_dim"]))
|
||||
fout.write(struct.pack("i", use_f16))
|
||||
|
||||
byte_encoder = bytes_to_unicode()
|
||||
byte_decoder = {v:k for k, v in byte_encoder.items()}
|
||||
|
||||
fout.write(struct.pack("i", len(encoder) + len(encoder_added)))
|
||||
|
||||
for key in encoder:
|
||||
text = bytearray([byte_decoder[c] for c in key])
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
|
||||
for key in encoder_added:
|
||||
text = bytearray([byte_decoder[c] for c in key])
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
|
||||
for name in list_vars.keys():
|
||||
data = list_vars[name].squeeze().numpy()
|
||||
print("Processing variable: " + name + " with shape: ", data.shape)
|
||||
|
||||
# we don't need these
|
||||
if name.endswith("attn.masked_bias") or name.endswith(".attn.bias"):
|
||||
print(" Skipping variable: " + name)
|
||||
continue
|
||||
|
||||
n_dims = len(data.shape);
|
||||
|
||||
# ftype == 0 -> float32, ftype == 1 -> float16
|
||||
ftype = 0;
|
||||
if use_f16:
|
||||
if name[-7:] == ".weight" and n_dims == 2:
|
||||
print(" Converting to float16")
|
||||
data = data.astype(np.float16)
|
||||
ftype = 1
|
||||
else:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype = 0
|
||||
|
||||
# for efficiency - transpose these matrices:
|
||||
# "transformer.h.*.mlp.c_proj.weight
|
||||
if name.endswith(".mlp.c_proj.weight"):
|
||||
print(" Transposing")
|
||||
data = data.transpose()
|
||||
|
||||
# rename headers to keep compatibility
|
||||
if name == "ln_f.weight":
|
||||
name = "model/ln_f/g"
|
||||
elif name == "ln_f.bias":
|
||||
name = "model/ln_f/b"
|
||||
elif name == "wte.weight":
|
||||
name = "model/wte"
|
||||
elif name == "wpe.weight":
|
||||
name = "model/wpe"
|
||||
elif re.match(r"h\.\d+\.ln_1\.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_1/g"
|
||||
elif re.match(r"h\.\d+\.ln_1\.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_1/b"
|
||||
elif re.match(r"h\.\d+\.attn\.c_attn\.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_attn/w"
|
||||
elif re.match(r"h\.\d+\.attn\.c_attn\.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_attn/b"
|
||||
elif re.match(r"h\.\d+\.attn\.c_proj\.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_proj/w"
|
||||
elif re.match(r"h.\d+.attn.c_proj.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_proj/b"
|
||||
elif re.match(r"h.\d+.ln_2.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_2/g"
|
||||
elif re.match(r"h.\d+.ln_2.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_2/b"
|
||||
elif re.match(r"h.\d+.mlp.c_fc.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_fc/w"
|
||||
elif re.match(r"h.\d+.mlp.c_fc.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_fc/b"
|
||||
elif re.match(r"h.\d+.mlp.c_proj.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_proj/w"
|
||||
elif re.match(r"h.\d+.mlp.c_proj.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_proj/b"
|
||||
else:
|
||||
print("Unrecognized variable name. %s", name)
|
||||
|
||||
str = name.encode('utf-8')
|
||||
|
||||
fout.write(struct.pack("iii", n_dims, len(str), ftype))
|
||||
for i in range(n_dims):
|
||||
fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
|
||||
fout.write(str);
|
||||
|
||||
# data
|
||||
data.tofile(fout)
|
||||
|
||||
fout.close()
|
||||
|
||||
print("Done. Output file: " + fname_out)
|
||||
print("")
|
||||
|
|
@ -0,0 +1,69 @@
|
|||
#!/bin/bash
|
||||
|
||||
# This script downloads GPT-2 model files that have already been converted to ggml format.
|
||||
# This way you don't have to convert them yourself.
|
||||
#
|
||||
# If you want to download the original GPT-2 model files, use the "download-model.sh" script instead.
|
||||
|
||||
#src="https://ggml.ggerganov.com"
|
||||
#pfx="ggml-model-gpt-2"
|
||||
|
||||
src="https://huggingface.co/ggerganov/ggml"
|
||||
pfx="resolve/main/ggml-model-gpt-2"
|
||||
|
||||
ggml_path=$(dirname $(realpath $0))
|
||||
|
||||
# GPT-2 models
|
||||
models=( "117M" "345M" "774M" "1558M" )
|
||||
|
||||
# list available models
|
||||
function list_models {
|
||||
printf "\n"
|
||||
printf " Available models:"
|
||||
for model in "${models[@]}"; do
|
||||
printf " $model"
|
||||
done
|
||||
printf "\n\n"
|
||||
}
|
||||
|
||||
if [ "$#" -ne 1 ]; then
|
||||
printf "Usage: $0 <model>\n"
|
||||
list_models
|
||||
|
||||
exit 1
|
||||
fi
|
||||
|
||||
model=$1
|
||||
|
||||
if [[ ! " ${models[@]} " =~ " ${model} " ]]; then
|
||||
printf "Invalid model: $model\n"
|
||||
list_models
|
||||
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# download ggml model
|
||||
|
||||
printf "Downloading ggml model $model ...\n"
|
||||
|
||||
mkdir -p models/gpt-2-$model
|
||||
|
||||
if [ -x "$(command -v wget)" ]; then
|
||||
wget --quiet --show-progress -O models/gpt-2-$model/ggml-model.bin $src/$pfx-$model.bin
|
||||
elif [ -x "$(command -v curl)" ]; then
|
||||
curl -L --output models/gpt-2-$model/ggml-model.bin $src/$pfx-$model.bin
|
||||
else
|
||||
printf "Either wget or curl is required to download models.\n"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ $? -ne 0 ]; then
|
||||
printf "Failed to download ggml model $model \n"
|
||||
printf "Please try again later or download the original GPT-2 model files and convert them yourself.\n"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
printf "Done! Model '$model' saved in 'models/gpt-2-$model/ggml-model.bin'\n"
|
||||
printf "You can now use it like this:\n\n"
|
||||
printf " $ ./bin/gpt-2 -m models/gpt-2-$model/ggml-model.bin -p \"This is an example\"\n"
|
||||
printf "\n"
|
||||
|
|
@ -0,0 +1,48 @@
|
|||
#!/bin/bash
|
||||
|
||||
ggml_path=$(dirname $(realpath $0))
|
||||
|
||||
# GPT-2 models
|
||||
models=( "117M" "345M" "774M" "1558M" )
|
||||
|
||||
# list available models
|
||||
function list_models {
|
||||
printf "\n"
|
||||
printf " Available models:"
|
||||
for model in "${models[@]}"; do
|
||||
printf " $model"
|
||||
done
|
||||
printf "\n\n"
|
||||
}
|
||||
|
||||
if [ "$#" -ne 1 ]; then
|
||||
printf "Usage: $0 <model>\n"
|
||||
list_models
|
||||
|
||||
exit 1
|
||||
fi
|
||||
|
||||
model=$1
|
||||
|
||||
if [[ ! " ${models[@]} " =~ " ${model} " ]]; then
|
||||
printf "Invalid model: $model\n"
|
||||
list_models
|
||||
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# download model
|
||||
|
||||
printf "Downloading model $model ...\n"
|
||||
|
||||
mkdir -p models/gpt-2-$model
|
||||
|
||||
for file in checkpoint encoder.json hparams.json model.ckpt.data-00000-of-00001 model.ckpt.index model.ckpt.meta vocab.bpe; do
|
||||
wget --quiet --show-progress -O models/gpt-2-$model/$file https://openaipublic.blob.core.windows.net/gpt-2/models/$model/$file
|
||||
done
|
||||
|
||||
printf "Done! Model '$model' saved in 'models/gpt-2-$model/'\n\n"
|
||||
printf "Run the convert-ckpt-to-ggml.py script to convert the model to ggml format.\n"
|
||||
printf "\n"
|
||||
printf " python $ggml_path/convert-ckpt-to-ggml.py models/gpt-2-$model/\n"
|
||||
printf "\n"
|
||||
|
|
@ -0,0 +1,838 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
#include "common-ggml.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
// default hparams (GPT-2 117M)
|
||||
struct gpt2_hparams {
|
||||
int32_t n_vocab = 50257;
|
||||
int32_t n_ctx = 1024;
|
||||
int32_t n_embd = 768;
|
||||
int32_t n_head = 12;
|
||||
int32_t n_layer = 12;
|
||||
int32_t ftype = 1;
|
||||
};
|
||||
|
||||
struct gpt2_layer {
|
||||
// normalization
|
||||
struct ggml_tensor * ln_1_g;
|
||||
struct ggml_tensor * ln_1_b;
|
||||
|
||||
struct ggml_tensor * ln_2_g;
|
||||
struct ggml_tensor * ln_2_b;
|
||||
|
||||
// attention
|
||||
struct ggml_tensor * c_attn_attn_w;
|
||||
struct ggml_tensor * c_attn_attn_b;
|
||||
|
||||
struct ggml_tensor * c_attn_proj_w;
|
||||
struct ggml_tensor * c_attn_proj_b;
|
||||
|
||||
// mlp
|
||||
struct ggml_tensor * c_mlp_fc_w;
|
||||
struct ggml_tensor * c_mlp_fc_b;
|
||||
|
||||
struct ggml_tensor * c_mlp_proj_w;
|
||||
struct ggml_tensor * c_mlp_proj_b;
|
||||
};
|
||||
|
||||
struct gpt2_model {
|
||||
gpt2_hparams hparams;
|
||||
|
||||
// normalization
|
||||
struct ggml_tensor * ln_f_g;
|
||||
struct ggml_tensor * ln_f_b;
|
||||
|
||||
struct ggml_tensor * wte; // position embedding
|
||||
struct ggml_tensor * wpe; // token embedding
|
||||
struct ggml_tensor * lm_head; // language model head
|
||||
|
||||
std::vector<gpt2_layer> layers;
|
||||
|
||||
// key + value memory
|
||||
struct ggml_tensor * memory_k;
|
||||
struct ggml_tensor * memory_v;
|
||||
|
||||
//
|
||||
struct ggml_context * ctx;
|
||||
std::map<std::string, struct ggml_tensor *> tensors;
|
||||
};
|
||||
|
||||
// load the model's weights from a file
|
||||
bool gpt2_model_load(const std::string & fname, gpt2_model & model, gpt_vocab & vocab) {
|
||||
printf("%s: loading model from '%s'\n", __func__, fname.c_str());
|
||||
|
||||
auto fin = std::ifstream(fname, std::ios::binary);
|
||||
if (!fin) {
|
||||
fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
fin.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// load hparams
|
||||
{
|
||||
auto & hparams = model.hparams;
|
||||
|
||||
fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
fin.read((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
fin.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx);
|
||||
printf("%s: n_embd = %d\n", __func__, hparams.n_embd);
|
||||
printf("%s: n_head = %d\n", __func__, hparams.n_head);
|
||||
printf("%s: n_layer = %d\n", __func__, hparams.n_layer);
|
||||
printf("%s: ftype = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr = %d\n", __func__, qntvr);
|
||||
|
||||
hparams.ftype %= GGML_QNT_VERSION_FACTOR;
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
int32_t n_vocab = 0;
|
||||
fin.read((char *) &n_vocab, sizeof(n_vocab));
|
||||
|
||||
if (n_vocab != model.hparams.n_vocab) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n",
|
||||
__func__, fname.c_str(), n_vocab, model.hparams.n_vocab);
|
||||
return false;
|
||||
}
|
||||
|
||||
std::string word;
|
||||
std::vector<char> buf(128);
|
||||
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
fin.read((char *) &len, sizeof(len));
|
||||
|
||||
buf.resize(len);
|
||||
fin.read((char *) buf.data(), len);
|
||||
word.assign(buf.data(), len);
|
||||
|
||||
vocab.token_to_id[word] = i;
|
||||
vocab.id_to_token[i] = word;
|
||||
}
|
||||
}
|
||||
|
||||
// for the big tensors, we have the option to store the data in 16-bit floats or quantized
|
||||
// in order to save memory and also to speed up the computation
|
||||
ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype));
|
||||
if (wtype == GGML_TYPE_COUNT) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n",
|
||||
__func__, fname.c_str(), model.hparams.ftype);
|
||||
return false;
|
||||
}
|
||||
|
||||
auto & ctx = model.ctx;
|
||||
|
||||
size_t ctx_size = 0;
|
||||
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
ctx_size += n_embd*ggml_type_sizef(GGML_TYPE_F32); // ln_f_g
|
||||
ctx_size += n_embd*ggml_type_sizef(GGML_TYPE_F32); // ln_f_b
|
||||
|
||||
ctx_size += n_vocab*n_embd*ggml_type_sizef(wtype); // wte
|
||||
ctx_size += n_ctx*n_embd*ggml_type_sizef(GGML_TYPE_F32); // wpe
|
||||
ctx_size += n_vocab*n_embd*ggml_type_sizef(wtype); // lm_head
|
||||
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_1_g
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_1_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_2_g
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_2_b
|
||||
|
||||
ctx_size += n_layer*(3*n_embd*n_embd*ggml_type_sizef(wtype)); // c_attn_attn_w
|
||||
ctx_size += n_layer*( 3*n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_attn_attn_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*n_embd*ggml_type_sizef(wtype)); // c_attn_proj_w
|
||||
ctx_size += n_layer*( n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_attn_proj_b
|
||||
|
||||
ctx_size += n_layer*(4*n_embd*n_embd*ggml_type_sizef(wtype)); // c_mlp_fc_w
|
||||
ctx_size += n_layer*( 4*n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_mlp_fc_b
|
||||
|
||||
ctx_size += n_layer*(4*n_embd*n_embd*ggml_type_sizef(wtype)); // c_mlp_proj_w
|
||||
ctx_size += n_layer*( n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_mlp_proj_b
|
||||
|
||||
ctx_size += n_ctx*n_layer*n_embd*ggml_type_sizef(GGML_TYPE_F32); // memory_k
|
||||
ctx_size += n_ctx*n_layer*n_embd*ggml_type_sizef(GGML_TYPE_F32); // memory_v
|
||||
|
||||
ctx_size += (6 + 12*n_layer)*512; // object overhead
|
||||
|
||||
printf("%s: ggml tensor size = %d bytes\n", __func__, (int) sizeof(ggml_tensor));
|
||||
printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0));
|
||||
}
|
||||
|
||||
// create the ggml context
|
||||
{
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = ctx_size,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
model.ctx = ggml_init(params);
|
||||
if (!model.ctx) {
|
||||
fprintf(stderr, "%s: ggml_init() failed\n", __func__);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// prepare memory for the weights
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
model.layers.resize(n_layer);
|
||||
|
||||
model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab);
|
||||
model.wpe = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_ctx);
|
||||
model.lm_head = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab);
|
||||
|
||||
// map by name
|
||||
model.tensors["model/ln_f/g"] = model.ln_f_g;
|
||||
model.tensors["model/ln_f/b"] = model.ln_f_b;
|
||||
|
||||
model.tensors["model/wte"] = model.wte;
|
||||
model.tensors["model/wpe"] = model.wpe;
|
||||
model.tensors["model/lm_head"] = model.lm_head;
|
||||
|
||||
for (int i = 0; i < n_layer; ++i) {
|
||||
auto & layer = model.layers[i];
|
||||
|
||||
layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.ln_2_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
layer.ln_2_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.c_attn_attn_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 3*n_embd);
|
||||
layer.c_attn_attn_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 3*n_embd);
|
||||
|
||||
layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd);
|
||||
layer.c_attn_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd);
|
||||
layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd);
|
||||
|
||||
layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd);
|
||||
layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
// map by name
|
||||
model.tensors["model/h" + std::to_string(i) + "/ln_1/g"] = layer.ln_1_g;
|
||||
model.tensors["model/h" + std::to_string(i) + "/ln_1/b"] = layer.ln_1_b;
|
||||
|
||||
model.tensors["model/h" + std::to_string(i) + "/ln_2/g"] = layer.ln_2_g;
|
||||
model.tensors["model/h" + std::to_string(i) + "/ln_2/b"] = layer.ln_2_b;
|
||||
|
||||
model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/w"] = layer.c_attn_attn_w;
|
||||
model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/b"] = layer.c_attn_attn_b;
|
||||
|
||||
model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/w"] = layer.c_attn_proj_w;
|
||||
model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/b"] = layer.c_attn_proj_b;
|
||||
|
||||
model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/w"] = layer.c_mlp_fc_w;
|
||||
model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/b"] = layer.c_mlp_fc_b;
|
||||
|
||||
model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/w"] = layer.c_mlp_proj_w;
|
||||
model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/b"] = layer.c_mlp_proj_b;
|
||||
}
|
||||
}
|
||||
|
||||
// key + value memory
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
|
||||
const int n_mem = n_layer*n_ctx;
|
||||
const int n_elements = n_embd*n_mem;
|
||||
|
||||
model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements);
|
||||
model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements);
|
||||
|
||||
const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v);
|
||||
|
||||
printf("%s: memory size = %8.2f MB, n_mem = %d\n", __func__, memory_size/1024.0/1024.0, n_mem);
|
||||
}
|
||||
|
||||
// load weights
|
||||
{
|
||||
size_t total_size = 0;
|
||||
|
||||
bool has_lm_head = false;
|
||||
|
||||
while (true) {
|
||||
int32_t n_dims;
|
||||
int32_t length;
|
||||
int32_t ttype;
|
||||
|
||||
fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
|
||||
fin.read(reinterpret_cast<char *>(&length), sizeof(length));
|
||||
fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype));
|
||||
|
||||
if (fin.eof()) {
|
||||
break;
|
||||
}
|
||||
|
||||
int32_t nelements = 1;
|
||||
int32_t ne[2] = { 1, 1 };
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i]));
|
||||
nelements *= ne[i];
|
||||
}
|
||||
|
||||
std::string name(length, 0);
|
||||
fin.read(&name[0], length);
|
||||
|
||||
if (model.tensors.find(name.data()) == model.tensors.end()) {
|
||||
fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.data());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto tensor = model.tensors[name.data()];
|
||||
if (ggml_nelements(tensor) != nelements) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.data());
|
||||
return false;
|
||||
}
|
||||
|
||||
if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%d, %d], expected [%d, %d]\n",
|
||||
__func__, name.data(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]);
|
||||
return false;
|
||||
}
|
||||
|
||||
// for debugging
|
||||
if (0) {
|
||||
printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.data(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor));
|
||||
}
|
||||
|
||||
const size_t bpe = ggml_type_size(ggml_type(ttype));
|
||||
|
||||
if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n",
|
||||
__func__, name.data(), ggml_nbytes(tensor), nelements*bpe);
|
||||
return false;
|
||||
}
|
||||
|
||||
fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor));
|
||||
|
||||
// GPT-2 models share the WTE tensor as the LM head
|
||||
if (name == "model/wte" && has_lm_head == false) {
|
||||
memcpy(model.lm_head->data, tensor->data, ggml_nbytes(tensor));
|
||||
}
|
||||
|
||||
if (name == "model/lm_head") {
|
||||
has_lm_head = true;
|
||||
}
|
||||
|
||||
total_size += ggml_nbytes(tensor);
|
||||
}
|
||||
|
||||
printf("%s: model size = %8.2f MB\n", __func__, total_size/1024.0/1024.0);
|
||||
}
|
||||
|
||||
fin.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// evaluate the transformer
|
||||
//
|
||||
// - model: the model
|
||||
// - n_threads: number of threads to use
|
||||
// - n_past: the context size so far
|
||||
// - embd_inp: the embeddings of the tokens in the context
|
||||
// - embd_w: the predicted logits for the next token
|
||||
//
|
||||
bool gpt2_eval(
|
||||
const gpt2_model & model,
|
||||
const int n_threads,
|
||||
const int n_past,
|
||||
const std::vector<gpt_vocab::id> & embd_inp,
|
||||
std::vector<float> & embd_w,
|
||||
size_t & mem_per_token) {
|
||||
const int N = embd_inp.size();
|
||||
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_head = hparams.n_head;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
static size_t buf_size = 256u*1024*1024;
|
||||
static void * buf = malloc(buf_size);
|
||||
|
||||
if (mem_per_token > 0 && mem_per_token*N > buf_size) {
|
||||
const size_t buf_size_new = 1.1*(mem_per_token*N); // add 10% to account for ggml object overhead
|
||||
//printf("\n%s: reallocating buffer from %zu to %zu bytes\n", __func__, buf_size, buf_size_new);
|
||||
|
||||
// reallocate
|
||||
buf_size = buf_size_new;
|
||||
buf = realloc(buf, buf_size);
|
||||
if (buf == nullptr) {
|
||||
fprintf(stderr, "%s: failed to allocate %zu bytes\n", __func__, buf_size);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = buf_size,
|
||||
.mem_buffer = buf,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
struct ggml_cgraph gf = {};
|
||||
gf.n_threads = n_threads;
|
||||
|
||||
struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N);
|
||||
memcpy(embd->data, embd_inp.data(), N*ggml_element_size(embd));
|
||||
|
||||
struct ggml_tensor * position = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N);
|
||||
for (int i = 0; i < N; ++i) {
|
||||
((int32_t *) position->data)[i] = n_past + i;
|
||||
}
|
||||
|
||||
// wte + wpe
|
||||
struct ggml_tensor * inpL =
|
||||
ggml_add(ctx0,
|
||||
ggml_get_rows(ctx0, model.wte, embd),
|
||||
ggml_get_rows(ctx0, model.wpe, position));
|
||||
|
||||
for (int il = 0; il < n_layer; ++il) {
|
||||
struct ggml_tensor * cur;
|
||||
|
||||
// norm
|
||||
{
|
||||
// [ 768, N]
|
||||
cur = ggml_norm(ctx0, inpL);
|
||||
|
||||
// cur = ln_1_g*cur + ln_1_b
|
||||
// [ 768, N]
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].ln_1_g, cur),
|
||||
cur),
|
||||
ggml_repeat(ctx0, model.layers[il].ln_1_b, cur));
|
||||
}
|
||||
|
||||
// attn
|
||||
// [2304, 768] - model.layers[il].c_attn_attn_w
|
||||
// [2304, 1] - model.layers[il].c_attn_attn_b
|
||||
// [ 768, N] - cur (in)
|
||||
// [2304, N] - cur (out)
|
||||
//
|
||||
// cur = attn_w*cur + attn_b
|
||||
// [2304, N]
|
||||
{
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_attn_attn_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_attn_attn_b, cur),
|
||||
cur);
|
||||
}
|
||||
|
||||
// self-attention
|
||||
{
|
||||
struct ggml_tensor * Qcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 0*sizeof(float)*n_embd);
|
||||
struct ggml_tensor * Kcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 1*sizeof(float)*n_embd);
|
||||
struct ggml_tensor * Vcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 2*sizeof(float)*n_embd);
|
||||
|
||||
// store key and value to memory
|
||||
if (N >= 1) {
|
||||
struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past));
|
||||
struct ggml_tensor * v = ggml_view_1d(ctx0, model.memory_v, N*n_embd, (ggml_element_size(model.memory_v)*n_embd)*(il*n_ctx + n_past));
|
||||
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Kcur, k));
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Vcur, v));
|
||||
}
|
||||
|
||||
// Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3)
|
||||
// [64, N, 12]
|
||||
struct ggml_tensor * Q =
|
||||
ggml_permute(ctx0,
|
||||
ggml_cpy(ctx0,
|
||||
Qcur,
|
||||
ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_embd/n_head, n_head, N)),
|
||||
0, 2, 1, 3);
|
||||
|
||||
// K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3)
|
||||
// [64, n_past + N, 12]
|
||||
struct ggml_tensor * K =
|
||||
ggml_permute(ctx0,
|
||||
ggml_reshape_3d(ctx0,
|
||||
ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd),
|
||||
n_embd/n_head, n_head, n_past + N),
|
||||
0, 2, 1, 3);
|
||||
|
||||
// GG: flash attention
|
||||
//struct ggml_tensor * V =
|
||||
// ggml_cpy(ctx0,
|
||||
// ggml_permute(ctx0,
|
||||
// ggml_reshape_3d(ctx0,
|
||||
// ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd),
|
||||
// n_embd/n_head, n_head, n_past + N),
|
||||
// 1, 2, 0, 3),
|
||||
// ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_past + N, n_embd/n_head, n_head));
|
||||
|
||||
//struct ggml_tensor * KQV = ggml_flash_attn(ctx0, Q, K, V, true);
|
||||
|
||||
// K * Q
|
||||
// [n_past + N, N, 12]
|
||||
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q);
|
||||
|
||||
// KQ_scaled = KQ / sqrt(n_embd/n_head)
|
||||
// [n_past + N, N, 12]
|
||||
struct ggml_tensor * KQ_scaled =
|
||||
ggml_scale_inplace(ctx0,
|
||||
KQ,
|
||||
ggml_new_f32(ctx0, 1.0f/sqrt(float(n_embd)/n_head))
|
||||
);
|
||||
|
||||
// KQ_masked = mask_past(KQ_scaled)
|
||||
// [n_past + N, N, 12]
|
||||
struct ggml_tensor * KQ_masked = ggml_diag_mask_inf_inplace(ctx0, KQ_scaled, n_past);
|
||||
|
||||
// KQ = soft_max(KQ_masked)
|
||||
// [n_past + N, N, 12]
|
||||
struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked);
|
||||
|
||||
// V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous()
|
||||
// [n_past + N, 64, 12]
|
||||
struct ggml_tensor * V_trans =
|
||||
ggml_cpy(ctx0,
|
||||
ggml_permute(ctx0,
|
||||
ggml_reshape_3d(ctx0,
|
||||
ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd),
|
||||
n_embd/n_head, n_head, n_past + N),
|
||||
1, 2, 0, 3),
|
||||
ggml_new_tensor_3d(ctx0, model.memory_v->type, n_past + N, n_embd/n_head, n_head));
|
||||
|
||||
// KQV = transpose(V) * KQ_soft_max
|
||||
// [64, N, 12]
|
||||
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V_trans, KQ_soft_max);
|
||||
|
||||
// KQV_merged = KQV.permute(0, 2, 1, 3)
|
||||
// [64, 12, N]
|
||||
struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3);
|
||||
|
||||
// cur = KQV_merged.contiguous().view(n_embd, N)
|
||||
// [768, N]
|
||||
cur = ggml_cpy(ctx0,
|
||||
KQV_merged,
|
||||
ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N));
|
||||
}
|
||||
|
||||
// projection
|
||||
// [ 768, 768] - model.layers[il].c_attn_proj_w
|
||||
// [ 768, 1] - model.layers[il].c_attn_proj_b
|
||||
// [ 768, N] - cur (in)
|
||||
// [ 768, N] - cur (out)
|
||||
//
|
||||
// cur = proj_w*cur + proj_b
|
||||
// [768, N]
|
||||
{
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_attn_proj_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_attn_proj_b, cur),
|
||||
cur);
|
||||
}
|
||||
|
||||
// add the input
|
||||
cur = ggml_add(ctx0, cur, inpL);
|
||||
|
||||
struct ggml_tensor * inpFF = cur;
|
||||
|
||||
// feed-forward network
|
||||
{
|
||||
// norm
|
||||
{
|
||||
cur = ggml_norm(ctx0, inpFF);
|
||||
|
||||
// cur = ln_2_g*cur + ln_2_b
|
||||
// [ 768, N]
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].ln_2_g, cur),
|
||||
cur),
|
||||
ggml_repeat(ctx0, model.layers[il].ln_2_b, cur));
|
||||
}
|
||||
|
||||
// fully connected
|
||||
// [3072, 768] - model.layers[il].c_mlp_fc_w
|
||||
// [3072, 1] - model.layers[il].c_mlp_fc_b
|
||||
// [ 768, N] - cur (in)
|
||||
// [3072, N] - cur (out)
|
||||
//
|
||||
// cur = fc_w*cur + fc_b
|
||||
// [3072, N]
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_mlp_fc_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_mlp_fc_b, cur),
|
||||
cur);
|
||||
|
||||
// GELU activation
|
||||
// [3072, N]
|
||||
cur = ggml_gelu(ctx0, cur);
|
||||
|
||||
// projection
|
||||
// [ 768, 3072] - model.layers[il].c_mlp_proj_w
|
||||
// [ 768, 1] - model.layers[il].c_mlp_proj_b
|
||||
// [3072, N] - cur (in)
|
||||
// [ 768, N] - cur (out)
|
||||
//
|
||||
// cur = proj_w*cur + proj_b
|
||||
// [768, N]
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_mlp_proj_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_mlp_proj_b, cur),
|
||||
cur);
|
||||
}
|
||||
|
||||
// input for next layer
|
||||
inpL = ggml_add(ctx0, cur, inpFF);
|
||||
}
|
||||
|
||||
// norm
|
||||
{
|
||||
// [ 768, N]
|
||||
inpL = ggml_norm(ctx0, inpL);
|
||||
|
||||
// inpL = ln_f_g*inpL + ln_f_b
|
||||
// [ 768, N]
|
||||
inpL = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.ln_f_g, inpL),
|
||||
inpL),
|
||||
ggml_repeat(ctx0, model.ln_f_b, inpL));
|
||||
}
|
||||
|
||||
// inpL = WTE * inpL
|
||||
// [ 768, 50257] - model.lm_head
|
||||
// [ 768, N] - inpL
|
||||
inpL = ggml_mul_mat(ctx0, model.lm_head, inpL);
|
||||
|
||||
// logits -> probs
|
||||
//inpL = ggml_soft_max_inplace(ctx0, inpL);
|
||||
|
||||
// run the computation
|
||||
ggml_build_forward_expand(&gf, inpL);
|
||||
ggml_graph_compute (ctx0, &gf);
|
||||
|
||||
//if (n_past%100 == 0) {
|
||||
// ggml_graph_print (&gf);
|
||||
// ggml_graph_dump_dot(&gf, NULL, "gpt-2.dot");
|
||||
//}
|
||||
|
||||
//embd_w.resize(n_vocab*N);
|
||||
//memcpy(embd_w.data(), ggml_get_data(inpL), sizeof(float)*n_vocab*N);
|
||||
|
||||
// return result just for the last token
|
||||
embd_w.resize(n_vocab);
|
||||
memcpy(embd_w.data(), (float *) ggml_get_data(inpL) + (n_vocab*(N-1)), sizeof(float)*n_vocab);
|
||||
|
||||
if (mem_per_token == 0) {
|
||||
mem_per_token = ggml_used_mem(ctx0)/N;
|
||||
}
|
||||
//printf("used_mem = %zu\n", ggml_used_mem(ctx0));
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
int main(int argc, char ** argv) {
|
||||
ggml_time_init();
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
gpt_params params;
|
||||
params.model = "models/gpt-2-117M/ggml-model.bin";
|
||||
|
||||
if (gpt_params_parse(argc, argv, params) == false) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
if (params.seed < 0) {
|
||||
params.seed = time(NULL);
|
||||
}
|
||||
|
||||
printf("%s: seed = %d\n", __func__, params.seed);
|
||||
|
||||
std::mt19937 rng(params.seed);
|
||||
if (params.prompt.empty()) {
|
||||
params.prompt = gpt_random_prompt(rng);
|
||||
}
|
||||
|
||||
int64_t t_load_us = 0;
|
||||
|
||||
gpt_vocab vocab;
|
||||
gpt2_model model;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!gpt2_model_load(params.model, model, vocab)) {
|
||||
fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_load_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
int n_past = 0;
|
||||
|
||||
int64_t t_sample_us = 0;
|
||||
int64_t t_predict_us = 0;
|
||||
|
||||
std::vector<float> logits;
|
||||
|
||||
// tokenize the prompt
|
||||
std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, params.prompt);
|
||||
|
||||
params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size());
|
||||
|
||||
printf("%s: prompt: '%s'\n", __func__, params.prompt.c_str());
|
||||
printf("%s: number of tokens in prompt = %zu, first 8 tokens: ", __func__, embd_inp.size());
|
||||
for (int i = 0; i < std::min(8, (int) embd_inp.size()); i++) {
|
||||
printf("%d ", embd_inp[i]);
|
||||
}
|
||||
printf("\n\n");
|
||||
|
||||
// submit the input prompt token-by-token
|
||||
// this reduces the memory usage during inference, at the cost of a bit of speed at the beginning
|
||||
std::vector<gpt_vocab::id> embd;
|
||||
|
||||
// determine the required inference memory per token:
|
||||
size_t mem_per_token = 0;
|
||||
gpt2_eval(model, params.n_threads, 0, { 0, 1, 2, 3 }, logits, mem_per_token);
|
||||
|
||||
for (int i = embd.size(); i < embd_inp.size() + params.n_predict; i++) {
|
||||
// predict
|
||||
if (embd.size() > 0) {
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!gpt2_eval(model, params.n_threads, n_past, embd, logits, mem_per_token)) {
|
||||
printf("Failed to predict\n");
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_predict_us += ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
n_past += embd.size();
|
||||
embd.clear();
|
||||
|
||||
if (i >= embd_inp.size()) {
|
||||
// sample next token
|
||||
const int top_k = params.top_k;
|
||||
const float top_p = params.top_p;
|
||||
const float temp = params.temp;
|
||||
|
||||
const int n_vocab = model.hparams.n_vocab;
|
||||
|
||||
gpt_vocab::id id = 0;
|
||||
|
||||
{
|
||||
const int64_t t_start_sample_us = ggml_time_us();
|
||||
|
||||
id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng);
|
||||
|
||||
t_sample_us += ggml_time_us() - t_start_sample_us;
|
||||
}
|
||||
|
||||
// add it to the context
|
||||
embd.push_back(id);
|
||||
} else {
|
||||
// if here, it means we are still processing the input prompt
|
||||
for (int k = i; k < embd_inp.size(); k++) {
|
||||
embd.push_back(embd_inp[k]);
|
||||
if (embd.size() >= params.n_batch) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
i += embd.size() - 1;
|
||||
}
|
||||
|
||||
// display text
|
||||
for (auto id : embd) {
|
||||
printf("%s", vocab.id_to_token[id].c_str());
|
||||
}
|
||||
fflush(stdout);
|
||||
|
||||
// end of text token
|
||||
if (embd.back() == 50256) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n\n");
|
||||
printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token);
|
||||
printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f);
|
||||
printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f);
|
||||
printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us/1000.0f, t_predict_us/1000.0f/n_past);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f);
|
||||
}
|
||||
|
||||
ggml_free(model.ctx);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,184 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
#include "common-ggml.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <regex>
|
||||
|
||||
// default hparams (GPT-2 117M)
|
||||
struct gpt2_hparams {
|
||||
int32_t n_vocab = 50257;
|
||||
int32_t n_ctx = 1024;
|
||||
int32_t n_embd = 768;
|
||||
int32_t n_head = 12;
|
||||
int32_t n_layer = 12;
|
||||
int32_t ftype = 1;
|
||||
};
|
||||
|
||||
// quantize a model
|
||||
bool gpt2_model_quantize(const std::string & fname_inp, const std::string & fname_out, ggml_ftype ftype) {
|
||||
gpt_vocab vocab;
|
||||
|
||||
printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str());
|
||||
|
||||
auto finp = std::ifstream(fname_inp, std::ios::binary);
|
||||
if (!finp) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto fout = std::ofstream(fname_out, std::ios::binary);
|
||||
if (!fout) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname_out.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
finp.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
fout.write((char *) &magic, sizeof(magic));
|
||||
}
|
||||
|
||||
gpt2_hparams hparams;
|
||||
|
||||
// load hparams
|
||||
{
|
||||
finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
finp.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
finp.read((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
finp.read((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
finp.read((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
finp.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype;
|
||||
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx);
|
||||
printf("%s: n_embd = %d\n", __func__, hparams.n_embd);
|
||||
printf("%s: n_head = %d\n", __func__, hparams.n_head);
|
||||
printf("%s: n_layer = %d\n", __func__, hparams.n_layer);
|
||||
printf("%s: ftype (src) = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr (src) = %d\n", __func__, qntvr_src);
|
||||
printf("%s: ftype (dst) = %d\n", __func__, ftype_dst);
|
||||
printf("%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION);
|
||||
|
||||
fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fout.write((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
fout.write((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
fout.write((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
fout.write((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
fout.write((char *) &ftype_dst, sizeof(ftype_dst));
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
int32_t n_vocab = 0;
|
||||
finp.read ((char *) &n_vocab, sizeof(n_vocab));
|
||||
fout.write((char *) &n_vocab, sizeof(n_vocab));
|
||||
|
||||
if (n_vocab != hparams.n_vocab) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n",
|
||||
__func__, fname_inp.c_str(), n_vocab, hparams.n_vocab);
|
||||
return false;
|
||||
}
|
||||
|
||||
std::string word;
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
finp.read ((char *) &len, sizeof(len));
|
||||
fout.write((char *) &len, sizeof(len));
|
||||
|
||||
word.resize(len);
|
||||
finp.read ((char *) word.data(), len);
|
||||
fout.write((char *) word.data(), len);
|
||||
|
||||
vocab.token_to_id[word] = i;
|
||||
vocab.id_to_token[i] = word;
|
||||
}
|
||||
}
|
||||
|
||||
// regexes of tensor names to be quantized
|
||||
const std::vector<std::string> to_quant = {
|
||||
"model/wte",
|
||||
"model/lm_head",
|
||||
"model/h.*/attn/c_attn/w",
|
||||
"model/h.*/attn/c_proj/w",
|
||||
"model/h.*/mlp/c_fc/w",
|
||||
"model/h.*/mlp/c_proj/w",
|
||||
};
|
||||
|
||||
if (!ggml_common_quantize_0(finp, fout, ftype, to_quant, {})) {
|
||||
fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
finp.close();
|
||||
fout.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// usage:
|
||||
// ./gpt-2-quantize models/gpt-2-117M/ggml-model.bin models/gpt-2-117M/ggml-model-quant.bin type
|
||||
//
|
||||
int main(int argc, char ** argv) {
|
||||
if (argc != 4) {
|
||||
fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n", argv[0]);
|
||||
ggml_print_ftypes(stderr);
|
||||
return 1;
|
||||
}
|
||||
|
||||
// needed to initialize f16 tables
|
||||
{
|
||||
struct ggml_init_params params = { 0, NULL, false };
|
||||
struct ggml_context * ctx = ggml_init(params);
|
||||
ggml_free(ctx);
|
||||
}
|
||||
|
||||
const std::string fname_inp = argv[1];
|
||||
const std::string fname_out = argv[2];
|
||||
|
||||
const ggml_ftype ftype = ggml_parse_ftype(argv[3]);
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
int64_t t_quantize_us = 0;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!gpt2_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) {
|
||||
fprintf(stderr, "%s: failed to quantize model from '%s'\n", __func__, fname_inp.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_quantize_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n");
|
||||
printf("%s: quantize time = %8.2f ms\n", __func__, t_quantize_us/1000.0f);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
#
|
||||
# gpt-j
|
||||
|
||||
set(TEST_TARGET gpt-j)
|
||||
add_executable(${TEST_TARGET} main.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
||||
#
|
||||
# gpt-j-quantize
|
||||
|
||||
set(TEST_TARGET gpt-j-quantize)
|
||||
add_executable(${TEST_TARGET} quantize.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
|
@ -0,0 +1,246 @@
|
|||
# gpt-j
|
||||
|
||||
Local GPT-J inference on your computer using C/C++
|
||||
|
||||
No video card required. You just need to have 16 GB of RAM.
|
||||
|
||||
## Motivation
|
||||
|
||||
The GPT-J 6B model is the open-source alternative to OpenAI's GPT-3. It's basically a neural network that allows you to
|
||||
generate coherent, human-like text given a certain context (prompt).
|
||||
|
||||
The GPT-J model is quite big - the compact version of the model uses 16-bit floating point representation of the weights
|
||||
and is still 12 GB big. This means that in order to run inference on your computer, you would need to have a video card
|
||||
with at least 12 GB of video RAM. Alternatively, you can try to run the python implementations on the CPU, but that
|
||||
would probably not be very efficient as they are primarily optimized for running on a GPU (or at least this is my guess -
|
||||
I don't have much experience with python).
|
||||
|
||||
I wanted to try and run the model on my MacBook, so I decided to implement the model inference from scratch using my own
|
||||
custom build tensor library. The tensor library (called [ggml](https://github.com/ggerganov/ggml), written in C) is in
|
||||
early development stage, but it already allows me to run the GPT-J model.
|
||||
|
||||
On my 32GB MacBook M1 Pro, I achieve an inference speed of about `125 ms/token` or about ~6 words per second (1 word
|
||||
typically consists of 1 or 2 tokens).
|
||||
|
||||
Here is a sample run with prompt `int main(int argc, char ** argv) {`:
|
||||
|
||||
```
|
||||
$ time ./bin/gpt-j -p "int main(int argc, char ** argv) {"
|
||||
|
||||
gptj_model_load: loading model from 'models/gpt-j-6B/ggml-model.bin' - please wait ...
|
||||
gptj_model_load: n_vocab = 50400
|
||||
gptj_model_load: n_ctx = 2048
|
||||
gptj_model_load: n_embd = 4096
|
||||
gptj_model_load: n_head = 16
|
||||
gptj_model_load: n_layer = 28
|
||||
gptj_model_load: n_rot = 64
|
||||
gptj_model_load: f16 = 1
|
||||
gptj_model_load: ggml ctx size = 13334.86 MB
|
||||
gptj_model_load: memory_size = 1792.00 MB, n_mem = 57344
|
||||
gptj_model_load: ................................... done
|
||||
gptj_model_load: model size = 11542.79 MB / num tensors = 285
|
||||
main: number of tokens in prompt = 13
|
||||
|
||||
int main(int argc, char ** argv) {
|
||||
(void)argc;
|
||||
(void)argv;
|
||||
|
||||
{
|
||||
struct sockaddr_in addr;
|
||||
int addrlen;
|
||||
char * ip = "192.168.1.4";
|
||||
int i;
|
||||
|
||||
if ( (addrlen = sizeof(addr)) == -1 )
|
||||
return -1;
|
||||
|
||||
for (i = 0; i < 10; ++i) {
|
||||
addr.sin_family = AF_INET;
|
||||
addr.sin_addr.s_addr = inet_addr(ip);
|
||||
|
||||
main: mem per token = 16430420 bytes
|
||||
main: load time = 6211.48 ms
|
||||
main: sample time = 13.74 ms
|
||||
main: predict time = 26420.34 ms / 124.62 ms per token
|
||||
main: total time = 33035.37 ms
|
||||
|
||||
real 0m33.171s
|
||||
user 3m32.269s
|
||||
sys 0m3.686s
|
||||
|
||||
$
|
||||
```
|
||||
|
||||
It took ~6.2 seconds to load the model to memory. After that, it took ~26.4 seconds to generate 200 tokens of what
|
||||
looks like to be the beginning of a networking program in C. Pretty cool!
|
||||
|
||||
Here is another run, just for fun:
|
||||
|
||||
```
|
||||
time ./bin/gpt-j -n 500 -t 8 -p "Ask HN: Inherited the worst code and tech team I have ever seen. How to fix it?
|
||||
"
|
||||
|
||||
gptj_model_load: loading model from 'models/gpt-j-6B/ggml-model.bin' - please wait ...
|
||||
gptj_model_load: n_vocab = 50400
|
||||
gptj_model_load: n_ctx = 2048
|
||||
gptj_model_load: n_embd = 4096
|
||||
gptj_model_load: n_head = 16
|
||||
gptj_model_load: n_layer = 28
|
||||
gptj_model_load: n_rot = 64
|
||||
gptj_model_load: f16 = 1
|
||||
gptj_model_load: ggml ctx size = 13334.86 MB
|
||||
gptj_model_load: memory_size = 1792.00 MB, n_mem = 57344
|
||||
gptj_model_load: ................................... done
|
||||
gptj_model_load: model size = 11542.79 MB / num tensors = 285
|
||||
main: number of tokens in prompt = 24
|
||||
|
||||
Ask HN: Inherited the worst code and tech team I have ever seen. How to fix it?
|
||||
|
||||
I've inherited a team with some very strange and un-documented practices, one of them is that they use an old custom
|
||||
application with a very slow tech stack written in Python that the team doesn't want to touch but also doesn't want to
|
||||
throw away as it has some "legacy" code in it.
|
||||
|
||||
The problem is, the tech stack is very very slow.
|
||||
|
||||
They have a single web server on a VM that is slow.
|
||||
The server is a little bit busy (not very busy though) and they have a lot of processes (30+ that are constantly being
|
||||
spawned by the application)
|
||||
They have an application that is single threaded and was written in Python and the team don't want to touch this, and
|
||||
the application is very slow.
|
||||
|
||||
My task as a new member of the team is to fix this.
|
||||
|
||||
I'm a senior dev on the team (3 years on the project) and have been told that I will take the lead on this task. I know
|
||||
next to nothing about Python. So here is what I have so far.
|
||||
|
||||
What I have done is I've been trying to debug the processes with the "ps" command. This way I can see what is running
|
||||
and where. From what I see, the application spawns 10 processes a minute and some of them are used for nothing.
|
||||
|
||||
I have also started to look for the code. The application source is not in GitHub or any other repository, it is only on
|
||||
our internal GitLab.
|
||||
|
||||
What I've found so far:
|
||||
|
||||
The application uses a custom SQLAlchemy implementation to interact with the data. I've looked at the source, it looks
|
||||
like an object cache or something like that. But from what I've seen, the cache gets full every 20 minutes and then gets
|
||||
cleared with a special command.
|
||||
|
||||
Another strange thing is that the application creates a file for every entry in the database (even if the entry already
|
||||
exists). I've looked at the file to see if it contains something, but it seems to be a JSON file with lots of records.
|
||||
|
||||
The other strange thing is that I can only find the database tables in the GitLab repository and not the code. So I
|
||||
can't really understand how the application is supposed to interact with the database.
|
||||
|
||||
I also found a "log" directory, but the code is encrypted with AES. From what I've found, it is in
|
||||
|
||||
main: mem per token = 16430420 bytes
|
||||
main: load time = 3900.10 ms
|
||||
main: sample time = 32.58 ms
|
||||
main: predict time = 68049.91 ms / 130.11 ms per token
|
||||
main: total time = 73020.05 ms
|
||||
|
||||
real 1m13.156s
|
||||
user 9m1.328s
|
||||
sys. 0m7.103s
|
||||
```
|
||||
|
||||
## Implementation details
|
||||
|
||||
The high level implementation of the model is contained in the [main.cpp](main.cpp) file. The core computations are
|
||||
performed by the [ggml](https://github.com/ggerganov/ggml/blob/master/include/ggml/ggml.h) library.
|
||||
|
||||
|
||||
#### Matrix multiplication
|
||||
|
||||
The most performance critical part of the implementation is of course the matrix multiplication routine. 99% of the time
|
||||
is spent here, so it was important to optimize this as much as possible.
|
||||
|
||||
On Arm64, I utilize the 128-bit NEON intrinsics for 16-bit floating point operations:
|
||||
|
||||
https://github.com/ggerganov/ggml/blob/fb558f78d905f85c54813602649ddd628ffe0f3a/src/ggml.c#L187-L243
|
||||
|
||||
These instructions allow each core to operate simultaneously on 64 16-bit floats. I'm no expert in SIMD, but after quite
|
||||
some trials this was the most efficient code for dot product of a row and column that I could come up with. Combined
|
||||
with the parallel computation on 8 CPU threads, I believe I'm close to the maximum performance that one could possibly
|
||||
get on the M1 CPU. Still, I'm curious to know if there is a more efficient way to implement this.
|
||||
|
||||
|
||||
#### Attempt to use the M1 GPU
|
||||
|
||||
One interesting property of the GPT-J transformer architecture is that it allows you to perform part of the inference in
|
||||
parallel - i.e. the Feed-forward network can be computed in parallel to the Self-attention layer:
|
||||
|
||||
https://github.com/ggerganov/ggml/blob/fb558f78d905f85c54813602649ddd628ffe0f3a/examples/gpt-j/main.cpp#L507-L531
|
||||
|
||||
So I thought why not try and bring in the M1 GPU to compute half of the neural network in parallel to the CPU and
|
||||
potentially gain some extra performance. Thanks to the M1's shared memory model, it was relatively easy to offload part
|
||||
of the computation to the GPU using Apple's [Metal Performance
|
||||
Shaders](https://developer.apple.com/documentation/metalperformanceshaders). The GPU shares the host memory, so there is
|
||||
no need to copy the data back and forth as you would normally do with Cuda or OpenCL. The weight matrices are directly
|
||||
available to be used by the GPU.
|
||||
|
||||
However, to my surprise, using MPS together with the CPU did not lead to any performance improvement at all. My
|
||||
conclusion was that the 8-thread NEON CPU computation is already saturating the memory bandwidth of the M1 and since
|
||||
the CPU and the GPU on the MacBook are sharing that bandwidth, it does not help to offload the computation to the GPU.
|
||||
Another observation was that the MPS GPU matrix multiplication using 16-bit floats had the same performance as the
|
||||
8-thread NEON CPU implementation. Again, I explain this with a saturated memory channel. But of course, my explanation
|
||||
could be totally wrong and somehow the implementation wasn't utilizing the resources correctly.
|
||||
|
||||
In the end, I decided to not use MPS or the GPU all together.
|
||||
|
||||
### Zero memory allocations
|
||||
|
||||
Another property of my implementation is that it does not perform any memory allocations once the model is loaded into
|
||||
memory. All required memory is allocated at the start of the program with a single `malloc` (technically 2 calls, but
|
||||
that is not important).
|
||||
|
||||
## Usage
|
||||
|
||||
If you want to give this a try and you are on Linux or Mac OS, simply follow these instructions:
|
||||
|
||||
```bash
|
||||
# Clone the ggml library and build the gpt-j example
|
||||
git clone https://github.com/ggerganov/ggml
|
||||
cd ggml
|
||||
mkdir build && cd build
|
||||
cmake ..
|
||||
make -j4 gpt-j
|
||||
|
||||
# Download the ggml-compatible GPT-J 6B model (requires 12GB disk space)
|
||||
../examples/gpt-j/download-ggml-model.sh 6B
|
||||
|
||||
# Run the inference (requires 16GB of CPU RAM)
|
||||
./bin/gpt-j -m models/gpt-j-6B/ggml-model.bin -p "This is an example"
|
||||
|
||||
# Input prompt through pipe and run the inference.
|
||||
echo "This is an example" > prompt.txt
|
||||
cat prompt.txt | ./bin/gpt-j -m models/gpt-j-6B/ggml-model.bin
|
||||
```
|
||||
|
||||
To run the `gpt-j` tool, you need the 12GB `ggml-model.bin` file which contains the GPT-J model in
|
||||
[ggml](https://github.com/ggerganov/ggml) compatible format. In the instructions above, the binary file
|
||||
is downloaded from my repository on Hugging Face using the [download-ggml-model.sh](download-ggml-model.sh) script.
|
||||
You can also, download the file manually from this link:
|
||||
|
||||
https://huggingface.co/ggerganov/ggml/tree/main
|
||||
|
||||
---
|
||||
|
||||
Alternatively, if you don't want to download the 12GB ggml model file, you can perform the conversion yourself using
|
||||
python.
|
||||
|
||||
First, you need to download the full GPT-J model from here: https://huggingface.co/EleutherAI/gpt-j-6B
|
||||
|
||||
Note that the full model is quite big - about 72 GB. After you download it, you need to convert it to ggml format using
|
||||
the [convert-h5-to-ggml.py](convert-h5-to-ggml.py) script. This will generate the `ggml-model.bin` file, which you can
|
||||
then use with the `gpt-j` program.
|
||||
|
||||
|
||||
## GPT-2
|
||||
|
||||
I also implemented a tool for CPU inference using the smaller GPT-2 models. They have worse quality compared to GPT-J,
|
||||
but are much faster to execute.
|
||||
|
||||
For example, the Small GPT-2 model is only 240 MB big and the inference speed on my MacBook is about 200 tokens/sec.
|
||||
|
||||
For more details, checkout the GPT-2 example here: [gpt-2](https://github.com/ggerganov/ggml/tree/master/examples/gpt-2)
|
||||
|
|
@ -0,0 +1,173 @@
|
|||
# Convert GPT-J-6B h5 transformer model to ggml format
|
||||
#
|
||||
# Load the model using GPTJForCausalLM.
|
||||
# Iterate over all variables and write them to a binary file.
|
||||
#
|
||||
# For each variable, write the following:
|
||||
# - Number of dimensions (int)
|
||||
# - Name length (int)
|
||||
# - Dimensions (int[n_dims])
|
||||
# - Name (char[name_length])
|
||||
# - Data (float[n_dims])
|
||||
#
|
||||
# By default, the bigger matrices are converted to 16-bit floats.
|
||||
# This can be disabled by adding the "use-f32" CLI argument.
|
||||
#
|
||||
# At the start of the ggml file we write the model parameters
|
||||
# and vocabulary.
|
||||
#
|
||||
|
||||
import sys
|
||||
import struct
|
||||
import json
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
from transformers import GPTJForCausalLM
|
||||
|
||||
# ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py
|
||||
def bytes_to_unicode():
|
||||
"""
|
||||
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
||||
The reversible bpe codes work on unicode strings.
|
||||
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
||||
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
||||
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
||||
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
||||
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
||||
"""
|
||||
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
|
||||
cs = bs[:]
|
||||
n = 0
|
||||
for b in range(2**8):
|
||||
if b not in bs:
|
||||
bs.append(b)
|
||||
cs.append(2**8+n)
|
||||
n += 1
|
||||
cs = [chr(n) for n in cs]
|
||||
return dict(zip(bs, cs))
|
||||
|
||||
if len(sys.argv) < 3:
|
||||
print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n")
|
||||
print(" ftype == 0 -> float32")
|
||||
print(" ftype == 1 -> float16")
|
||||
sys.exit(1)
|
||||
|
||||
# output in the same directory as the model
|
||||
dir_model = sys.argv[1]
|
||||
fname_out = sys.argv[1] + "/ggml-model.bin"
|
||||
|
||||
with open(dir_model + "/vocab.json", "r", encoding="utf-8") as f:
|
||||
encoder = json.load(f)
|
||||
|
||||
with open(dir_model + "/added_tokens.json", "r", encoding="utf-8") as f:
|
||||
encoder_added = json.load(f)
|
||||
|
||||
with open(dir_model + "/config.json", "r", encoding="utf-8") as f:
|
||||
hparams = json.load(f)
|
||||
|
||||
# possible data types
|
||||
# ftype == 0 -> float32
|
||||
# ftype == 1 -> float16
|
||||
#
|
||||
# map from ftype to string
|
||||
ftype_str = ["f32", "f16"]
|
||||
|
||||
ftype = 1
|
||||
if len(sys.argv) > 2:
|
||||
ftype = int(sys.argv[2])
|
||||
if ftype < 0 or ftype > 1:
|
||||
print("Invalid ftype: " + str(ftype))
|
||||
sys.exit(1)
|
||||
fname_out = sys.argv[1] + "/ggml-model-" + ftype_str[ftype] + ".bin"
|
||||
|
||||
|
||||
model = GPTJForCausalLM.from_pretrained(dir_model, low_cpu_mem_usage=True)
|
||||
#print (model)
|
||||
|
||||
list_vars = model.state_dict()
|
||||
#print (list_vars)
|
||||
|
||||
fout = open(fname_out, "wb")
|
||||
|
||||
fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex
|
||||
fout.write(struct.pack("i", hparams["vocab_size"]))
|
||||
fout.write(struct.pack("i", hparams["n_positions"]))
|
||||
fout.write(struct.pack("i", hparams["n_embd"]))
|
||||
fout.write(struct.pack("i", hparams["n_head"]))
|
||||
fout.write(struct.pack("i", hparams["n_layer"]))
|
||||
fout.write(struct.pack("i", hparams["rotary_dim"]))
|
||||
fout.write(struct.pack("i", ftype))
|
||||
|
||||
byte_encoder = bytes_to_unicode()
|
||||
byte_decoder = {v:k for k, v in byte_encoder.items()}
|
||||
|
||||
fout.write(struct.pack("i", len(encoder) + len(encoder_added)))
|
||||
|
||||
for key in encoder:
|
||||
text = bytearray([byte_decoder[c] for c in key])
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
|
||||
for key in encoder_added:
|
||||
text = bytearray([byte_decoder[c] for c in key])
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
|
||||
for name in list_vars.keys():
|
||||
data = list_vars[name].squeeze().numpy()
|
||||
print("Processing variable: " + name + " with shape: ", data.shape)
|
||||
|
||||
# we don't need these
|
||||
if name.endswith("attn.masked_bias") or name.endswith(".attn.bias"):
|
||||
print(" Skipping variable: " + name)
|
||||
continue
|
||||
|
||||
n_dims = len(data.shape);
|
||||
|
||||
# ftype == 0 -> float32, ftype == 1 -> float16
|
||||
ftype_cur = 0;
|
||||
if ftype != 0:
|
||||
if name[-7:] == ".weight" and n_dims == 2:
|
||||
print(" Converting to float16")
|
||||
data = data.astype(np.float16)
|
||||
ftype_cur = 1
|
||||
else:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype_cur = 0
|
||||
else:
|
||||
if data.dtype != np.float32:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype_cur = 0
|
||||
|
||||
# for efficiency - transpose these matrices:
|
||||
# (note - with latest ggml this is no longer more efficient, so disabling it)
|
||||
# "transformer.h.*.mlp.fc_in.weight"
|
||||
# "transformer.h.*.attn.out_proj.weight"
|
||||
# "transformer.h.*.attn.q_proj.weight"
|
||||
# "transformer.h.*.attn.k_proj.weight"
|
||||
# "transformer.h.*.attn.v_proj.weight"
|
||||
#if name.endswith(".mlp.fc_in.weight") or \
|
||||
# name.endswith(".attn.out_proj.weight") or \
|
||||
# name.endswith(".attn.q_proj.weight") or \
|
||||
# name.endswith(".attn.k_proj.weight") or \
|
||||
# name.endswith(".attn.v_proj.weight"):
|
||||
# print(" Transposing")
|
||||
# data = data.transpose()
|
||||
|
||||
# header
|
||||
str = name.encode('utf-8')
|
||||
fout.write(struct.pack("iii", n_dims, len(str), ftype_cur))
|
||||
for i in range(n_dims):
|
||||
fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
|
||||
fout.write(str);
|
||||
|
||||
# data
|
||||
data.tofile(fout)
|
||||
|
||||
fout.close()
|
||||
|
||||
print("Done. Output file: " + fname_out)
|
||||
print("")
|
||||
|
|
@ -0,0 +1,69 @@
|
|||
#!/bin/bash
|
||||
|
||||
# This script downloads GPT-J model files that have already been converted to ggml format.
|
||||
# This way you don't have to convert them yourself.
|
||||
#
|
||||
# If you want to download the original GPT-J model files, use the "download-model.sh" script instead.
|
||||
|
||||
#src="https://ggml.ggerganov.com"
|
||||
#pfx="ggml-model-gpt-j"
|
||||
|
||||
src="https://huggingface.co/ggerganov/ggml"
|
||||
pfx="resolve/main/ggml-model-gpt-j"
|
||||
|
||||
ggml_path=$(dirname $(realpath $0))
|
||||
|
||||
# GPT-J models
|
||||
models=( "6B" )
|
||||
|
||||
# list available models
|
||||
function list_models {
|
||||
printf "\n"
|
||||
printf " Available models:"
|
||||
for model in "${models[@]}"; do
|
||||
printf " $model"
|
||||
done
|
||||
printf "\n\n"
|
||||
}
|
||||
|
||||
if [ "$#" -ne 1 ]; then
|
||||
printf "Usage: $0 <model>\n"
|
||||
list_models
|
||||
|
||||
exit 1
|
||||
fi
|
||||
|
||||
model=$1
|
||||
|
||||
if [[ ! " ${models[@]} " =~ " ${model} " ]]; then
|
||||
printf "Invalid model: $model\n"
|
||||
list_models
|
||||
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# download ggml model
|
||||
|
||||
printf "Downloading ggml model $model ...\n"
|
||||
|
||||
mkdir -p models/gpt-j-$model
|
||||
|
||||
if [ -x "$(command -v wget)" ]; then
|
||||
wget --quiet --show-progress -O models/gpt-j-$model/ggml-model.bin $src/$pfx-$model.bin
|
||||
elif [ -x "$(command -v curl)" ]; then
|
||||
curl -L --output models/gpt-j-$model/ggml-model.bin $src/$pfx-$model.bin
|
||||
else
|
||||
printf "Either wget or curl is required to download models.\n"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ $? -ne 0 ]; then
|
||||
printf "Failed to download ggml model $model \n"
|
||||
printf "Please try again later or download the original GPT-J model files and convert them yourself.\n"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
printf "Done! Model '$model' saved in 'models/gpt-j-$model/ggml-model.bin'\n"
|
||||
printf "You can now use it like this:\n\n"
|
||||
printf " $ ./bin/gpt-j -m models/gpt-j-$model/ggml-model.bin -p \"This is an example\"\n"
|
||||
printf "\n"
|
||||
|
|
@ -0,0 +1,11 @@
|
|||
#!/bin/bash
|
||||
|
||||
printf "To obtain the GPT-J 6B model files, please visit: https://huggingface.co/EleutherAI/gpt-j-6B\n\n"
|
||||
|
||||
printf "The model is very big. For example, the reposirory above is 72GB in size.\n"
|
||||
printf "If you are sure that you want to clone it, simply run the following command:\n\n"
|
||||
|
||||
printf " $ git clone https://huggingface.co/EleutherAI/gpt-j-6B models/gpt-j-6B\n\n"
|
||||
|
||||
printf "Alternatively, use the 'download-ggml-model.sh' script to download a 12GB ggml version of the model.\n"
|
||||
printf "This version is enough to run inference using the ggml library.\n\n"
|
||||
|
|
@ -0,0 +1,741 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
#include "common-ggml.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
// default hparams (GPT-J 6B)
|
||||
struct gptj_hparams {
|
||||
int32_t n_vocab = 50400;
|
||||
int32_t n_ctx = 2048;
|
||||
int32_t n_embd = 4096;
|
||||
int32_t n_head = 16;
|
||||
int32_t n_layer = 28;
|
||||
int32_t n_rot = 64;
|
||||
int32_t ftype = 1;
|
||||
};
|
||||
|
||||
struct gptj_layer {
|
||||
// normalization
|
||||
struct ggml_tensor * ln_1_g;
|
||||
struct ggml_tensor * ln_1_b;
|
||||
|
||||
// attention
|
||||
struct ggml_tensor * c_attn_q_proj_w;
|
||||
struct ggml_tensor * c_attn_k_proj_w;
|
||||
struct ggml_tensor * c_attn_v_proj_w;
|
||||
|
||||
struct ggml_tensor * c_attn_proj_w;
|
||||
|
||||
// ff
|
||||
struct ggml_tensor * c_mlp_fc_w;
|
||||
struct ggml_tensor * c_mlp_fc_b;
|
||||
|
||||
struct ggml_tensor * c_mlp_proj_w;
|
||||
struct ggml_tensor * c_mlp_proj_b;
|
||||
};
|
||||
|
||||
struct gptj_model {
|
||||
gptj_hparams hparams;
|
||||
|
||||
// normalization
|
||||
struct ggml_tensor * ln_f_g;
|
||||
struct ggml_tensor * ln_f_b;
|
||||
|
||||
struct ggml_tensor * wte; // position embedding
|
||||
|
||||
struct ggml_tensor * lmh_g; // language model head
|
||||
struct ggml_tensor * lmh_b; // language model bias
|
||||
|
||||
std::vector<gptj_layer> layers;
|
||||
|
||||
// key + value memory
|
||||
struct ggml_tensor * memory_k;
|
||||
struct ggml_tensor * memory_v;
|
||||
|
||||
//
|
||||
struct ggml_context * ctx;
|
||||
std::map<std::string, struct ggml_tensor *> tensors;
|
||||
};
|
||||
|
||||
// load the model's weights from a file
|
||||
bool gptj_model_load(const std::string & fname, gptj_model & model, gpt_vocab & vocab) {
|
||||
printf("%s: loading model from '%s' - please wait ...\n", __func__, fname.c_str());
|
||||
|
||||
auto fin = std::ifstream(fname, std::ios::binary);
|
||||
if (!fin) {
|
||||
fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
fin.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// load hparams
|
||||
{
|
||||
auto & hparams = model.hparams;
|
||||
|
||||
fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
fin.read((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
fin.read((char *) &hparams.n_rot, sizeof(hparams.n_rot));
|
||||
fin.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx);
|
||||
printf("%s: n_embd = %d\n", __func__, hparams.n_embd);
|
||||
printf("%s: n_head = %d\n", __func__, hparams.n_head);
|
||||
printf("%s: n_layer = %d\n", __func__, hparams.n_layer);
|
||||
printf("%s: n_rot = %d\n", __func__, hparams.n_rot);
|
||||
printf("%s: ftype = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr = %d\n", __func__, qntvr);
|
||||
|
||||
hparams.ftype %= GGML_QNT_VERSION_FACTOR;
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
int32_t n_vocab = 0;
|
||||
fin.read((char *) &n_vocab, sizeof(n_vocab));
|
||||
|
||||
if (n_vocab != model.hparams.n_vocab) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n",
|
||||
__func__, fname.c_str(), n_vocab, model.hparams.n_vocab);
|
||||
return false;
|
||||
}
|
||||
|
||||
std::string word;
|
||||
std::vector<char> buf(128);
|
||||
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
fin.read((char *) &len, sizeof(len));
|
||||
|
||||
buf.resize(len);
|
||||
fin.read((char *) buf.data(), len);
|
||||
word.assign(buf.data(), len);
|
||||
|
||||
vocab.token_to_id[word] = i;
|
||||
vocab.id_to_token[i] = word;
|
||||
}
|
||||
}
|
||||
|
||||
// for the big tensors, we have the option to store the data in 16-bit floats or quantized
|
||||
// in order to save memory and also to speed up the computation
|
||||
ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype));
|
||||
if (wtype == GGML_TYPE_COUNT) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n",
|
||||
__func__, fname.c_str(), model.hparams.ftype);
|
||||
return false;
|
||||
}
|
||||
|
||||
auto & ctx = model.ctx;
|
||||
|
||||
size_t ctx_size = 0;
|
||||
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
ctx_size += n_embd*ggml_type_sizef(GGML_TYPE_F32); // ln_f_g
|
||||
ctx_size += n_embd*ggml_type_sizef(GGML_TYPE_F32); // ln_f_b
|
||||
|
||||
ctx_size += n_embd*n_vocab*ggml_type_sizef(wtype); // wte
|
||||
|
||||
ctx_size += n_embd*n_vocab*ggml_type_sizef(wtype); // lmh_g
|
||||
ctx_size += n_vocab*ggml_type_sizef(GGML_TYPE_F32); // lmh_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_1_g
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_1_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*n_embd*ggml_type_sizef(wtype)); // c_attn_q_proj_w
|
||||
ctx_size += n_layer*(n_embd*n_embd*ggml_type_sizef(wtype)); // c_attn_k_proj_w
|
||||
ctx_size += n_layer*(n_embd*n_embd*ggml_type_sizef(wtype)); // c_attn_v_proj_w
|
||||
|
||||
ctx_size += n_layer*(n_embd*n_embd*ggml_type_sizef(wtype)); // c_attn_proj_w
|
||||
|
||||
ctx_size += n_layer*(4*n_embd*n_embd*ggml_type_sizef(wtype)); // c_mlp_fc_w
|
||||
ctx_size += n_layer*( 4*n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_mlp_fc_b
|
||||
|
||||
ctx_size += n_layer*(4*n_embd*n_embd*ggml_type_sizef(wtype)); // c_mlp_proj_w
|
||||
ctx_size += n_layer*( n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_mlp_proj_b
|
||||
|
||||
ctx_size += n_ctx*n_layer*n_embd*ggml_type_sizef(GGML_TYPE_F16); // memory_k
|
||||
ctx_size += n_ctx*n_layer*n_embd*ggml_type_sizef(GGML_TYPE_F16); // memory_v
|
||||
|
||||
ctx_size += (5 + 10*n_layer)*512; // object overhead
|
||||
|
||||
printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0));
|
||||
}
|
||||
|
||||
// create the ggml context
|
||||
{
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = ctx_size,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
model.ctx = ggml_init(params);
|
||||
if (!model.ctx) {
|
||||
fprintf(stderr, "%s: ggml_init() failed\n", __func__);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// prepare memory for the weights
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
model.layers.resize(n_layer);
|
||||
|
||||
model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab);
|
||||
|
||||
model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
model.lmh_g = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab);
|
||||
model.lmh_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_vocab);
|
||||
|
||||
// map by name
|
||||
model.tensors["transformer.wte.weight"] = model.wte;
|
||||
|
||||
model.tensors["transformer.ln_f.weight"] = model.ln_f_g;
|
||||
model.tensors["transformer.ln_f.bias"] = model.ln_f_b;
|
||||
|
||||
model.tensors["lm_head.weight"] = model.lmh_g;
|
||||
model.tensors["lm_head.bias"] = model.lmh_b;
|
||||
|
||||
for (int i = 0; i < n_layer; ++i) {
|
||||
auto & layer = model.layers[i];
|
||||
|
||||
layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.c_attn_q_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd);
|
||||
layer.c_attn_k_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd);
|
||||
layer.c_attn_v_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd);
|
||||
|
||||
layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd);
|
||||
|
||||
layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd);
|
||||
layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd);
|
||||
|
||||
layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd);
|
||||
layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
// map by name
|
||||
model.tensors["transformer.h." + std::to_string(i) + ".ln_1.weight"] = layer.ln_1_g;
|
||||
model.tensors["transformer.h." + std::to_string(i) + ".ln_1.bias"] = layer.ln_1_b;
|
||||
|
||||
model.tensors["transformer.h." + std::to_string(i) + ".attn.q_proj.weight"] = layer.c_attn_q_proj_w;
|
||||
model.tensors["transformer.h." + std::to_string(i) + ".attn.k_proj.weight"] = layer.c_attn_k_proj_w;
|
||||
model.tensors["transformer.h." + std::to_string(i) + ".attn.v_proj.weight"] = layer.c_attn_v_proj_w;
|
||||
|
||||
model.tensors["transformer.h." + std::to_string(i) + ".attn.out_proj.weight"] = layer.c_attn_proj_w;
|
||||
|
||||
model.tensors["transformer.h." + std::to_string(i) + ".mlp.fc_in.weight"] = layer.c_mlp_fc_w;
|
||||
model.tensors["transformer.h." + std::to_string(i) + ".mlp.fc_in.bias"] = layer.c_mlp_fc_b;
|
||||
|
||||
model.tensors["transformer.h." + std::to_string(i) + ".mlp.fc_out.weight"] = layer.c_mlp_proj_w;
|
||||
model.tensors["transformer.h." + std::to_string(i) + ".mlp.fc_out.bias"] = layer.c_mlp_proj_b;
|
||||
}
|
||||
}
|
||||
|
||||
// key + value memory
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
|
||||
const int n_mem = n_layer*n_ctx;
|
||||
const int n_elements = n_embd*n_mem;
|
||||
|
||||
model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements);
|
||||
model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements);
|
||||
|
||||
const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v);
|
||||
|
||||
printf("%s: memory_size = %8.2f MB, n_mem = %d\n", __func__, memory_size/1024.0/1024.0, n_mem);
|
||||
}
|
||||
|
||||
// load weights
|
||||
{
|
||||
int n_tensors = 0;
|
||||
size_t total_size = 0;
|
||||
|
||||
printf("%s: ", __func__);
|
||||
|
||||
while (true) {
|
||||
int32_t n_dims;
|
||||
int32_t length;
|
||||
int32_t ttype;
|
||||
|
||||
fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
|
||||
fin.read(reinterpret_cast<char *>(&length), sizeof(length));
|
||||
fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype));
|
||||
|
||||
if (fin.eof()) {
|
||||
break;
|
||||
}
|
||||
|
||||
int32_t nelements = 1;
|
||||
int32_t ne[2] = { 1, 1 };
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i]));
|
||||
nelements *= ne[i];
|
||||
}
|
||||
|
||||
std::string name(length, 0);
|
||||
fin.read(&name[0], length);
|
||||
|
||||
if (model.tensors.find(name.data()) == model.tensors.end()) {
|
||||
fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.data());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto tensor = model.tensors[name.data()];
|
||||
if (ggml_nelements(tensor) != nelements) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.data());
|
||||
return false;
|
||||
}
|
||||
|
||||
if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%d, %d], expected [%d, %d]\n",
|
||||
__func__, name.data(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]);
|
||||
return false;
|
||||
}
|
||||
|
||||
// for debugging
|
||||
if (0) {
|
||||
printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.data(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor));
|
||||
}
|
||||
|
||||
const size_t bpe = ggml_type_size(ggml_type(ttype));
|
||||
|
||||
if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n",
|
||||
__func__, name.data(), ggml_nbytes(tensor), nelements*bpe);
|
||||
return false;
|
||||
}
|
||||
|
||||
fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor));
|
||||
|
||||
//printf("%42s - [%5d, %5d], type = %6s, %6.2f MB\n", name.data(), ne[0], ne[1], ttype == 0 ? "float" : "f16", ggml_nbytes(tensor)/1024.0/1024.0);
|
||||
total_size += ggml_nbytes(tensor);
|
||||
if (++n_tensors % 8 == 0) {
|
||||
printf(".");
|
||||
fflush(stdout);
|
||||
}
|
||||
}
|
||||
|
||||
printf(" done\n");
|
||||
|
||||
printf("%s: model size = %8.2f MB / num tensors = %d\n", __func__, total_size/1024.0/1024.0, n_tensors);
|
||||
}
|
||||
|
||||
fin.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// evaluate the transformer
|
||||
//
|
||||
// - model: the model
|
||||
// - n_threads: number of threads to use
|
||||
// - n_past: the context size so far
|
||||
// - embd_inp: the embeddings of the tokens in the context
|
||||
// - embd_w: the predicted logits for the next token
|
||||
//
|
||||
// The GPT-J model requires about 16MB of memory per input token.
|
||||
//
|
||||
bool gptj_eval(
|
||||
const gptj_model & model,
|
||||
const int n_threads,
|
||||
const int n_past,
|
||||
const std::vector<gpt_vocab::id> & embd_inp,
|
||||
std::vector<float> & embd_w,
|
||||
size_t & mem_per_token) {
|
||||
const int N = embd_inp.size();
|
||||
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_head = hparams.n_head;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
const int n_rot = hparams.n_rot;
|
||||
|
||||
static size_t buf_size = 256u*1024*1024;
|
||||
static void * buf = malloc(buf_size);
|
||||
|
||||
if (mem_per_token > 0 && mem_per_token*N > buf_size) {
|
||||
const size_t buf_size_new = 1.1*(mem_per_token*N); // add 10% to account for ggml object overhead
|
||||
//printf("\n%s: reallocating buffer from %zu to %zu bytes\n", __func__, buf_size, buf_size_new);
|
||||
|
||||
// reallocate
|
||||
buf_size = buf_size_new;
|
||||
buf = realloc(buf, buf_size);
|
||||
if (buf == nullptr) {
|
||||
fprintf(stderr, "%s: failed to allocate %zu bytes\n", __func__, buf_size);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = buf_size,
|
||||
.mem_buffer = buf,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
struct ggml_cgraph gf = {};
|
||||
gf.n_threads = n_threads;
|
||||
|
||||
struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N);
|
||||
memcpy(embd->data, embd_inp.data(), N*ggml_element_size(embd));
|
||||
|
||||
// wte
|
||||
struct ggml_tensor * inpL = ggml_get_rows(ctx0, model.wte, embd);
|
||||
|
||||
for (int il = 0; il < n_layer; ++il) {
|
||||
struct ggml_tensor * cur;
|
||||
|
||||
// norm
|
||||
{
|
||||
cur = ggml_norm(ctx0, inpL);
|
||||
|
||||
// cur = ln_1_g*cur + ln_1_b
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].ln_1_g, cur),
|
||||
cur),
|
||||
ggml_repeat(ctx0, model.layers[il].ln_1_b, cur));
|
||||
}
|
||||
|
||||
struct ggml_tensor * inpSA = cur;
|
||||
|
||||
// self-attention
|
||||
{
|
||||
struct ggml_tensor * Qcur = ggml_rope_inplace(ctx0, ggml_reshape_3d(ctx0, ggml_mul_mat(ctx0, model.layers[il].c_attn_q_proj_w, cur), n_embd/n_head, n_head, N), n_past, n_rot, 0);
|
||||
struct ggml_tensor * Kcur = ggml_rope_inplace(ctx0, ggml_reshape_3d(ctx0, ggml_mul_mat(ctx0, model.layers[il].c_attn_k_proj_w, cur), n_embd/n_head, n_head, N), n_past, n_rot, 0);
|
||||
|
||||
// store key and value to memory
|
||||
{
|
||||
struct ggml_tensor * Vcur = ggml_transpose(ctx0, ggml_mul_mat(ctx0, model.layers[il].c_attn_v_proj_w, cur));
|
||||
|
||||
struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past));
|
||||
struct ggml_tensor * v = ggml_view_2d(ctx0, model.memory_v, N, n_embd,
|
||||
( n_ctx)*ggml_element_size(model.memory_v),
|
||||
(il*n_ctx)*ggml_element_size(model.memory_v)*n_embd + n_past*ggml_element_size(model.memory_v));
|
||||
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Kcur, k));
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Vcur, v));
|
||||
}
|
||||
|
||||
// Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3)
|
||||
struct ggml_tensor * Q =
|
||||
ggml_permute(ctx0,
|
||||
Qcur,
|
||||
0, 2, 1, 3);
|
||||
|
||||
// K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3)
|
||||
struct ggml_tensor * K =
|
||||
ggml_permute(ctx0,
|
||||
ggml_reshape_3d(ctx0,
|
||||
ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd),
|
||||
n_embd/n_head, n_head, n_past + N),
|
||||
0, 2, 1, 3);
|
||||
|
||||
// K * Q
|
||||
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q);
|
||||
|
||||
// KQ_scaled = KQ / sqrt(n_embd/n_head)
|
||||
struct ggml_tensor * KQ_scaled =
|
||||
ggml_scale_inplace(ctx0,
|
||||
KQ,
|
||||
ggml_new_f32(ctx0, 1.0f/sqrt(float(n_embd)/n_head))
|
||||
);
|
||||
|
||||
// KQ_masked = mask_past(KQ_scaled)
|
||||
struct ggml_tensor * KQ_masked = ggml_diag_mask_inf_inplace(ctx0, KQ_scaled, n_past);
|
||||
|
||||
// KQ = soft_max(KQ_masked)
|
||||
struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked);
|
||||
|
||||
// V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous()
|
||||
struct ggml_tensor * V =
|
||||
ggml_view_3d(ctx0, model.memory_v,
|
||||
n_past + N, n_embd/n_head, n_head,
|
||||
n_ctx*ggml_element_size(model.memory_v),
|
||||
n_ctx*ggml_element_size(model.memory_v)*n_embd/n_head,
|
||||
il*n_ctx*ggml_element_size(model.memory_v)*n_embd);
|
||||
|
||||
// KQV = transpose(V) * KQ_soft_max
|
||||
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max);
|
||||
|
||||
// KQV_merged = KQV.permute(0, 2, 1, 3)
|
||||
struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3);
|
||||
|
||||
// cur = KQV_merged.contiguous().view(n_embd, N)
|
||||
cur = ggml_cpy(ctx0,
|
||||
KQV_merged,
|
||||
ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N));
|
||||
|
||||
// projection (no bias)
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_attn_proj_w,
|
||||
cur);
|
||||
}
|
||||
|
||||
struct ggml_tensor * inpFF = cur;
|
||||
|
||||
// feed-forward network
|
||||
// this is independent of the self-attention result, so it could be done in parallel to the self-attention
|
||||
{
|
||||
// note here we pass inpSA instead of cur
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_mlp_fc_w,
|
||||
inpSA);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_mlp_fc_b, cur),
|
||||
cur);
|
||||
|
||||
// GELU activation
|
||||
cur = ggml_gelu(ctx0, cur);
|
||||
|
||||
// projection
|
||||
// cur = proj_w*cur + proj_b
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_mlp_proj_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_mlp_proj_b, cur),
|
||||
cur);
|
||||
}
|
||||
|
||||
// self-attention + FF
|
||||
cur = ggml_add(ctx0, cur, inpFF);
|
||||
|
||||
// input for next layer
|
||||
inpL = ggml_add(ctx0, cur, inpL);
|
||||
}
|
||||
|
||||
// norm
|
||||
{
|
||||
inpL = ggml_norm(ctx0, inpL);
|
||||
|
||||
// inpL = ln_f_g*inpL + ln_f_b
|
||||
inpL = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.ln_f_g, inpL),
|
||||
inpL),
|
||||
ggml_repeat(ctx0, model.ln_f_b, inpL));
|
||||
}
|
||||
|
||||
// lm_head
|
||||
{
|
||||
inpL = ggml_mul_mat(ctx0, model.lmh_g, inpL);
|
||||
|
||||
inpL = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.lmh_b, inpL),
|
||||
inpL);
|
||||
}
|
||||
|
||||
// logits -> probs
|
||||
//inpL = ggml_soft_max_inplace(ctx0, inpL);
|
||||
|
||||
// run the computation
|
||||
ggml_build_forward_expand(&gf, inpL);
|
||||
ggml_graph_compute (ctx0, &gf);
|
||||
|
||||
//if (n_past%100 == 0) {
|
||||
// ggml_graph_print (&gf);
|
||||
// ggml_graph_dump_dot(&gf, NULL, "gpt-j.dot");
|
||||
//}
|
||||
|
||||
//embd_w.resize(n_vocab*N);
|
||||
//memcpy(embd_w.data(), ggml_get_data(inpL), sizeof(float)*n_vocab*N);
|
||||
|
||||
// return result for just the last token
|
||||
embd_w.resize(n_vocab);
|
||||
memcpy(embd_w.data(), (float *) ggml_get_data(inpL) + (n_vocab*(N-1)), sizeof(float)*n_vocab);
|
||||
|
||||
if (mem_per_token == 0) {
|
||||
mem_per_token = ggml_used_mem(ctx0)/N;
|
||||
}
|
||||
//printf("used_mem = %zu\n", ggml_used_mem(ctx0));
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
int main(int argc, char ** argv) {
|
||||
ggml_time_init();
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
gpt_params params;
|
||||
params.model = "models/gpt-j-6B/ggml-model.bin";
|
||||
|
||||
if (gpt_params_parse(argc, argv, params) == false) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
if (params.seed < 0) {
|
||||
params.seed = time(NULL);
|
||||
}
|
||||
|
||||
printf("%s: seed = %d\n", __func__, params.seed);
|
||||
|
||||
std::mt19937 rng(params.seed);
|
||||
if (params.prompt.empty()) {
|
||||
params.prompt = gpt_random_prompt(rng);
|
||||
}
|
||||
|
||||
int64_t t_load_us = 0;
|
||||
|
||||
gpt_vocab vocab;
|
||||
gptj_model model;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!gptj_model_load(params.model, model, vocab)) {
|
||||
fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_load_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
int n_past = 0;
|
||||
|
||||
int64_t t_sample_us = 0;
|
||||
int64_t t_predict_us = 0;
|
||||
|
||||
std::vector<float> logits;
|
||||
|
||||
// tokenize the prompt
|
||||
std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, params.prompt);
|
||||
|
||||
params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size());
|
||||
|
||||
printf("%s: number of tokens in prompt = %zu\n", __func__, embd_inp.size());
|
||||
printf("\n");
|
||||
|
||||
std::vector<gpt_vocab::id> embd;
|
||||
|
||||
// determine the required inference memory per token:
|
||||
size_t mem_per_token = 0;
|
||||
gptj_eval(model, params.n_threads, 0, { 0, 1, 2, 3 }, logits, mem_per_token);
|
||||
|
||||
for (int i = embd.size(); i < embd_inp.size() + params.n_predict; i++) {
|
||||
// predict
|
||||
if (embd.size() > 0) {
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!gptj_eval(model, params.n_threads, n_past, embd, logits, mem_per_token)) {
|
||||
printf("Failed to predict\n");
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_predict_us += ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
n_past += embd.size();
|
||||
embd.clear();
|
||||
|
||||
if (i >= embd_inp.size()) {
|
||||
// sample next token
|
||||
const int top_k = params.top_k;
|
||||
const float top_p = params.top_p;
|
||||
const float temp = params.temp;
|
||||
|
||||
const int n_vocab = model.hparams.n_vocab;
|
||||
|
||||
gpt_vocab::id id = 0;
|
||||
|
||||
{
|
||||
const int64_t t_start_sample_us = ggml_time_us();
|
||||
|
||||
id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng);
|
||||
|
||||
t_sample_us += ggml_time_us() - t_start_sample_us;
|
||||
}
|
||||
|
||||
// add it to the context
|
||||
embd.push_back(id);
|
||||
} else {
|
||||
// if here, it means we are still processing the input prompt
|
||||
for (int k = i; k < embd_inp.size(); k++) {
|
||||
embd.push_back(embd_inp[k]);
|
||||
if (embd.size() > params.n_batch) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
i += embd.size() - 1;
|
||||
}
|
||||
|
||||
// display text
|
||||
for (auto id : embd) {
|
||||
printf("%s", vocab.id_to_token[id].c_str());
|
||||
}
|
||||
fflush(stdout);
|
||||
|
||||
// end of text token
|
||||
if (embd.back() == 50256) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n\n");
|
||||
printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token);
|
||||
printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f);
|
||||
printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f);
|
||||
printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us/1000.0f, t_predict_us/1000.0f/n_past);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f);
|
||||
}
|
||||
|
||||
ggml_free(model.ctx);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,182 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
#include "common-ggml.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <regex>
|
||||
|
||||
// default hparams (GPT-J 6B)
|
||||
struct gptj_hparams {
|
||||
int32_t n_vocab = 50400;
|
||||
int32_t n_ctx = 2048;
|
||||
int32_t n_embd = 4096;
|
||||
int32_t n_head = 16;
|
||||
int32_t n_layer = 28;
|
||||
int32_t n_rot = 64;
|
||||
int32_t ftype = 1;
|
||||
};
|
||||
|
||||
// quantize a model
|
||||
bool gptj_model_quantize(const std::string & fname_inp, const std::string & fname_out, ggml_ftype ftype) {
|
||||
gpt_vocab vocab;
|
||||
|
||||
printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str());
|
||||
|
||||
auto finp = std::ifstream(fname_inp, std::ios::binary);
|
||||
if (!finp) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto fout = std::ofstream(fname_out, std::ios::binary);
|
||||
if (!fout) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname_out.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
finp.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
fout.write((char *) &magic, sizeof(magic));
|
||||
}
|
||||
|
||||
gptj_hparams hparams;
|
||||
|
||||
// load hparams
|
||||
{
|
||||
finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
finp.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
finp.read((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
finp.read((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
finp.read((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
finp.read((char *) &hparams.n_rot, sizeof(hparams.n_rot));
|
||||
finp.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype;
|
||||
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx);
|
||||
printf("%s: n_embd = %d\n", __func__, hparams.n_embd);
|
||||
printf("%s: n_head = %d\n", __func__, hparams.n_head);
|
||||
printf("%s: n_layer = %d\n", __func__, hparams.n_layer);
|
||||
printf("%s: ftype (src) = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr (src) = %d\n", __func__, qntvr_src);
|
||||
printf("%s: ftype (dst) = %d\n", __func__, ftype_dst);
|
||||
printf("%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION);
|
||||
|
||||
fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fout.write((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
fout.write((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
fout.write((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
fout.write((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
fout.write((char *) &hparams.n_rot, sizeof(hparams.n_rot));
|
||||
fout.write((char *) &ftype_dst, sizeof(ftype_dst));
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
int32_t n_vocab = 0;
|
||||
finp.read ((char *) &n_vocab, sizeof(n_vocab));
|
||||
fout.write((char *) &n_vocab, sizeof(n_vocab));
|
||||
|
||||
if (n_vocab != hparams.n_vocab) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n",
|
||||
__func__, fname_inp.c_str(), n_vocab, hparams.n_vocab);
|
||||
return false;
|
||||
}
|
||||
|
||||
std::string word;
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
finp.read ((char *) &len, sizeof(len));
|
||||
fout.write((char *) &len, sizeof(len));
|
||||
|
||||
word.resize(len);
|
||||
finp.read ((char *) word.data(), len);
|
||||
fout.write((char *) word.data(), len);
|
||||
|
||||
vocab.token_to_id[word] = i;
|
||||
vocab.id_to_token[i] = word;
|
||||
}
|
||||
}
|
||||
|
||||
// regexes of tensor names to be quantized
|
||||
const std::vector<std::string> to_quant = {
|
||||
".*weight",
|
||||
};
|
||||
|
||||
if (!ggml_common_quantize_0(finp, fout, ftype, to_quant, {})) {
|
||||
fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
finp.close();
|
||||
fout.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// usage:
|
||||
// ./gpt-2-quantize models/gpt-2-117M/ggml-model.bin models/gpt-2-117M/ggml-model-quant.bin type
|
||||
//
|
||||
int main(int argc, char ** argv) {
|
||||
if (argc != 4) {
|
||||
fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n", argv[0]);
|
||||
ggml_print_ftypes(stderr);
|
||||
return 1;
|
||||
}
|
||||
|
||||
// needed to initialize f16 tables
|
||||
{
|
||||
struct ggml_init_params params = { 0, NULL, false };
|
||||
struct ggml_context * ctx = ggml_init(params);
|
||||
ggml_free(ctx);
|
||||
}
|
||||
|
||||
const std::string fname_inp = argv[1];
|
||||
const std::string fname_out = argv[2];
|
||||
|
||||
const ggml_ftype ftype = ggml_parse_ftype(argv[3]);
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
int64_t t_quantize_us = 0;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!gptj_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) {
|
||||
fprintf(stderr, "%s: failed to quantize model from '%s'\n", __func__, fname_inp.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_quantize_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n");
|
||||
printf("%s: quantize time = %8.2f ms\n", __func__, t_quantize_us/1000.0f);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
#
|
||||
# gpt-neox
|
||||
|
||||
set(TEST_TARGET gpt-neox)
|
||||
add_executable(${TEST_TARGET} main.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
||||
#
|
||||
# gpt-neox-quantize
|
||||
|
||||
set(TEST_TARGET gpt-neox-quantize)
|
||||
add_executable(${TEST_TARGET} quantize.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
|
@ -0,0 +1,107 @@
|
|||
# GPT-NeoX
|
||||
|
||||
Transformer architecture: GPT-NeoX
|
||||
|
||||
Ref: https://github.com/stability-AI/stableLM/#stablelm-alpha
|
||||
|
||||
## Usage
|
||||
|
||||
```bash
|
||||
# get the repo and build it
|
||||
git clone https://github.com/ggerganov/ggml
|
||||
cd ggml
|
||||
mkdir build && cd build
|
||||
cmake ..
|
||||
make -j
|
||||
|
||||
# get the StableLM 3B Alpha model
|
||||
git clone https://huggingface.co/stabilityai/gpt_neox-base-alpha-3b
|
||||
|
||||
# convert model to FP16
|
||||
python3 ../examples/gpt_neox/convert-h5-to-ggml.py ./stablelm-base-alpha-3b/ 1
|
||||
|
||||
# run inference using FP16 precision
|
||||
make -j && ./bin/gpt_neox -m ./stablelm-base-alpha-3b/ggml-model-f16.bin -p "I believe the meaning of life is" -t 8 -n 64
|
||||
|
||||
main: seed = 1681940611
|
||||
gpt_neox_model_load: loading model from 'models/stablelm-base-alpha-3b/ggml-model-f16.bin' - please wait ...
|
||||
gpt_neox_model_load: n_vocab = 50688
|
||||
gpt_neox_model_load: n_ctx = 4096
|
||||
gpt_neox_model_load: n_embd = 4096
|
||||
gpt_neox_model_load: n_head = 32
|
||||
gpt_neox_model_load: n_layer = 16
|
||||
gpt_neox_model_load: n_rot = 32
|
||||
gpt_neox_model_load: ftype = 1
|
||||
gpt_neox_model_load: ggml ctx size = 10011.10 MB
|
||||
gpt_neox_model_load: memory_size = 2048.00 MB, n_mem = 65536
|
||||
gpt_neox_model_load: ................................ done
|
||||
gpt_neox_model_load: model size = 6939.28 MB / num tensors = 260
|
||||
main: number of tokens in prompt = 7
|
||||
main: token[0] = 42, I
|
||||
main: token[1] = 2868, believe
|
||||
main: token[2] = 253, the
|
||||
main: token[3] = 4495, meaning
|
||||
main: token[4] = 273, of
|
||||
main: token[5] = 1495, life
|
||||
main: token[6] = 310, is
|
||||
|
||||
I believe the meaning of life is to grow, to find a way, to love, to find an appreciation for life, and to live it with all of its beauty.
|
||||
|
||||
For I am the child of God. I am the offspring of God's love. I am the offspring of the light of the world. I am the offspring of the
|
||||
|
||||
main: mem per token = 12186760 bytes
|
||||
main: load time = 2118.55 ms
|
||||
main: sample time = 9.59 ms
|
||||
main: predict time = 4474.07 ms / 63.92 ms per token
|
||||
main: total time = 6911.26 ms
|
||||
```
|
||||
|
||||
## 5-bit integer quantization mode
|
||||
|
||||
```bash
|
||||
# quantize the model to 5-bits using Q5_0 quantization
|
||||
./bin/gpt_neox-quantize ./stablelm-base-alpha-3b/ggml-model-f16.bin ./stablelm-base-alpha-3b/ggml-model-q5_0.bin q5_0
|
||||
|
||||
# run the quantized model
|
||||
./bin/gpt_neox -m ./stablelm-base-alpha-3b/ggml-model-q5_0.bin -p "I believe the meaning of life is" -t 8 -n 64
|
||||
|
||||
main: seed = 1682021489
|
||||
gpt_neox_model_load: loading model from 'models/stablelm-base-alpha-3b/ggml-model-q5_0.bin' - please wait ...
|
||||
gpt_neox_model_load: n_vocab = 50688
|
||||
gpt_neox_model_load: n_ctx = 4096
|
||||
gpt_neox_model_load: n_embd = 4096
|
||||
gpt_neox_model_load: n_head = 32
|
||||
gpt_neox_model_load: n_layer = 16
|
||||
gpt_neox_model_load: n_rot = 32
|
||||
gpt_neox_model_load: ftype = 6
|
||||
gpt_neox_model_load: ggml ctx size = 5676.10 MB
|
||||
gpt_neox_model_load: memory_size = 1024.00 MB, n_mem = 65536
|
||||
gpt_neox_model_load: ........................ done
|
||||
gpt_neox_model_load: model size = 2604.28 MB / num tensors = 196
|
||||
main: number of tokens in prompt = 7
|
||||
main: token[0] = 42, I
|
||||
main: token[1] = 2868, believe
|
||||
main: token[2] = 253, the
|
||||
main: token[3] = 4495, meaning
|
||||
main: token[4] = 273, of
|
||||
main: token[5] = 1495, life
|
||||
main: token[6] = 310, is
|
||||
|
||||
I believe the meaning of life is to love and be loved. The last three verses were enough to tie us all together. If you love someone you love them all. There are some things in this world that are just not equal in Heaven. - Be here in this moment.
|
||||
|
||||
This world is not what is outside of us. It is what
|
||||
|
||||
main: mem per token = 12958024 bytes
|
||||
main: load time = 850.51 ms
|
||||
main: sample time = 9.95 ms
|
||||
main: predict time = 3103.81 ms / 44.34 ms per token
|
||||
main: total time = 4177.68 ms
|
||||
|
||||
```
|
||||
|
||||
## Notes
|
||||
|
||||
- No guarantees for correctness
|
||||
- The tokenizer is currently hacked - probably works only for English
|
||||
- Non-parallel residual is not supported
|
||||
- Contributions and improvements are welcome
|
||||
|
|
@ -0,0 +1,116 @@
|
|||
import sys
|
||||
import struct
|
||||
import json
|
||||
import numpy as np
|
||||
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
if len(sys.argv) < 3:
|
||||
print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n")
|
||||
print(" ftype == 0 -> float32")
|
||||
print(" ftype == 1 -> float16")
|
||||
sys.exit(1)
|
||||
|
||||
# output in the same directory as the model
|
||||
dir_model = sys.argv[1]
|
||||
fname_out = sys.argv[1] + "/ggml-model.bin"
|
||||
|
||||
with open(dir_model + "/tokenizer.json", "r", encoding="utf-8") as f:
|
||||
encoder = json.load(f)
|
||||
|
||||
with open(dir_model + "/config.json", "r", encoding="utf-8") as f:
|
||||
hparams = json.load(f)
|
||||
|
||||
# possible data types
|
||||
# ftype == 0 -> float32
|
||||
# ftype == 1 -> float16
|
||||
#
|
||||
# map from ftype to string
|
||||
ftype_str = ["f32", "f16"]
|
||||
|
||||
ftype = 1
|
||||
if len(sys.argv) > 2:
|
||||
ftype = int(sys.argv[2])
|
||||
if ftype < 0 or ftype > 1:
|
||||
print("Invalid ftype: " + str(ftype))
|
||||
sys.exit(1)
|
||||
fname_out = sys.argv[1] + "/ggml-model-" + ftype_str[ftype] + ".bin"
|
||||
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(dir_model)
|
||||
model = AutoModelForCausalLM.from_pretrained(dir_model, low_cpu_mem_usage=True)
|
||||
#print (model)
|
||||
|
||||
#print(tokenizer.encode('I believe the meaning of life is'))
|
||||
|
||||
list_vars = model.state_dict()
|
||||
for name in list_vars.keys():
|
||||
print(name, list_vars[name].shape, list_vars[name].dtype)
|
||||
|
||||
fout = open(fname_out, "wb")
|
||||
|
||||
print(hparams)
|
||||
|
||||
fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex
|
||||
fout.write(struct.pack("i", hparams["vocab_size"]))
|
||||
fout.write(struct.pack("i", hparams["max_position_embeddings"]))
|
||||
fout.write(struct.pack("i", hparams["hidden_size"]))
|
||||
fout.write(struct.pack("i", hparams["num_attention_heads"]))
|
||||
fout.write(struct.pack("i", hparams["num_hidden_layers"]))
|
||||
fout.write(struct.pack("i", int(hparams["rotary_pct"]*(hparams["hidden_size"]//hparams["num_attention_heads"]))))
|
||||
fout.write(struct.pack("i", hparams["use_parallel_residual"] if "use_parallel_residual" in hparams else True))
|
||||
fout.write(struct.pack("i", ftype))
|
||||
|
||||
# TODO: temporary hack to not deal with implementing the tokenizer
|
||||
dot_token = tokenizer.encode('.')[0]
|
||||
for i in range(hparams["vocab_size"]):
|
||||
text = tokenizer.decode([dot_token, i]).encode('utf-8')
|
||||
# remove the first byte (it's always '.')
|
||||
text = text[1:]
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
|
||||
for name in list_vars.keys():
|
||||
data = list_vars[name].squeeze().numpy()
|
||||
print("Processing variable: " + name + " with shape: ", data.shape)
|
||||
|
||||
# we don't need these
|
||||
if name.endswith(".attention.masked_bias") or \
|
||||
name.endswith(".attention.bias") or \
|
||||
name.endswith(".attention.rotary_emb.inv_freq"):
|
||||
print(" Skipping variable: " + name)
|
||||
continue
|
||||
|
||||
n_dims = len(data.shape);
|
||||
|
||||
# ftype == 0 -> float32, ftype == 1 -> float16
|
||||
ftype_cur = 0;
|
||||
if ftype != 0:
|
||||
if name[-7:] == ".weight" and n_dims == 2:
|
||||
print(" Converting to float16")
|
||||
data = data.astype(np.float16)
|
||||
ftype_cur = 1
|
||||
else:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype_cur = 0
|
||||
else:
|
||||
if data.dtype != np.float32:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype_cur = 0
|
||||
|
||||
# header
|
||||
str = name.encode('utf-8')
|
||||
fout.write(struct.pack("iii", n_dims, len(str), ftype_cur))
|
||||
for i in range(n_dims):
|
||||
fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
|
||||
fout.write(str);
|
||||
|
||||
# data
|
||||
data.tofile(fout)
|
||||
|
||||
fout.close()
|
||||
|
||||
print("Done. Output file: " + fname_out)
|
||||
print("")
|
||||
|
|
@ -0,0 +1,807 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
#include "common-ggml.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <cinttypes>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
// default hparams (StableLM 3B)
|
||||
struct gpt_neox_hparams {
|
||||
int32_t n_vocab = 50257;
|
||||
int32_t n_ctx = 4096;
|
||||
int32_t n_embd = 4096;
|
||||
int32_t n_head = 32;
|
||||
int32_t n_layer = 16;
|
||||
int32_t n_rot = 32; // rotary_pct * (n_embd / n_head)
|
||||
int32_t par_res = 1; // 1 = true, 0 = false
|
||||
int32_t ftype = 1;
|
||||
};
|
||||
|
||||
struct gpt_neox_layer {
|
||||
// pre normalization
|
||||
struct ggml_tensor * ln_1_g;
|
||||
struct ggml_tensor * ln_1_b;
|
||||
|
||||
// attention
|
||||
struct ggml_tensor * c_attn_attn_w;
|
||||
struct ggml_tensor * c_attn_attn_b;
|
||||
|
||||
struct ggml_tensor * c_attn_proj_w;
|
||||
struct ggml_tensor * c_attn_proj_b;
|
||||
|
||||
// post normalization
|
||||
struct ggml_tensor * ln_2_g;
|
||||
struct ggml_tensor * ln_2_b;
|
||||
|
||||
// ff
|
||||
struct ggml_tensor * c_mlp_fc_w;
|
||||
struct ggml_tensor * c_mlp_fc_b;
|
||||
|
||||
struct ggml_tensor * c_mlp_proj_w;
|
||||
struct ggml_tensor * c_mlp_proj_b;
|
||||
};
|
||||
|
||||
struct gpt_neox_model {
|
||||
gpt_neox_hparams hparams;
|
||||
|
||||
// normalization
|
||||
struct ggml_tensor * ln_f_g;
|
||||
struct ggml_tensor * ln_f_b;
|
||||
|
||||
struct ggml_tensor * wte; // position embedding
|
||||
|
||||
struct ggml_tensor * lmh_g; // language model head
|
||||
//struct ggml_tensor * lmh_b; // language model bias
|
||||
|
||||
std::vector<gpt_neox_layer> layers;
|
||||
|
||||
// key + value memory
|
||||
struct ggml_tensor * memory_k;
|
||||
struct ggml_tensor * memory_v;
|
||||
|
||||
//
|
||||
struct ggml_context * ctx;
|
||||
std::map<std::string, struct ggml_tensor *> tensors;
|
||||
};
|
||||
|
||||
// load the model's weights from a file
|
||||
bool gpt_neox_model_load(const std::string & fname, gpt_neox_model & model, gpt_vocab & vocab) {
|
||||
printf("%s: loading model from '%s' - please wait ...\n", __func__, fname.c_str());
|
||||
|
||||
auto fin = std::ifstream(fname, std::ios::binary);
|
||||
if (!fin) {
|
||||
fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
fin.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// load hparams
|
||||
{
|
||||
auto & hparams = model.hparams;
|
||||
|
||||
fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
fin.read((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
fin.read((char *) &hparams.n_rot, sizeof(hparams.n_rot));
|
||||
fin.read((char *) &hparams.par_res, sizeof(hparams.par_res));
|
||||
fin.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx);
|
||||
printf("%s: n_embd = %d\n", __func__, hparams.n_embd);
|
||||
printf("%s: n_head = %d\n", __func__, hparams.n_head);
|
||||
printf("%s: n_layer = %d\n", __func__, hparams.n_layer);
|
||||
printf("%s: n_rot = %d\n", __func__, hparams.n_rot);
|
||||
printf("%s: par_res = %d\n", __func__, hparams.par_res);
|
||||
printf("%s: ftype = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr = %d\n", __func__, qntvr);
|
||||
|
||||
hparams.ftype %= GGML_QNT_VERSION_FACTOR;
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
const int32_t n_vocab = model.hparams.n_vocab;
|
||||
|
||||
std::string word;
|
||||
std::vector<char> buf(128);
|
||||
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
fin.read((char *) &len, sizeof(len));
|
||||
|
||||
buf.resize(len);
|
||||
fin.read((char *) buf.data(), len);
|
||||
word.assign(buf.data(), len);
|
||||
|
||||
vocab.token_to_id[word] = i;
|
||||
vocab.id_to_token[i] = word;
|
||||
}
|
||||
}
|
||||
|
||||
// for the big tensors, we have the option to store the data in 16-bit floats or quantized
|
||||
// in order to save memory and also to speed up the computation
|
||||
ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype));
|
||||
if (wtype == GGML_TYPE_COUNT) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n",
|
||||
__func__, fname.c_str(), model.hparams.ftype);
|
||||
return false;
|
||||
}
|
||||
|
||||
auto & ctx = model.ctx;
|
||||
|
||||
size_t ctx_size = 0;
|
||||
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
ctx_size += n_embd*ggml_type_sizef(GGML_TYPE_F32); // ln_f_g
|
||||
ctx_size += n_embd*ggml_type_sizef(GGML_TYPE_F32); // ln_f_b
|
||||
|
||||
ctx_size += n_embd*n_vocab*ggml_type_sizef(wtype); // wte
|
||||
|
||||
ctx_size += n_embd*n_vocab*ggml_type_sizef(wtype); // lmh_g
|
||||
//ctx_size += n_vocab*ggml_type_sizef(GGML_TYPE_F32); // lmh_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_1_g
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_1_b
|
||||
|
||||
ctx_size += n_layer*(3*n_embd*n_embd*ggml_type_sizef(wtype)); // c_attn_attn_w
|
||||
ctx_size += n_layer*( 3*n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_attn_attn_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*n_embd*ggml_type_sizef(wtype)); // c_attn_proj_w
|
||||
ctx_size += n_layer*(n_embd*n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_attn_proj_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_2_g
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_2_b
|
||||
|
||||
ctx_size += n_layer*(4*n_embd*n_embd*ggml_type_sizef(wtype)); // c_mlp_fc_w
|
||||
ctx_size += n_layer*( 4*n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_mlp_fc_b
|
||||
|
||||
ctx_size += n_layer*(4*n_embd*n_embd*ggml_type_sizef(wtype)); // c_mlp_proj_w
|
||||
ctx_size += n_layer*( n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_mlp_proj_b
|
||||
|
||||
ctx_size += n_ctx*n_layer*n_embd*ggml_type_sizef(GGML_TYPE_F32); // memory_k
|
||||
ctx_size += n_ctx*n_layer*n_embd*ggml_type_sizef(GGML_TYPE_F32); // memory_v
|
||||
|
||||
ctx_size += (6 + 16*n_layer)*512; // object overhead
|
||||
|
||||
printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0));
|
||||
}
|
||||
|
||||
// create the ggml context
|
||||
{
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = ctx_size,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
model.ctx = ggml_init(params);
|
||||
if (!model.ctx) {
|
||||
fprintf(stderr, "%s: ggml_init() failed\n", __func__);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// prepare memory for the weights
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
model.layers.resize(n_layer);
|
||||
|
||||
model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab);
|
||||
|
||||
model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
model.lmh_g = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab);
|
||||
//model.lmh_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_vocab);
|
||||
|
||||
// map by name
|
||||
model.tensors["gpt_neox.embed_in.weight"] = model.wte;
|
||||
|
||||
model.tensors["gpt_neox.final_layer_norm.weight"] = model.ln_f_g;
|
||||
model.tensors["gpt_neox.final_layer_norm.bias"] = model.ln_f_b;
|
||||
|
||||
model.tensors["embed_out.weight"] = model.lmh_g;
|
||||
//model.tensors["lm_head.bias"] = model.lmh_b;
|
||||
|
||||
for (int i = 0; i < n_layer; ++i) {
|
||||
auto & layer = model.layers[i];
|
||||
|
||||
layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.c_attn_attn_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 3*n_embd);
|
||||
layer.c_attn_attn_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 3*n_embd);
|
||||
|
||||
layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd);
|
||||
layer.c_attn_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.ln_2_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
layer.ln_2_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd);
|
||||
layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd);
|
||||
|
||||
layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd);
|
||||
layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
// map by name
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".input_layernorm.weight"] = layer.ln_1_g;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".input_layernorm.bias"] = layer.ln_1_b;
|
||||
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.query_key_value.weight"] = layer.c_attn_attn_w;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.query_key_value.bias"] = layer.c_attn_attn_b;
|
||||
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.dense.weight"] = layer.c_attn_proj_w;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.dense.bias"] = layer.c_attn_proj_b;
|
||||
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".post_attention_layernorm.weight"] = layer.ln_2_g;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".post_attention_layernorm.bias"] = layer.ln_2_b;
|
||||
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_h_to_4h.weight"] = layer.c_mlp_fc_w;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_h_to_4h.bias"] = layer.c_mlp_fc_b;
|
||||
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_4h_to_h.weight"] = layer.c_mlp_proj_w;
|
||||
model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_4h_to_h.bias"] = layer.c_mlp_proj_b;
|
||||
}
|
||||
}
|
||||
|
||||
// key + value memory
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
|
||||
const int64_t n_mem = n_layer*n_ctx;
|
||||
const int64_t n_elements = n_embd*n_mem;
|
||||
|
||||
model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements);
|
||||
model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements);
|
||||
|
||||
const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v);
|
||||
|
||||
printf("%s: memory_size = %8.2f MB, n_mem = %" PRId64 "\n", __func__, memory_size/1024.0/1024.0, n_mem);
|
||||
}
|
||||
|
||||
// load weights
|
||||
{
|
||||
int n_tensors = 0;
|
||||
size_t total_size = 0;
|
||||
|
||||
printf("%s: ", __func__);
|
||||
|
||||
while (true) {
|
||||
int32_t n_dims;
|
||||
int32_t length;
|
||||
int32_t ttype;
|
||||
|
||||
fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
|
||||
fin.read(reinterpret_cast<char *>(&length), sizeof(length));
|
||||
fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype));
|
||||
|
||||
if (fin.eof()) {
|
||||
break;
|
||||
}
|
||||
|
||||
int32_t nelements = 1;
|
||||
int32_t ne[2] = { 1, 1 };
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i]));
|
||||
nelements *= ne[i];
|
||||
}
|
||||
|
||||
std::string name(length, 0);
|
||||
fin.read(&name[0], length);
|
||||
|
||||
if (model.tensors.find(name.data()) == model.tensors.end()) {
|
||||
fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.data());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto tensor = model.tensors[name.data()];
|
||||
if (ggml_nelements(tensor) != nelements) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.data());
|
||||
return false;
|
||||
}
|
||||
|
||||
if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%5d, %5d], expected [%5d, %5d]\n",
|
||||
__func__, name.data(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]);
|
||||
return false;
|
||||
}
|
||||
|
||||
// for debugging
|
||||
if (0) {
|
||||
printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.data(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor));
|
||||
}
|
||||
|
||||
const size_t bpe = ggml_type_size(ggml_type(ttype));
|
||||
|
||||
if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n",
|
||||
__func__, name.data(), ggml_nbytes(tensor), nelements*bpe);
|
||||
return false;
|
||||
}
|
||||
|
||||
fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor));
|
||||
|
||||
total_size += ggml_nbytes(tensor);
|
||||
if (++n_tensors % 8 == 0) {
|
||||
printf(".");
|
||||
fflush(stdout);
|
||||
}
|
||||
}
|
||||
|
||||
printf(" done\n");
|
||||
|
||||
printf("%s: model size = %8.2f MB / num tensors = %d\n", __func__, total_size/1024.0/1024.0, n_tensors);
|
||||
}
|
||||
|
||||
fin.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
|
||||
// feed-forward network
|
||||
ggml_tensor * gpt_neox_ff(
|
||||
const gpt_neox_layer &layer,
|
||||
ggml_context * ctx0,
|
||||
ggml_tensor * inp) {
|
||||
ggml_tensor * cur = ggml_norm(ctx0, inp);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, layer.ln_2_g, cur),
|
||||
cur),
|
||||
ggml_repeat(ctx0, layer.ln_2_b, cur));
|
||||
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
layer.c_mlp_fc_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, layer.c_mlp_fc_b, cur),
|
||||
cur);
|
||||
|
||||
// GELU activation
|
||||
cur = ggml_gelu(ctx0, cur);
|
||||
|
||||
// projection
|
||||
// cur = proj_w*cur + proj_b
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
layer.c_mlp_proj_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, layer.c_mlp_proj_b, cur),
|
||||
cur);
|
||||
return cur;
|
||||
}
|
||||
|
||||
// evaluate the transformer
|
||||
//
|
||||
// - model: the model
|
||||
// - n_threads: number of threads to use
|
||||
// - n_past: the context size so far
|
||||
// - embd_inp: the embeddings of the tokens in the context
|
||||
// - embd_w: the predicted logits for the next token
|
||||
//
|
||||
bool gpt_neox_eval(
|
||||
const gpt_neox_model & model,
|
||||
const int n_threads,
|
||||
const int n_past,
|
||||
const std::vector<gpt_vocab::id> & embd_inp,
|
||||
std::vector<float> & embd_w,
|
||||
size_t & mem_per_token) {
|
||||
const int N = embd_inp.size();
|
||||
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_head = hparams.n_head;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
const int n_rot = hparams.n_rot;
|
||||
|
||||
static size_t buf_size = 256u*1024*1024;
|
||||
static void * buf = malloc(buf_size);
|
||||
|
||||
// use 2 scratch buffers
|
||||
// TODO: very hacky solution - reimplement in a more elegant way
|
||||
static size_t scr0_size = 256u*1024*1024;
|
||||
static void * scr0 = malloc(scr0_size);
|
||||
|
||||
static size_t scr1_size = 256u*1024*1024;
|
||||
static void * scr1 = malloc(scr1_size);
|
||||
|
||||
if (mem_per_token > 0 && mem_per_token*N > buf_size) {
|
||||
const size_t buf_size_new = 1.1*(mem_per_token*N); // add 10% to account for ggml object overhead
|
||||
//printf("\n%s: reallocating buffer from %zu to %zu bytes\n", __func__, buf_size, buf_size_new);
|
||||
|
||||
// reallocate
|
||||
buf_size = buf_size_new;
|
||||
buf = realloc(buf, buf_size);
|
||||
if (buf == nullptr) {
|
||||
fprintf(stderr, "%s: failed to allocate %zu bytes\n", __func__, buf_size);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = buf_size,
|
||||
.mem_buffer = buf,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
struct ggml_cgraph gf = {};
|
||||
gf.n_threads = n_threads;
|
||||
|
||||
struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N);
|
||||
memcpy(embd->data, embd_inp.data(), N*ggml_element_size(embd));
|
||||
|
||||
// wte
|
||||
struct ggml_tensor * inpL = ggml_get_rows(ctx0, model.wte, embd);
|
||||
|
||||
for (int il = 0; il < n_layer; ++il) {
|
||||
struct ggml_tensor * cur;
|
||||
|
||||
ggml_set_scratch(ctx0, { 0, scr0_size, scr0, });
|
||||
|
||||
// self-attention
|
||||
{
|
||||
{
|
||||
cur = ggml_norm(ctx0, inpL);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].ln_1_g, cur),
|
||||
cur),
|
||||
ggml_repeat(ctx0, model.layers[il].ln_1_b, cur));
|
||||
}
|
||||
|
||||
// compute QKV
|
||||
{
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_attn_attn_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_attn_attn_b, cur),
|
||||
cur);
|
||||
}
|
||||
|
||||
struct ggml_tensor * Qcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 0*sizeof(float)*n_embd/n_head));
|
||||
struct ggml_tensor * Kcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 1*sizeof(float)*n_embd/n_head));
|
||||
struct ggml_tensor * Vcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 2*sizeof(float)*n_embd/n_head));
|
||||
|
||||
// using mode = 2 for GPT-NeoX mode
|
||||
Qcur = ggml_rope_inplace(ctx0, Qcur, n_past, n_rot, 2);
|
||||
Kcur = ggml_rope_inplace(ctx0, Kcur, n_past, n_rot, 2);
|
||||
|
||||
// store key and value to memory
|
||||
{
|
||||
Vcur = ggml_transpose(ctx0, ggml_reshape_2d(ctx0, Vcur, n_embd, N));
|
||||
|
||||
struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past));
|
||||
struct ggml_tensor * v = ggml_view_2d(ctx0, model.memory_v, N, n_embd,
|
||||
( n_ctx)*ggml_element_size(model.memory_v),
|
||||
(il*n_ctx)*ggml_element_size(model.memory_v)*n_embd + n_past*ggml_element_size(model.memory_v));
|
||||
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Kcur, k));
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Vcur, v));
|
||||
}
|
||||
|
||||
// Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3)
|
||||
struct ggml_tensor * Q =
|
||||
ggml_permute(ctx0,
|
||||
Qcur,
|
||||
0, 2, 1, 3);
|
||||
|
||||
// K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3)
|
||||
struct ggml_tensor * K =
|
||||
ggml_permute(ctx0,
|
||||
ggml_reshape_3d(ctx0,
|
||||
ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd),
|
||||
n_embd/n_head, n_head, n_past + N),
|
||||
0, 2, 1, 3);
|
||||
|
||||
// K * Q
|
||||
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q);
|
||||
|
||||
// KQ_scaled = KQ / sqrt(n_embd/n_head)
|
||||
struct ggml_tensor * KQ_scaled =
|
||||
ggml_scale_inplace(ctx0,
|
||||
KQ,
|
||||
ggml_new_f32(ctx0, 1.0f/sqrt(float(n_embd)/n_head))
|
||||
);
|
||||
|
||||
// KQ_masked = mask_past(KQ_scaled)
|
||||
struct ggml_tensor * KQ_masked = ggml_diag_mask_inf_inplace(ctx0, KQ_scaled, n_past);
|
||||
|
||||
// KQ = soft_max(KQ_masked)
|
||||
struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked);
|
||||
|
||||
// V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous()
|
||||
struct ggml_tensor * V =
|
||||
ggml_view_3d(ctx0, model.memory_v,
|
||||
n_past + N, n_embd/n_head, n_head,
|
||||
n_ctx*ggml_element_size(model.memory_v),
|
||||
n_ctx*ggml_element_size(model.memory_v)*n_embd/n_head,
|
||||
il*n_ctx*ggml_element_size(model.memory_v)*n_embd);
|
||||
|
||||
// KQV = transpose(V) * KQ_soft_max
|
||||
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max);
|
||||
|
||||
// KQV_merged = KQV.permute(0, 2, 1, 3)
|
||||
struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3);
|
||||
|
||||
// cur = KQV_merged.contiguous().view(n_embd, N)
|
||||
cur = ggml_cpy(ctx0,
|
||||
KQV_merged,
|
||||
ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N));
|
||||
|
||||
// projection
|
||||
{
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_attn_proj_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0, ggml_repeat(ctx0, model.layers[il].c_attn_proj_b, cur), cur);
|
||||
}
|
||||
}
|
||||
|
||||
ggml_set_scratch(ctx0, { 0, scr1_size, scr1, });
|
||||
|
||||
if (hparams.par_res == 0) {
|
||||
struct ggml_tensor * inpFF = ggml_add(ctx0, cur, inpL);
|
||||
|
||||
cur = gpt_neox_ff(model.layers[il], ctx0, inpFF);
|
||||
|
||||
// input for next layer
|
||||
inpL = ggml_add(ctx0, cur, inpFF);
|
||||
} else {
|
||||
struct ggml_tensor * inpFF = cur;
|
||||
|
||||
// this is independent of the self-attention result, so it could be done in parallel to the self-attention
|
||||
// note here we pass inpL instead of cur
|
||||
cur = gpt_neox_ff(model.layers[il], ctx0, inpL);
|
||||
|
||||
// layer input + FF
|
||||
cur = ggml_add(ctx0, cur, inpFF);
|
||||
|
||||
// input for next layer
|
||||
inpL = ggml_add(ctx0, cur, inpL);
|
||||
}
|
||||
}
|
||||
|
||||
ggml_set_scratch(ctx0, { 0, scr0_size, scr0, });
|
||||
|
||||
// norm
|
||||
{
|
||||
inpL = ggml_norm(ctx0, inpL);
|
||||
|
||||
// inpL = ln_f_g*inpL + ln_f_b
|
||||
inpL = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.ln_f_g, inpL),
|
||||
inpL),
|
||||
ggml_repeat(ctx0, model.ln_f_b, inpL));
|
||||
}
|
||||
|
||||
ggml_set_scratch(ctx0, { 0, 0, nullptr, });
|
||||
|
||||
// lm_head
|
||||
{
|
||||
inpL = ggml_mul_mat(ctx0, model.lmh_g, inpL);
|
||||
|
||||
//inpL = ggml_add(ctx0,
|
||||
// ggml_repeat(ctx0, model.lmh_b, inpL),
|
||||
// inpL);
|
||||
}
|
||||
|
||||
// logits -> probs
|
||||
//inpL = ggml_soft_max_inplace(ctx0, inpL);
|
||||
|
||||
// run the computation
|
||||
ggml_build_forward_expand(&gf, inpL);
|
||||
ggml_graph_compute (ctx0, &gf);
|
||||
|
||||
//if (n_past%100 == 0) {
|
||||
// ggml_graph_print (&gf);
|
||||
// ggml_graph_dump_dot(&gf, NULL, "gpt-2.dot");
|
||||
//}
|
||||
|
||||
//embd_w.resize(n_vocab*N);
|
||||
//memcpy(embd_w.data(), ggml_get_data(inpL), sizeof(float)*n_vocab*N);
|
||||
|
||||
// return result for just the last token
|
||||
embd_w.resize(n_vocab);
|
||||
memcpy(embd_w.data(), (float *) ggml_get_data(inpL) + (n_vocab*(N-1)), sizeof(float)*n_vocab);
|
||||
|
||||
if (mem_per_token == 0) {
|
||||
mem_per_token = ggml_used_mem(ctx0)/N;
|
||||
}
|
||||
//printf("used_mem = %zu\n", ggml_used_mem(ctx0));
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
int main(int argc, char ** argv) {
|
||||
ggml_time_init();
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
gpt_params params;
|
||||
params.model = "models/stablelm-base-alpha-3b/ggml-model-f16.bin";
|
||||
|
||||
if (gpt_params_parse(argc, argv, params) == false) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
if (params.seed < 0) {
|
||||
params.seed = time(NULL);
|
||||
}
|
||||
|
||||
printf("%s: seed = %d\n", __func__, params.seed);
|
||||
|
||||
std::mt19937 rng(params.seed);
|
||||
if (params.prompt.empty()) {
|
||||
params.prompt = gpt_random_prompt(rng);
|
||||
}
|
||||
|
||||
int64_t t_load_us = 0;
|
||||
|
||||
gpt_vocab vocab;
|
||||
gpt_neox_model model;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!gpt_neox_model_load(params.model, model, vocab)) {
|
||||
fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_load_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
int n_past = 0;
|
||||
|
||||
int64_t t_sample_us = 0;
|
||||
int64_t t_predict_us = 0;
|
||||
|
||||
std::vector<float> logits;
|
||||
|
||||
// tokenize the prompt
|
||||
std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, params.prompt);
|
||||
|
||||
params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size());
|
||||
|
||||
printf("%s: number of tokens in prompt = %zu\n", __func__, embd_inp.size());
|
||||
for (int i = 0; i < embd_inp.size(); i++) {
|
||||
printf("%s: token[%d] = %6d, %s\n", __func__, i, embd_inp[i], vocab.id_to_token.at(embd_inp[i]).c_str());
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
std::vector<gpt_vocab::id> embd;
|
||||
|
||||
// determine the required inference memory per token:
|
||||
size_t mem_per_token = 0;
|
||||
gpt_neox_eval(model, params.n_threads, 0, { 0, 1, 2, 3 }, logits, mem_per_token);
|
||||
|
||||
for (int i = embd.size(); i < embd_inp.size() + params.n_predict; i++) {
|
||||
// predict
|
||||
if (embd.size() > 0) {
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!gpt_neox_eval(model, params.n_threads, n_past, embd, logits, mem_per_token)) {
|
||||
printf("Failed to predict\n");
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_predict_us += ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
n_past += embd.size();
|
||||
embd.clear();
|
||||
|
||||
if (i >= embd_inp.size()) {
|
||||
// sample next token
|
||||
const int top_k = params.top_k;
|
||||
const float top_p = params.top_p;
|
||||
const float temp = params.temp;
|
||||
|
||||
const int n_vocab = model.hparams.n_vocab;
|
||||
|
||||
gpt_vocab::id id = 0;
|
||||
|
||||
{
|
||||
const int64_t t_start_sample_us = ggml_time_us();
|
||||
|
||||
id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng);
|
||||
|
||||
t_sample_us += ggml_time_us() - t_start_sample_us;
|
||||
}
|
||||
|
||||
// add it to the context
|
||||
embd.push_back(id);
|
||||
} else {
|
||||
// if here, it means we are still processing the input prompt
|
||||
for (int k = i; k < embd_inp.size(); k++) {
|
||||
embd.push_back(embd_inp[k]);
|
||||
if (embd.size() > params.n_batch) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
i += embd.size() - 1;
|
||||
}
|
||||
|
||||
// display text
|
||||
for (auto id : embd) {
|
||||
printf("%s", vocab.id_to_token[id].c_str());
|
||||
}
|
||||
fflush(stdout);
|
||||
|
||||
// end of text token
|
||||
if (embd.back() == 0) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n\n");
|
||||
printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token);
|
||||
printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f);
|
||||
printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f);
|
||||
printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us/1000.0f, t_predict_us/1000.0f/n_past);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f);
|
||||
}
|
||||
|
||||
ggml_free(model.ctx);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,178 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
#include "common-ggml.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <regex>
|
||||
|
||||
// default hparams (StableLM 3B)
|
||||
struct gpt_neox_hparams {
|
||||
int32_t n_vocab = 50257;
|
||||
int32_t n_ctx = 4096;
|
||||
int32_t n_embd = 4096;
|
||||
int32_t n_head = 32;
|
||||
int32_t n_layer = 16;
|
||||
int32_t n_rot = 32; // 0.25 * (n_embd / n_head)
|
||||
int32_t par_res = 1; // 1 = true, 0 = false
|
||||
int32_t ftype = 1;
|
||||
};
|
||||
|
||||
// quantize a model
|
||||
bool gpt_neox_model_quantize(const std::string & fname_inp, const std::string & fname_out, ggml_ftype ftype) {
|
||||
gpt_vocab vocab;
|
||||
|
||||
printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str());
|
||||
|
||||
auto finp = std::ifstream(fname_inp, std::ios::binary);
|
||||
if (!finp) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto fout = std::ofstream(fname_out, std::ios::binary);
|
||||
if (!fout) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname_out.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
finp.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
fout.write((char *) &magic, sizeof(magic));
|
||||
}
|
||||
|
||||
gpt_neox_hparams hparams;
|
||||
|
||||
// load hparams
|
||||
{
|
||||
finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
finp.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
finp.read((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
finp.read((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
finp.read((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
finp.read((char *) &hparams.n_rot, sizeof(hparams.n_rot));
|
||||
finp.read((char *) &hparams.par_res, sizeof(hparams.par_res));
|
||||
finp.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype;
|
||||
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx);
|
||||
printf("%s: n_embd = %d\n", __func__, hparams.n_embd);
|
||||
printf("%s: n_head = %d\n", __func__, hparams.n_head);
|
||||
printf("%s: n_layer = %d\n", __func__, hparams.n_layer);
|
||||
printf("%s: par_res = %d\n", __func__, hparams.par_res);
|
||||
printf("%s: ftype (src) = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr (src) = %d\n", __func__, qntvr_src);
|
||||
printf("%s: ftype (dst) = %d\n", __func__, ftype_dst);
|
||||
printf("%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION);
|
||||
|
||||
fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fout.write((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
fout.write((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
fout.write((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
fout.write((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
fout.write((char *) &hparams.n_rot, sizeof(hparams.n_rot));
|
||||
fout.write((char *) &hparams.par_res, sizeof(hparams.par_res));
|
||||
fout.write((char *) &ftype_dst, sizeof(ftype_dst));
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
const int32_t n_vocab = hparams.n_vocab;
|
||||
|
||||
std::string word;
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
finp.read ((char *) &len, sizeof(len));
|
||||
fout.write((char *) &len, sizeof(len));
|
||||
|
||||
word.resize(len);
|
||||
finp.read ((char *) word.data(), len);
|
||||
fout.write((char *) word.data(), len);
|
||||
|
||||
vocab.token_to_id[word] = i;
|
||||
vocab.id_to_token[i] = word;
|
||||
}
|
||||
}
|
||||
|
||||
// regexes of tensor names to be quantized
|
||||
const std::vector<std::string> to_quant = {
|
||||
".*weight",
|
||||
};
|
||||
|
||||
if (!ggml_common_quantize_0(finp, fout, ftype, to_quant, {})) {
|
||||
fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
finp.close();
|
||||
fout.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// usage:
|
||||
// ./gpt-neox-quantize models/stalellm2-117M/ggml-model.bin models/stablelm2-117M/ggml-model-quant.bin type
|
||||
//
|
||||
int main(int argc, char ** argv) {
|
||||
if (argc != 4) {
|
||||
fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n", argv[0]);
|
||||
ggml_print_ftypes(stderr);
|
||||
return 1;
|
||||
}
|
||||
|
||||
// needed to initialize f16 tables
|
||||
{
|
||||
struct ggml_init_params params = { 0, NULL, false };
|
||||
struct ggml_context * ctx = ggml_init(params);
|
||||
ggml_free(ctx);
|
||||
}
|
||||
|
||||
const std::string fname_inp = argv[1];
|
||||
const std::string fname_out = argv[2];
|
||||
|
||||
const ggml_ftype ftype = ggml_parse_ftype(argv[3]);
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
int64_t t_quantize_us = 0;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!gpt_neox_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) {
|
||||
fprintf(stderr, "%s: failed to quantize model from '%s'\n", __func__, fname_inp.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_quantize_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n");
|
||||
printf("%s: quantize time = %8.2f ms\n", __func__, t_quantize_us/1000.0f);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,7 @@
|
|||
#
|
||||
# mnist
|
||||
|
||||
set(TEST_TARGET mnist)
|
||||
add_executable(${TEST_TARGET} main.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common)
|
||||
|
||||
|
|
@ -0,0 +1,104 @@
|
|||
# MNIST Example for GGML
|
||||
|
||||
This is a simple example of how to use GGML for inferencing.
|
||||
|
||||
## Training the Model
|
||||
|
||||
A Google Colab notebook for training a simple two-layer network to recognize digits is located here. You can
|
||||
use this to save a pytorch model to be converted to ggml format.
|
||||
|
||||
[Colab](https://colab.research.google.com/drive/12n_8VNJnolBnX5dVS0HNWubnOjyEaFSb?usp=sharing)
|
||||
|
||||
|
||||
## GGML Format Conversion
|
||||
|
||||
GGML "format" is whatever you choose for efficient loading. In our case, we just save the hyperparameters used
|
||||
plus the model weights and biases. Run convert-h5-to-ggml.py to convert your pytorch model. The output format is:
|
||||
|
||||
- magic constant (int32)
|
||||
- repeated list of tensors
|
||||
- number of dimensions of tensor (int32)
|
||||
- tensor dimension (int32 repeated)
|
||||
- values of tensor (int32)
|
||||
|
||||
Run ```convert-h5-to-ggml.py mnist_model.state_dict``` where `mnist_model.state_dict` is the saved pytorch model from the Google Colab. For
|
||||
quickstart, it is included in the mnist/models directory.
|
||||
|
||||
## MNIST Network
|
||||
|
||||
The MNIST recognizer network is extremely simple. A fully connected layer + relu, followed by a fully connected layer + softmax. This
|
||||
version of the MNIST network doesn't use convolutions.
|
||||
|
||||
## Running the example
|
||||
|
||||
Here is how to run the example programs:
|
||||
|
||||
```bash
|
||||
# Build ggml + examples
|
||||
git clone https://github.com/ggerganov/ggml
|
||||
cd ggml
|
||||
mkdir build && cd build
|
||||
cmake ..
|
||||
make -j4 mnist
|
||||
|
||||
# Run the MNIST model
|
||||
./bin/mnist ../examples/mnist/models/mnist/ggml-model-f32.bin ../examples/mnist/models/mnist/t10k-images.idx3-ubyte
|
||||
```
|
||||
|
||||
For more information, checkout the corresponding programs in the [examples](examples) folder.
|
||||
|
||||
# Sample output
|
||||
|
||||
|
||||
```
|
||||
$ ./bin/mnist ./models/mnist/ggml-model-f32.bin ../examples/mnist/models/mnist/t10k-images.idx3-ubyte
|
||||
mnist_model_load: loading model from './models/mnist/ggml-model-f32.bin'
|
||||
mnist_model_load: ggml ctx size = 1.52 MB
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ * * * * _ _ _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ * * * _ _ _ * _ * * _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ * * _ _ _ _ _ * _ * _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ * * _ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ * * _ _ _ _ _ _ * * * * _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ * * _ _ _ _ _ _ _ * * * * _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ * * _ _ _ _ _ * * _ _ * * _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ * * _ _ _ _ * * _ _ _ _ * _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ * * * * * * _ _ _ _ _ _ * _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ * _ _ _ _ _ _ _ _ _ * _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ * _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ * * _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ * * _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ * * _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ * * _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ * _ _ * * * _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ * * * * * _ _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
|
||||
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
|
||||
|
||||
ggml_graph_dump_dot: dot -Tpng mnist.dot -o mnist.dot.png && open mnist.dot.png
|
||||
Predicted digit is 9
|
||||
```
|
||||
|
||||
Computation graph:
|
||||
|
||||
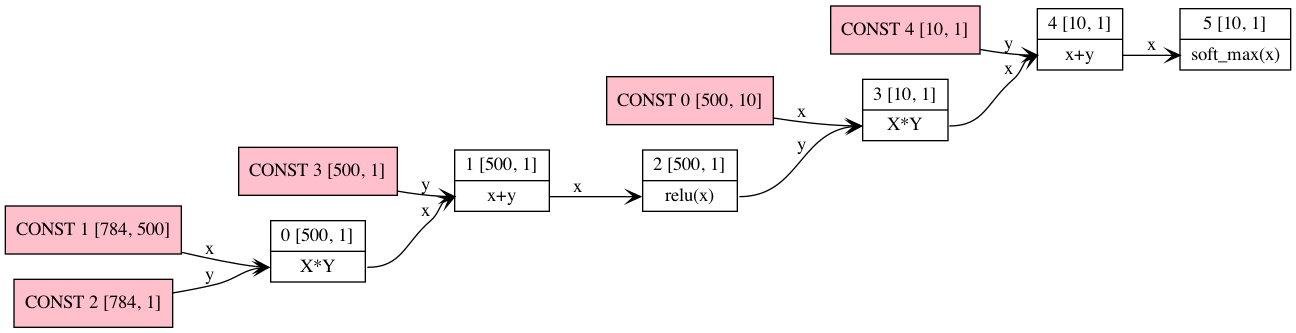
|
||||
|
||||
|
||||
## Web demo
|
||||
|
||||
The example can be compiled with Emscripten like this:
|
||||
|
||||
```bash
|
||||
cd examples/mnist
|
||||
emcc -I../../include -I../../include/ggml -I../../examples ../../src/ggml.c main.cpp -o web/mnist.js -s EXPORTED_FUNCTIONS='["_wasm_eval","_wasm_random_digit","_malloc","_free"]' -s EXPORTED_RUNTIME_METHODS='["ccall"]' -s ALLOW_MEMORY_GROWTH=1 --preload-file models/mnist
|
||||
```
|
||||
|
||||
Online demo: https://mnist.ggerganov.com
|
||||
|
|
@ -0,0 +1,63 @@
|
|||
# Convert MNIS h5 transformer model to ggml format
|
||||
#
|
||||
# Load the (state_dict) saved model using PyTorch
|
||||
# Iterate over all variables and write them to a binary file.
|
||||
#
|
||||
# For each variable, write the following:
|
||||
# - Number of dimensions (int)
|
||||
# - Name length (int)
|
||||
# - Dimensions (int[n_dims])
|
||||
# - Name (char[name_length])
|
||||
# - Data (float[n_dims])
|
||||
#
|
||||
# At the start of the ggml file we write the model parameters
|
||||
|
||||
import sys
|
||||
import struct
|
||||
import json
|
||||
import numpy as np
|
||||
import re
|
||||
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torchvision.datasets as dsets
|
||||
import torchvision.transforms as transforms
|
||||
from torch.autograd import Variable
|
||||
|
||||
if len(sys.argv) != 2:
|
||||
print("Usage: convert-h5-to-ggml.py model\n")
|
||||
sys.exit(1)
|
||||
|
||||
state_dict_file = sys.argv[1]
|
||||
fname_out = "models/mnist/ggml-model-f32.bin"
|
||||
|
||||
state_dict = torch.load(state_dict_file, map_location=torch.device('cpu'))
|
||||
#print (model)
|
||||
|
||||
list_vars = state_dict
|
||||
print (list_vars)
|
||||
|
||||
fout = open(fname_out, "wb")
|
||||
|
||||
fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex
|
||||
|
||||
|
||||
for name in list_vars.keys():
|
||||
data = list_vars[name].squeeze().numpy()
|
||||
print("Processing variable: " + name + " with shape: ", data.shape)
|
||||
n_dims = len(data.shape);
|
||||
|
||||
fout.write(struct.pack("i", n_dims))
|
||||
|
||||
data = data.astype(np.float32)
|
||||
for i in range(n_dims):
|
||||
fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
|
||||
|
||||
# data
|
||||
data.tofile(fout)
|
||||
|
||||
fout.close()
|
||||
|
||||
print("Done. Output file: " + fname_out)
|
||||
print("")
|
||||
|
|
@ -0,0 +1,308 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <ctime>
|
||||
#include <fstream>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <algorithm>
|
||||
|
||||
// default hparams
|
||||
struct mnist_hparams {
|
||||
int32_t n_input = 784;
|
||||
int32_t n_hidden = 500;
|
||||
int32_t n_classes = 10;
|
||||
};
|
||||
|
||||
struct mnist_model {
|
||||
mnist_hparams hparams;
|
||||
|
||||
struct ggml_tensor * fc1_weight;
|
||||
struct ggml_tensor * fc1_bias;
|
||||
|
||||
struct ggml_tensor * fc2_weight;
|
||||
struct ggml_tensor * fc2_bias;
|
||||
|
||||
struct ggml_context * ctx;
|
||||
};
|
||||
|
||||
// load the model's weights from a file
|
||||
bool mnist_model_load(const std::string & fname, mnist_model & model) {
|
||||
printf("%s: loading model from '%s'\n", __func__, fname.c_str());
|
||||
|
||||
auto fin = std::ifstream(fname, std::ios::binary);
|
||||
if (!fin) {
|
||||
fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
fin.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
auto & ctx = model.ctx;
|
||||
|
||||
size_t ctx_size = 0;
|
||||
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_input = hparams.n_input;
|
||||
const int n_hidden = hparams.n_hidden;
|
||||
const int n_classes = hparams.n_classes;
|
||||
|
||||
ctx_size += n_input * n_hidden * ggml_type_sizef(GGML_TYPE_F32); // fc1 weight
|
||||
ctx_size += n_hidden * ggml_type_sizef(GGML_TYPE_F32); // fc1 bias
|
||||
|
||||
ctx_size += n_hidden * n_classes * ggml_type_sizef(GGML_TYPE_F32); // fc2 weight
|
||||
ctx_size += n_classes * ggml_type_sizef(GGML_TYPE_F32); // fc2 bias
|
||||
|
||||
printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0));
|
||||
}
|
||||
|
||||
// create the ggml context
|
||||
{
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = ctx_size + 1024*1024,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
model.ctx = ggml_init(params);
|
||||
if (!model.ctx) {
|
||||
fprintf(stderr, "%s: ggml_init() failed\n", __func__);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// Read FC1 layer 1
|
||||
{
|
||||
// Read dimensions
|
||||
int32_t n_dims;
|
||||
fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
|
||||
|
||||
{
|
||||
int32_t ne_weight[2] = { 1, 1 };
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
fin.read(reinterpret_cast<char *>(&ne_weight[i]), sizeof(ne_weight[i]));
|
||||
}
|
||||
|
||||
// FC1 dimensions taken from file, eg. 768x500
|
||||
model.hparams.n_input = ne_weight[0];
|
||||
model.hparams.n_hidden = ne_weight[1];
|
||||
|
||||
model.fc1_weight = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, model.hparams.n_input, model.hparams.n_hidden);
|
||||
fin.read(reinterpret_cast<char *>(model.fc1_weight->data), ggml_nbytes(model.fc1_weight));
|
||||
ggml_set_name(model.fc1_weight, "fc1_weight");
|
||||
}
|
||||
|
||||
{
|
||||
int32_t ne_bias[2] = { 1, 1 };
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
fin.read(reinterpret_cast<char *>(&ne_bias[i]), sizeof(ne_bias[i]));
|
||||
}
|
||||
|
||||
model.fc1_bias = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, model.hparams.n_hidden);
|
||||
fin.read(reinterpret_cast<char *>(model.fc1_bias->data), ggml_nbytes(model.fc1_bias));
|
||||
ggml_set_name(model.fc1_bias, "fc1_bias");
|
||||
}
|
||||
}
|
||||
|
||||
// Read FC2 layer 2
|
||||
{
|
||||
// Read dimensions
|
||||
int32_t n_dims;
|
||||
fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
|
||||
|
||||
{
|
||||
int32_t ne_weight[2] = { 1, 1 };
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
fin.read(reinterpret_cast<char *>(&ne_weight[i]), sizeof(ne_weight[i]));
|
||||
}
|
||||
|
||||
// FC1 dimensions taken from file, eg. 10x500
|
||||
model.hparams.n_classes = ne_weight[1];
|
||||
|
||||
model.fc2_weight = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, model.hparams.n_hidden, model.hparams.n_classes);
|
||||
fin.read(reinterpret_cast<char *>(model.fc2_weight->data), ggml_nbytes(model.fc2_weight));
|
||||
ggml_set_name(model.fc2_weight, "fc2_weight");
|
||||
}
|
||||
|
||||
{
|
||||
int32_t ne_bias[2] = { 1, 1 };
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
fin.read(reinterpret_cast<char *>(&ne_bias[i]), sizeof(ne_bias[i]));
|
||||
}
|
||||
|
||||
model.fc2_bias = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, model.hparams.n_classes);
|
||||
fin.read(reinterpret_cast<char *>(model.fc2_bias->data), ggml_nbytes(model.fc2_bias));
|
||||
ggml_set_name(model.fc2_bias, "fc2_bias");
|
||||
}
|
||||
}
|
||||
|
||||
fin.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// evaluate the model
|
||||
//
|
||||
// - model: the model
|
||||
// - n_threads: number of threads to use
|
||||
// - digit: 784 pixel values
|
||||
//
|
||||
// returns 0 - 9 prediction
|
||||
int mnist_eval(
|
||||
const mnist_model & model,
|
||||
const int n_threads,
|
||||
std::vector<float> digit
|
||||
) {
|
||||
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
static size_t buf_size = hparams.n_input * sizeof(float) * 4;
|
||||
static void * buf = malloc(buf_size);
|
||||
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = buf_size,
|
||||
.mem_buffer = buf,
|
||||
};
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
struct ggml_cgraph gf = {};
|
||||
gf.n_threads = n_threads;
|
||||
|
||||
struct ggml_tensor * input = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, hparams.n_input);
|
||||
memcpy(input->data, digit.data(), ggml_nbytes(input));
|
||||
ggml_set_name(input, "input");
|
||||
|
||||
// fc1 MLP = Ax + b
|
||||
ggml_tensor * fc1 = ggml_add(ctx0, ggml_mul_mat(ctx0, model.fc1_weight, input), model.fc1_bias);
|
||||
ggml_tensor * fc2 = ggml_add(ctx0, ggml_mul_mat(ctx0, model.fc2_weight, ggml_relu(ctx0, fc1)), model.fc2_bias);
|
||||
|
||||
// soft max
|
||||
ggml_tensor * probs = ggml_soft_max(ctx0, fc2);
|
||||
|
||||
// run the computation
|
||||
ggml_build_forward_expand(&gf, probs);
|
||||
ggml_graph_compute (ctx0, &gf);
|
||||
|
||||
//ggml_graph_print (&gf);
|
||||
ggml_graph_dump_dot(&gf, NULL, "mnist.dot");
|
||||
|
||||
const float * probs_data = ggml_get_data_f32(probs);
|
||||
|
||||
const int prediction = std::max_element(probs_data, probs_data + 10) - probs_data;
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
return prediction;
|
||||
}
|
||||
|
||||
#ifdef __cplusplus
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
int wasm_eval(uint8_t *digitPtr)
|
||||
{
|
||||
mnist_model model;
|
||||
if (!mnist_model_load("models/mnist/ggml-model-f32.bin", model)) {
|
||||
fprintf(stderr, "error loading model\n");
|
||||
return -1;
|
||||
}
|
||||
std::vector<float> digit(digitPtr, digitPtr + 784);
|
||||
int result = mnist_eval(model, 1, digit);
|
||||
ggml_free(model.ctx);
|
||||
return result;
|
||||
}
|
||||
|
||||
int wasm_random_digit(char *digitPtr)
|
||||
{
|
||||
auto fin = std::ifstream("models/mnist/t10k-images.idx3-ubyte", std::ios::binary);
|
||||
if (!fin) {
|
||||
fprintf(stderr, "failed to open digits file\n");
|
||||
return 0;
|
||||
}
|
||||
srand(time(NULL));
|
||||
// Seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000)
|
||||
fin.seekg(16 + 784 * (rand() % 10000));
|
||||
fin.read(digitPtr, 784);
|
||||
return 1;
|
||||
}
|
||||
|
||||
#ifdef __cplusplus
|
||||
}
|
||||
#endif
|
||||
|
||||
int main(int argc, char ** argv) {
|
||||
srand(time(NULL));
|
||||
ggml_time_init();
|
||||
|
||||
if (argc != 3) {
|
||||
fprintf(stderr, "Usage: %s models/mnist/ggml-model-f32.bin models/mnist/t10k-images.idx3-ubyte\n", argv[0]);
|
||||
exit(0);
|
||||
}
|
||||
|
||||
uint8_t buf[784];
|
||||
mnist_model model;
|
||||
std::vector<float> digit;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!mnist_model_load(argv[1], model)) {
|
||||
fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, "models/ggml-model-f32.bin");
|
||||
return 1;
|
||||
}
|
||||
|
||||
const int64_t t_load_us = ggml_time_us() - t_start_us;
|
||||
|
||||
fprintf(stdout, "%s: loaded model in %8.2f ms\n", __func__, t_load_us / 1000.0f);
|
||||
}
|
||||
|
||||
// read a random digit from the test set
|
||||
{
|
||||
std::ifstream fin(argv[2], std::ios::binary);
|
||||
if (!fin) {
|
||||
fprintf(stderr, "%s: failed to open '%s'\n", __func__, argv[2]);
|
||||
return 1;
|
||||
}
|
||||
|
||||
// seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000)
|
||||
fin.seekg(16 + 784 * (rand() % 10000));
|
||||
fin.read((char *) &buf, sizeof(buf));
|
||||
}
|
||||
|
||||
// render the digit in ASCII
|
||||
{
|
||||
digit.resize(sizeof(buf));
|
||||
|
||||
for (int row = 0; row < 28; row++) {
|
||||
for (int col = 0; col < 28; col++) {
|
||||
fprintf(stderr, "%c ", (float)buf[row*28 + col] > 230 ? '*' : '_');
|
||||
digit[row*28 + col] = ((float)buf[row*28 + col]);
|
||||
}
|
||||
|
||||
fprintf(stderr, "\n");
|
||||
}
|
||||
|
||||
fprintf(stderr, "\n");
|
||||
}
|
||||
|
||||
fprintf(stdout, "%s: predicted digit is %d\n", __func__, mnist_eval(model, 1, digit));
|
||||
|
||||
ggml_free(model.ctx);
|
||||
|
||||
return 0;
|
||||
}
|
||||
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,178 @@
|
|||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<meta charset="utf-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
|
||||
<title>MNIST with GGML</title>
|
||||
<script src="mnist.js"></script>
|
||||
</head>
|
||||
<body>
|
||||
<h2>MNIST digit recognizer with <a href="https://github.com/ggerganov/ggml">GGML</a></h2>
|
||||
<p id="msg">Loading model and data set, please wait ...</p>
|
||||
<canvas id="ggCanvas" width="364" height="364" style="border:2px solid #d3d3d3;">
|
||||
Your browser does not support the HTML canvas tag.
|
||||
</canvas>
|
||||
<div>
|
||||
<button id="clear" onclick="onClear()">Clear</button>
|
||||
<button id="random" onclick="onRandom()" disabled>Random</button>
|
||||
<button id="download" onclick="onDownload()">Download</button>
|
||||
</div>
|
||||
<div>
|
||||
<p id="prediction"></p>
|
||||
</div>
|
||||
<script>
|
||||
"use strict";
|
||||
const DIGIT_SIZE = 28; // digits are 28x28 pixels
|
||||
var canvas = document.getElementById("ggCanvas");
|
||||
var ctx = canvas.getContext("2d", { alpha: false, willReadFrequently: true });
|
||||
ctx.fillStyle = "white";
|
||||
ctx.fillRect(0, 0, canvas.width, canvas.height);
|
||||
var dragging = false;
|
||||
var lastX, lastY;
|
||||
|
||||
function onClear(event) {
|
||||
ctx.fillStyle = "white";
|
||||
ctx.fillRect(0, 0, canvas.width, canvas.height);
|
||||
document.getElementById("prediction").innerHTML = "";
|
||||
}
|
||||
|
||||
function predict(digit) {
|
||||
let buf = Module._malloc(digit.length);
|
||||
if (buf == 0) {
|
||||
console.log("failed to allocate memory");
|
||||
return;
|
||||
}
|
||||
Module.HEAPU8.set(digit, buf);
|
||||
let prediction = Module.ccall('wasm_eval', null, ['number'], [buf]);
|
||||
Module._free(buf);
|
||||
if (prediction >= 0) {
|
||||
document.getElementById("prediction").innerHTML = "Predicted digit is <b>" + prediction + "</b>";
|
||||
}
|
||||
}
|
||||
|
||||
function onRandom(event) {
|
||||
onClear();
|
||||
const bufLength = DIGIT_SIZE*DIGIT_SIZE;
|
||||
var buf = Module._malloc(bufLength);
|
||||
if (buf == 0) {
|
||||
console.log("failed to allocate memory");
|
||||
return;
|
||||
}
|
||||
let ret = Module.ccall('wasm_random_digit', null, ['number'], [buf]);
|
||||
let digit = new Uint8Array(Module.HEAPU8.buffer, buf, bufLength);
|
||||
for (let i = 0; i < digit.length; i++) {
|
||||
let x = i % DIGIT_SIZE;
|
||||
let y = Math.floor(i / DIGIT_SIZE);
|
||||
setPixel(x, y, digit[i]);
|
||||
}
|
||||
Module._free(buf);
|
||||
predict(digit);
|
||||
}
|
||||
|
||||
function onDownload(event) {
|
||||
let digit = scaleCanvas();
|
||||
let digitBlob = new Blob([new Uint8Array(digit)], {type: "application/octet-stream"});
|
||||
let url = URL.createObjectURL(digitBlob);
|
||||
let link = document.createElement('a');
|
||||
link.href = url;
|
||||
link.download = "image.raw";
|
||||
document.body.appendChild(link);
|
||||
link.click();
|
||||
document.body.removeChild(link);
|
||||
}
|
||||
|
||||
// Get the position of the mouse relative to the canvas
|
||||
function getMousePos(event) {
|
||||
if (event.touches !== undefined && event.touches.length > 0) {
|
||||
event = event.touches[0];
|
||||
}
|
||||
var rect = canvas.getBoundingClientRect();
|
||||
return [Math.floor(event.clientX) - rect.left, Math.floor(event.clientY) - rect.top];
|
||||
}
|
||||
|
||||
function setPixel(x, y, val) {
|
||||
let canvasX = x * 13;
|
||||
let canvasY = y * 13;
|
||||
let color = 255 - val;
|
||||
ctx.fillStyle = "#" + color.toString(16) + color.toString(16) + color.toString(16);
|
||||
ctx.fillRect(canvasX, canvasY, 13, 13);
|
||||
}
|
||||
|
||||
function onMouseDown(e) {
|
||||
dragging = true;
|
||||
[lastX, lastY] = getMousePos(e);
|
||||
}
|
||||
|
||||
// scale the canvas to 28x28 pixels and return the pixel values as an array
|
||||
function scaleCanvas() {
|
||||
let imgData = ctx.getImageData(0, 0, canvas.width, canvas.height);
|
||||
let tempCanvas = document.createElement('canvas');
|
||||
tempCanvas.width = DIGIT_SIZE;
|
||||
tempCanvas.height = DIGIT_SIZE;
|
||||
let tempCtx = tempCanvas.getContext("2d");
|
||||
tempCtx.drawImage(canvas, 0, 0, DIGIT_SIZE, DIGIT_SIZE);
|
||||
let tempImgData = tempCtx.getImageData(0, 0, DIGIT_SIZE, DIGIT_SIZE);
|
||||
let tempData = tempImgData.data;
|
||||
let digit = new Array(DIGIT_SIZE*DIGIT_SIZE).fill(0);
|
||||
for (let i = 0; i < tempData.length; i += 4) {
|
||||
let val = 255 - tempData[i];
|
||||
digit[i / 4] = val;
|
||||
}
|
||||
return digit;
|
||||
}
|
||||
|
||||
function onMouseUp(e) {
|
||||
dragging = false;
|
||||
let digit = scaleCanvas();
|
||||
predict(digit);
|
||||
}
|
||||
|
||||
function onMouseMove(e) {
|
||||
if (dragging) {
|
||||
let [mouseX, mouseY] = getMousePos(e);
|
||||
ctx.beginPath();
|
||||
ctx.moveTo(lastX, lastY);
|
||||
ctx.lineTo(mouseX, mouseY);
|
||||
ctx.lineWidth = 20;
|
||||
ctx.lineJoin = ctx.lineCap = 'round';
|
||||
ctx.strokeStyle = "#000000";
|
||||
ctx.stroke();
|
||||
ctx.closePath();
|
||||
lastX = mouseX;
|
||||
lastY = mouseY;
|
||||
}
|
||||
}
|
||||
|
||||
// Prevent scrolling when touching the canvas
|
||||
document.body.addEventListener("touchstart", function (e) {
|
||||
if (e.target == canvas) {
|
||||
e.preventDefault();
|
||||
}
|
||||
}, {passive: false});
|
||||
document.body.addEventListener("touchend", function (e) {
|
||||
if (e.target == canvas) {
|
||||
e.preventDefault();
|
||||
}
|
||||
}, {passive: false});
|
||||
document.body.addEventListener("touchmove", function (e) {
|
||||
if (e.target == canvas) {
|
||||
e.preventDefault();
|
||||
}
|
||||
}, {passive: false});
|
||||
|
||||
function onRuntimeInitialized() {
|
||||
// Use the same handlers for mouse and touch events
|
||||
canvas.onmousedown = onMouseDown;
|
||||
canvas.onmouseup = onMouseUp;
|
||||
canvas.onmousemove = onMouseMove;
|
||||
canvas.ontouchstart = onMouseDown;
|
||||
canvas.ontouchend = onMouseUp;
|
||||
canvas.ontouchmove = onMouseMove;
|
||||
document.getElementById("msg").innerHTML = "Draw a single digit on the canvas below:"
|
||||
document.getElementById("random").disabled = false;
|
||||
}
|
||||
|
||||
Module['onRuntimeInitialized'] = onRuntimeInitialized;
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
#
|
||||
# mpt
|
||||
|
||||
set(TEST_TARGET mpt)
|
||||
add_executable(${TEST_TARGET} main.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
||||
#
|
||||
# mpt-quantize
|
||||
|
||||
set(TEST_TARGET mpt-quantize)
|
||||
add_executable(${TEST_TARGET} quantize.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
|
@ -0,0 +1,158 @@
|
|||
import sys
|
||||
import struct
|
||||
import json
|
||||
import numpy as np
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
import sentencepiece.sentencepiece_model_pb2 as model
|
||||
|
||||
# ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py
|
||||
def bytes_to_unicode():
|
||||
|
||||
"""
|
||||
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
||||
The reversible bpe codes work on unicode strings.
|
||||
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
||||
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
||||
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
||||
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
||||
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
||||
"""
|
||||
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
|
||||
cs = bs[:]
|
||||
n = 0
|
||||
for b in range(2**8):
|
||||
if b not in bs:
|
||||
bs.append(b)
|
||||
cs.append(2**8+n)
|
||||
n += 1
|
||||
|
||||
cs = [chr(n) for n in cs]
|
||||
|
||||
return dict(zip(bs, cs))
|
||||
|
||||
if len(sys.argv) < 3:
|
||||
print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n")
|
||||
print(" ftype == 0 -> float32")
|
||||
print(" ftype == 1 -> float16")
|
||||
sys.exit(1)
|
||||
|
||||
|
||||
# output in the same directory as the model
|
||||
dir_model = sys.argv[1]
|
||||
fname_out = sys.argv[1] + "/ggml-model.bin"
|
||||
|
||||
|
||||
with open(dir_model + "/config.json", "r", encoding="utf-8") as f:
|
||||
hparams = json.load(f)
|
||||
|
||||
# possible data types
|
||||
# ftype == 0 -> float32
|
||||
# ftype == 1 -> float16
|
||||
#
|
||||
# map from ftype to string
|
||||
ftype_str = ["f32", "f16"]
|
||||
|
||||
ftype = 1
|
||||
if len(sys.argv) > 2:
|
||||
ftype = int(sys.argv[2])
|
||||
if ftype < 0 or ftype > 1:
|
||||
print("Invalid ftype: " + str(ftype))
|
||||
sys.exit(1)
|
||||
fname_out = sys.argv[1] + "/ggml-model-" + ftype_str[ftype] + ".bin"
|
||||
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(dir_model, trust_remote_code=True)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
dir_model, low_cpu_mem_usage=True, trust_remote_code=True
|
||||
)
|
||||
# print (model)
|
||||
|
||||
# print(tokenizer.encode('I believe the meaning of life is'))
|
||||
|
||||
list_vars = model.state_dict()
|
||||
for name in list_vars.keys():
|
||||
print(name, list_vars[name].shape, list_vars[name].dtype)
|
||||
|
||||
fout = open(fname_out, "wb")
|
||||
|
||||
print(hparams)
|
||||
|
||||
fout.write(struct.pack("i", 0x67676D6C)) # magic: ggml in hex
|
||||
fout.write(struct.pack("i", hparams["d_model"]))
|
||||
fout.write(struct.pack("i", hparams["max_seq_len"]))
|
||||
fout.write(struct.pack("i", hparams["n_heads"]))
|
||||
fout.write(struct.pack("i", hparams["n_layers"]))
|
||||
fout.write(struct.pack("i", hparams["vocab_size"]))
|
||||
fout.write(struct.pack("f", hparams["attn_config"]["alibi_bias_max"]))
|
||||
fout.write(struct.pack("f", hparams["attn_config"]["clip_qkv"] or 0.0))
|
||||
fout.write(struct.pack("i", ftype))
|
||||
|
||||
vocab_size = hparams["vocab_size"]
|
||||
|
||||
encoder = tokenizer.vocab
|
||||
# Add added_tokens (special tokens) to the encoder
|
||||
encoder.update(tokenizer.get_added_vocab())
|
||||
|
||||
byte_encoder = bytes_to_unicode()
|
||||
byte_decoder = {v:k for k, v in byte_encoder.items()}
|
||||
|
||||
counter = 0
|
||||
# sort by value
|
||||
for key in sorted(encoder, key=encoder.get):
|
||||
# workaround for key error when c not found
|
||||
text=""
|
||||
for c in key:
|
||||
if c not in byte_decoder:
|
||||
text += c
|
||||
else:
|
||||
text += chr(byte_decoder[c] )
|
||||
text = bytearray( text, encoding="utf-8" )
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
counter += 1
|
||||
|
||||
# Repeat last token until vocab_size
|
||||
while counter < vocab_size:
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
counter += 1
|
||||
|
||||
# assert counter == config.vocab_size
|
||||
|
||||
for name in list_vars.keys():
|
||||
data = list_vars[name].squeeze().numpy()
|
||||
print("Processing variable: " + name + " with shape: ", data.shape)
|
||||
|
||||
n_dims = len(data.shape)
|
||||
|
||||
# ftype == 0 -> float32, ftype == 1 -> float16
|
||||
ftype_cur = 0
|
||||
if ftype != 0:
|
||||
if name[-7:] == ".weight" and n_dims == 2:
|
||||
print(" Converting to float16")
|
||||
data = data.astype(np.float16)
|
||||
ftype_cur = 1
|
||||
else:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype_cur = 0
|
||||
else:
|
||||
if data.dtype != np.float32:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype_cur = 0
|
||||
|
||||
# header
|
||||
str = name.encode("utf-8")
|
||||
fout.write(struct.pack("iii", n_dims, len(str), ftype_cur))
|
||||
for i in range(n_dims):
|
||||
fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
|
||||
fout.write(str)
|
||||
|
||||
# data
|
||||
data.tofile(fout)
|
||||
|
||||
fout.close()
|
||||
|
||||
print("Done. Output file: " + fname_out)
|
||||
print("")
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,186 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common-ggml.h"
|
||||
#include "common.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <regex>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
struct mpt_hparams {
|
||||
int32_t d_model = 0;
|
||||
int32_t max_seq_len = 0;
|
||||
int32_t n_heads = 0;
|
||||
int32_t n_layers = 0;
|
||||
int32_t n_vocab = 0;
|
||||
float alibi_bias_max = 0;
|
||||
float clip_qkv = 0;
|
||||
int32_t ftype = 0;
|
||||
};
|
||||
|
||||
// quantize a model
|
||||
bool mpt_model_quantize(const std::string & fname_inp,
|
||||
const std::string & fname_out, ggml_ftype ftype) {
|
||||
|
||||
printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str());
|
||||
|
||||
auto finp = std::ifstream(fname_inp, std::ios::binary);
|
||||
if (!finp) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__,
|
||||
fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto fout = std::ofstream(fname_out, std::ios::binary);
|
||||
if (!fout) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__,
|
||||
fname_out.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
finp.read((char *)&magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n",
|
||||
__func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
fout.write((char *)&magic, sizeof(magic));
|
||||
}
|
||||
|
||||
mpt_hparams hparams;
|
||||
|
||||
// load hparams
|
||||
{
|
||||
finp.read((char *) &hparams.d_model, sizeof(hparams.d_model));
|
||||
finp.read((char *) &hparams.max_seq_len, sizeof(hparams.max_seq_len));
|
||||
finp.read((char *) &hparams.n_heads, sizeof(hparams.n_heads));
|
||||
finp.read((char *) &hparams.n_layers, sizeof(hparams.n_layers));
|
||||
finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
finp.read((char *) &hparams.alibi_bias_max, sizeof(hparams.alibi_bias_max));
|
||||
finp.read((char *) &hparams.clip_qkv, sizeof(hparams.clip_qkv));
|
||||
finp.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype;
|
||||
|
||||
printf("%s: d_model = %d\n", __func__, hparams.d_model);
|
||||
printf("%s: max_seq_len = %d\n", __func__, hparams.max_seq_len);
|
||||
printf("%s: n_heads = %d\n", __func__, hparams.n_heads);
|
||||
printf("%s: n_layers = %d\n", __func__, hparams.n_layers);
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: alibi_bias_max = %f\n", __func__, hparams.alibi_bias_max);
|
||||
printf("%s: clip_qkv = %f\n", __func__, hparams.clip_qkv);
|
||||
printf("%s: ftype (src) = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr (src) = %d\n", __func__, qntvr_src);
|
||||
printf("%s: ftype (dst) = %d\n", __func__, ftype_dst);
|
||||
printf("%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION);
|
||||
|
||||
fout.write((char *) &hparams.d_model, sizeof(hparams.d_model));
|
||||
fout.write((char *) &hparams.max_seq_len, sizeof(hparams.max_seq_len));
|
||||
fout.write((char *) &hparams.n_heads, sizeof(hparams.n_heads));
|
||||
fout.write((char *) &hparams.n_layers, sizeof(hparams.n_layers));
|
||||
fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fout.write((char *) &hparams.alibi_bias_max, sizeof(hparams.alibi_bias_max));
|
||||
fout.write((char *) &hparams.clip_qkv, sizeof(hparams.clip_qkv));
|
||||
fout.write((char *) &ftype_dst, sizeof(ftype_dst));
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
const int32_t n_vocab = hparams.n_vocab;
|
||||
|
||||
std::string word;
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
finp.read((char *)&len, sizeof(len));
|
||||
fout.write((char *)&len, sizeof(len));
|
||||
|
||||
word.resize(len);
|
||||
finp.read((char *)word.data(), len);
|
||||
fout.write((char *)word.data(), len);
|
||||
}
|
||||
}
|
||||
|
||||
printf("%s: quantizing tensors\n", __func__);
|
||||
|
||||
// regexes of tensor names to be quantized
|
||||
const std::vector<std::string> to_quant = {
|
||||
".*weight",
|
||||
};
|
||||
|
||||
if (!ggml_common_quantize_0(finp, fout, ftype, to_quant, {})) {
|
||||
fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__,
|
||||
fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
finp.close();
|
||||
fout.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// usage:
|
||||
// ./mpt-quantize models/mpt/ggml-model.bin
|
||||
// models/mpt/ggml-model-quant.bin type
|
||||
//
|
||||
int main(int argc, char ** argv) {
|
||||
if (argc != 4) {
|
||||
fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n",
|
||||
argv[0]);
|
||||
ggml_print_ftypes(stderr);
|
||||
return 1;
|
||||
}
|
||||
|
||||
// needed to initialize f16 tables
|
||||
{
|
||||
struct ggml_init_params params = {0, NULL, false};
|
||||
struct ggml_context * ctx = ggml_init(params);
|
||||
ggml_free(ctx);
|
||||
}
|
||||
|
||||
const std::string fname_inp = argv[1];
|
||||
const std::string fname_out = argv[2];
|
||||
|
||||
const ggml_ftype ftype = ggml_parse_ftype(argv[3]);
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
int64_t t_quantize_us = 0;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!mpt_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) {
|
||||
fprintf(stderr, "%s: failed to quantize model from '%s'\n",
|
||||
__func__, fname_inp.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_quantize_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n");
|
||||
printf("%s: quantize time = %8.2f ms\n", __func__,
|
||||
t_quantize_us / 1000.0f);
|
||||
printf("%s: total time = %8.2f ms\n", __func__,
|
||||
(t_main_end_us - t_main_start_us) / 1000.0f);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
#
|
||||
# replit
|
||||
|
||||
set(TEST_TARGET replit)
|
||||
add_executable(${TEST_TARGET} main.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
||||
#
|
||||
# replit-quantize
|
||||
|
||||
set(TEST_TARGET replit-quantize)
|
||||
add_executable(${TEST_TARGET} quantize.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
|
@ -0,0 +1,113 @@
|
|||
from pathlib import Path
|
||||
import sys
|
||||
import struct
|
||||
import json
|
||||
import numpy as np
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
import sentencepiece.sentencepiece_model_pb2 as model
|
||||
|
||||
if len(sys.argv) < 3:
|
||||
print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n")
|
||||
print(" ftype == 0 -> float32")
|
||||
print(" ftype == 1 -> float16")
|
||||
sys.exit(1)
|
||||
|
||||
|
||||
# output in the same directory as the model
|
||||
dir_model = sys.argv[1]
|
||||
fname_out = sys.argv[1] + "/ggml-model.bin"
|
||||
|
||||
|
||||
with open(dir_model + "/config.json", "r", encoding="utf-8") as f:
|
||||
hparams = json.load(f)
|
||||
|
||||
sp_proto = model.ModelProto()
|
||||
sp_proto.ParseFromString(open(Path(sys.argv[1]) / "spiece.model", "rb").read())
|
||||
|
||||
|
||||
# possible data types
|
||||
# ftype == 0 -> float32
|
||||
# ftype == 1 -> float16
|
||||
#
|
||||
# map from ftype to string
|
||||
ftype_str = ["f32", "f16"]
|
||||
|
||||
ftype = 1
|
||||
if len(sys.argv) > 2:
|
||||
ftype = int(sys.argv[2])
|
||||
if ftype < 0 or ftype > 1:
|
||||
print("Invalid ftype: " + str(ftype))
|
||||
sys.exit(1)
|
||||
fname_out = sys.argv[1] + "/ggml-model-" + ftype_str[ftype] + ".bin"
|
||||
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(dir_model, trust_remote_code=True)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
dir_model, low_cpu_mem_usage=True, trust_remote_code=True
|
||||
)
|
||||
# print (model)
|
||||
|
||||
# print(tokenizer.encode('I believe the meaning of life is'))
|
||||
|
||||
list_vars = model.state_dict()
|
||||
for name in list_vars.keys():
|
||||
print(name, list_vars[name].shape, list_vars[name].dtype)
|
||||
|
||||
fout = open(fname_out, "wb")
|
||||
|
||||
print(hparams)
|
||||
|
||||
fout.write(struct.pack("i", 0x67676D6C)) # magic: ggml in hex
|
||||
fout.write(struct.pack("i", hparams["d_model"]))
|
||||
fout.write(struct.pack("i", hparams["max_seq_len"]))
|
||||
fout.write(struct.pack("i", hparams["n_heads"]))
|
||||
fout.write(struct.pack("i", hparams["n_layers"]))
|
||||
fout.write(struct.pack("i", hparams["vocab_size"]))
|
||||
fout.write(struct.pack("i", ftype))
|
||||
|
||||
|
||||
# TODO: temporary hack to not deal with implementing the tokenizer
|
||||
for piece in sp_proto.pieces:
|
||||
encoded_piece = piece.piece.encode("utf-8")
|
||||
fout.write(struct.pack("i", len(encoded_piece)))
|
||||
fout.write(encoded_piece)
|
||||
fout.write(struct.pack("f", piece.score))
|
||||
|
||||
|
||||
for name in list_vars.keys():
|
||||
data = list_vars[name].squeeze().numpy()
|
||||
print("Processing variable: " + name + " with shape: ", data.shape)
|
||||
|
||||
n_dims = len(data.shape)
|
||||
|
||||
# ftype == 0 -> float32, ftype == 1 -> float16
|
||||
ftype_cur = 0
|
||||
if ftype != 0:
|
||||
if name[-7:] == ".weight" and n_dims == 2:
|
||||
print(" Converting to float16")
|
||||
data = data.astype(np.float16)
|
||||
ftype_cur = 1
|
||||
else:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype_cur = 0
|
||||
else:
|
||||
if data.dtype != np.float32:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype_cur = 0
|
||||
|
||||
# header
|
||||
str = name.encode("utf-8")
|
||||
fout.write(struct.pack("iii", n_dims, len(str), ftype_cur))
|
||||
for i in range(n_dims):
|
||||
fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
|
||||
fout.write(str)
|
||||
|
||||
# data
|
||||
data.tofile(fout)
|
||||
|
||||
fout.close()
|
||||
|
||||
print("Done. Output file: " + fname_out)
|
||||
print("")
|
||||
|
|
@ -0,0 +1,767 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common-ggml.h"
|
||||
#include "common.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstddef>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <cinttypes>
|
||||
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <unordered_map>
|
||||
#include <utility>
|
||||
#include <vector>
|
||||
|
||||
using piece_t = std::pair<std::size_t, float>;
|
||||
using piece_map_t = std::unordered_map<std::string, piece_t>;
|
||||
|
||||
struct replit_tokenizer {
|
||||
gpt_vocab raw_vocab;
|
||||
piece_map_t piece_map;
|
||||
std::vector<std::string> vocab;
|
||||
};
|
||||
|
||||
std::pair<std::vector<std::size_t>, float> encode_word(const std::string & word, const piece_map_t & model) {
|
||||
std::vector<int> best_segmentations_starts(word.length() + 1, -1);
|
||||
best_segmentations_starts[0] = 0;
|
||||
|
||||
std::vector<float> best_segmentations_scores(word.length() + 1, -std::numeric_limits<float>::infinity());
|
||||
best_segmentations_scores[0] = 1.0;
|
||||
|
||||
for (int start_idx = 0; start_idx < word.length(); ++start_idx) {
|
||||
float best_score_at_start = best_segmentations_scores[start_idx];
|
||||
for (int end_idx = start_idx + 1; end_idx <= word.length(); ++end_idx) {
|
||||
std::string token = word.substr(start_idx, end_idx - start_idx);
|
||||
if (model.count(token) && best_score_at_start != -std::numeric_limits<float>::infinity()) {
|
||||
float token_score = model.at(token).second;
|
||||
float score = token_score + best_score_at_start;
|
||||
if (best_segmentations_scores[end_idx] == -std::numeric_limits<float>::infinity() ||
|
||||
best_segmentations_scores[end_idx] > score) {
|
||||
best_segmentations_starts[end_idx] = start_idx;
|
||||
best_segmentations_scores[end_idx] = score;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (best_segmentations_scores.back() == -std::numeric_limits<float>::infinity()) {
|
||||
return std::make_pair(std::vector<std::size_t>{0}, 0.0f);
|
||||
}
|
||||
|
||||
float score = best_segmentations_scores.back();
|
||||
int start = best_segmentations_starts.back();
|
||||
int end = word.length();
|
||||
std::vector<std::size_t> tokens;
|
||||
while (start != 0) {
|
||||
const auto token_id = model.at(word.substr(start, end - start)).first;
|
||||
tokens.insert(tokens.begin(), token_id);
|
||||
int next_start = best_segmentations_starts[start];
|
||||
end = start;
|
||||
start = next_start;
|
||||
}
|
||||
const auto token_id = model.at(word.substr(start, end - start)).first;
|
||||
tokens.insert(tokens.begin(), token_id);
|
||||
return std::make_pair(tokens, score);
|
||||
}
|
||||
|
||||
bool replit_tokenizer_load(replit_tokenizer & tokenizer, std::istream & fin, int max_vocab_size) {
|
||||
std::string word;
|
||||
std::vector<char> buf(128);
|
||||
|
||||
for (std::size_t i = 0; i < max_vocab_size; i++) {
|
||||
uint32_t len;
|
||||
fin.read((char *)&len, sizeof(len));
|
||||
|
||||
buf.resize(len);
|
||||
fin.read((char *) buf.data(), len);
|
||||
word.assign(buf.data(), len);
|
||||
|
||||
float score;
|
||||
fin.read((char *)&score, sizeof(score));
|
||||
|
||||
tokenizer.piece_map[word] = std::make_pair(i, -score);
|
||||
tokenizer.raw_vocab.id_to_token[i] = word;
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
std::string replace_all(const std::string & str, // where to work
|
||||
const std::string & find, // substitute 'find'
|
||||
const std::string & replace // by 'replace'
|
||||
) {
|
||||
using namespace std;
|
||||
string result;
|
||||
size_t find_len = find.size();
|
||||
size_t pos, from = 0;
|
||||
while (string::npos != (pos = str.find(find, from))) {
|
||||
result.append(str, from, pos - from);
|
||||
result.append(replace);
|
||||
from = pos + find_len;
|
||||
}
|
||||
result.append(str, from, string::npos);
|
||||
return result;
|
||||
}
|
||||
|
||||
std::string ws_symbol = "\342\226\201";
|
||||
std::vector<std::size_t> replit_tokenizer_tokenize(replit_tokenizer & tokenizer, const std::string & text) {
|
||||
std::vector<std::size_t> tokens;
|
||||
auto normalized_text = replace_all(text, " ", ws_symbol);
|
||||
auto tokenized = encode_word(normalized_text, tokenizer.piece_map);
|
||||
|
||||
return tokenized.first;
|
||||
}
|
||||
|
||||
std::string replit_tokenizer_detokenize(replit_tokenizer & tokenizer, const std::vector<std::size_t> & tokens) {
|
||||
std::string text;
|
||||
for (auto token : tokens) {
|
||||
text += tokenizer.raw_vocab.id_to_token[token];
|
||||
}
|
||||
auto denormalized_text = replace_all(text, ws_symbol, " ");
|
||||
return denormalized_text;
|
||||
}
|
||||
|
||||
// no defaults for now
|
||||
struct mpt_hparams {
|
||||
int32_t d_model = 0;
|
||||
int32_t max_seq_len = 0;
|
||||
int32_t n_heads = 0;
|
||||
int32_t n_layers = 0;
|
||||
int32_t n_vocab = 0;
|
||||
int32_t ftype = 0;
|
||||
};
|
||||
|
||||
struct replit_layer {
|
||||
// pre normalization
|
||||
struct ggml_tensor * ln_1_weight;
|
||||
|
||||
// attention
|
||||
struct ggml_tensor * c_attn_wqkv_weight;
|
||||
|
||||
struct ggml_tensor * c_attn_out_proj_weight;
|
||||
|
||||
// post normalization
|
||||
struct ggml_tensor * ln_2_weight;
|
||||
|
||||
// ff
|
||||
struct ggml_tensor * c_mlp_mlp_up_weight;
|
||||
|
||||
struct ggml_tensor * c_mlp_mlp_down_weight;
|
||||
};
|
||||
|
||||
struct replit_model {
|
||||
mpt_hparams hparams;
|
||||
|
||||
struct ggml_tensor * wte_weight; // position embedding
|
||||
struct ggml_tensor * ln_f_weight; // language model head
|
||||
|
||||
std::vector<replit_layer> layers;
|
||||
|
||||
// key + value memory
|
||||
struct ggml_tensor * memory_k;
|
||||
struct ggml_tensor * memory_v;
|
||||
|
||||
struct ggml_context * ctx;
|
||||
std::map<std::string, struct ggml_tensor *> tensors;
|
||||
};
|
||||
|
||||
// load the model's weights from a file
|
||||
bool replit_model_load(const std::string & fname, replit_model & model, replit_tokenizer & vocab) {
|
||||
printf("%s: loading model from '%s' - please wait ...\n", __func__, fname.c_str());
|
||||
|
||||
auto fin = std::ifstream(fname, std::ios::binary);
|
||||
if (!fin) {
|
||||
fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
fin.read((char *)&magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// load hparams
|
||||
{
|
||||
auto & hparams = model.hparams;
|
||||
|
||||
fin.read((char *) &hparams.d_model, sizeof(hparams.d_model));
|
||||
fin.read((char *) &hparams.max_seq_len, sizeof(hparams.max_seq_len));
|
||||
fin.read((char *) &hparams.n_heads, sizeof(hparams.n_heads));
|
||||
fin.read((char *) &hparams.n_layers, sizeof(hparams.n_layers));
|
||||
fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fin.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
|
||||
printf("%s: d_model = %d\n", __func__, hparams.d_model);
|
||||
printf("%s: max_seq_len = %d\n", __func__, hparams.max_seq_len);
|
||||
printf("%s: n_heads = %d\n", __func__, hparams.n_heads);
|
||||
printf("%s: n_layers = %d\n", __func__, hparams.n_layers);
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: ftype = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr = %d\n", __func__, qntvr);
|
||||
|
||||
hparams.ftype %= GGML_QNT_VERSION_FACTOR;
|
||||
}
|
||||
|
||||
// load vocab
|
||||
replit_tokenizer_load(vocab, fin, model.hparams.n_vocab);
|
||||
|
||||
// for the big tensors, we have the option to store the data in 16-bit
|
||||
// floats or quantized in order to save memory and also to speed up the
|
||||
// computation
|
||||
ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype)(model.hparams.ftype));
|
||||
if (wtype == GGML_TYPE_COUNT) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n", __func__, fname.c_str(),
|
||||
model.hparams.ftype);
|
||||
return false;
|
||||
}
|
||||
|
||||
auto & ctx = model.ctx;
|
||||
|
||||
size_t ctx_size = 0;
|
||||
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.d_model;
|
||||
const int n_layer = hparams.n_layers;
|
||||
const int n_ctx = hparams.max_seq_len;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
ctx_size += n_embd * n_vocab * ggml_type_sizef(wtype); // wte_weight
|
||||
ctx_size += n_embd * ggml_type_sizef(GGML_TYPE_F32); // ln_f_weight
|
||||
|
||||
ctx_size += n_layer * (n_embd * ggml_type_sizef(GGML_TYPE_F32)); // ln_1_weight
|
||||
ctx_size += n_layer * (3 * n_embd * n_embd * ggml_type_sizef(wtype)); // attn_Wqkv_weight
|
||||
ctx_size += n_layer * (n_embd * n_embd * ggml_type_sizef(wtype)); // attn_out_proj_weight
|
||||
ctx_size += n_layer * (n_embd * ggml_type_sizef(GGML_TYPE_F32)); // ln_2_weight
|
||||
ctx_size += n_layer * (4 * n_embd * n_embd * ggml_type_sizef(wtype)); // mlp_mlp_up_weight
|
||||
ctx_size += n_layer * (n_embd * n_embd * 4 * ggml_type_sizef(wtype)); // mlp_mlp_down_weight
|
||||
|
||||
ctx_size += n_ctx * n_layer * n_embd * ggml_type_sizef(GGML_TYPE_F16); // memory_k
|
||||
ctx_size += n_ctx * n_layer * n_embd * ggml_type_sizef(GGML_TYPE_F16); // memory_v
|
||||
|
||||
ctx_size += (1 + 6 * n_layer) * 512; // object overhead
|
||||
|
||||
printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size / (1024.0 * 1024.0));
|
||||
}
|
||||
|
||||
// create the ggml context
|
||||
{
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = ctx_size,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
model.ctx = ggml_init(params);
|
||||
if (!model.ctx) {
|
||||
fprintf(stderr, "%s: ggml_init() failed\n", __func__);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// prepare memory for the weights
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.d_model;
|
||||
const int n_layer = hparams.n_layers;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
model.layers.resize(n_layer);
|
||||
|
||||
model.wte_weight = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab);
|
||||
model.ln_f_weight = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
// map by name
|
||||
model.tensors["transformer.wte.weight"] = model.wte_weight;
|
||||
model.tensors["transformer.ln_f.weight"] = model.ln_f_weight;
|
||||
|
||||
for (int i = 0; i < n_layer; ++i) {
|
||||
auto & layer = model.layers[i];
|
||||
|
||||
layer.ln_1_weight = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
layer.c_attn_wqkv_weight = ggml_new_tensor_2d(ctx, wtype, n_embd, 3 * n_embd);
|
||||
layer.c_attn_out_proj_weight = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd);
|
||||
layer.ln_2_weight = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
layer.c_mlp_mlp_up_weight = ggml_new_tensor_2d(ctx, wtype, n_embd, 4 * n_embd);
|
||||
layer.c_mlp_mlp_down_weight = ggml_new_tensor_2d(ctx, wtype, 4 * n_embd, n_embd);
|
||||
|
||||
// map by name
|
||||
model.tensors["transformer.blocks." + std::to_string(i) + ".ln_1.weight"] = layer.ln_1_weight;
|
||||
model.tensors["transformer.blocks." + std::to_string(i) + ".attn.Wqkv.weight"] = layer.c_attn_wqkv_weight;
|
||||
model.tensors["transformer.blocks." + std::to_string(i) + ".attn.out_proj.weight"] =
|
||||
layer.c_attn_out_proj_weight;
|
||||
model.tensors["transformer.blocks." + std::to_string(i) + ".ln_2.weight"] = layer.ln_2_weight;
|
||||
model.tensors["transformer.blocks." + std::to_string(i) + ".mlp.mlp_up.weight"] = layer.c_mlp_mlp_up_weight;
|
||||
model.tensors["transformer.blocks." + std::to_string(i) + ".mlp.mlp_down.weight"] =
|
||||
layer.c_mlp_mlp_down_weight;
|
||||
}
|
||||
}
|
||||
|
||||
// key + value memory
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.d_model;
|
||||
const int n_layer = hparams.n_layers;
|
||||
const int n_ctx = hparams.max_seq_len;
|
||||
|
||||
const int64_t n_mem = n_layer * n_ctx;
|
||||
const int64_t n_elements = n_embd * n_mem;
|
||||
|
||||
model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements);
|
||||
model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements);
|
||||
|
||||
const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v);
|
||||
|
||||
printf("%s: memory_size = %8.2f MB, n_mem = %" PRId64 "\n", __func__, memory_size / 1024.0 / 1024.0, n_mem);
|
||||
}
|
||||
|
||||
// load weights
|
||||
{
|
||||
int n_tensors = 0;
|
||||
size_t total_size = 0;
|
||||
|
||||
printf("%s: ", __func__);
|
||||
|
||||
while (true) {
|
||||
int32_t n_dims;
|
||||
int32_t length;
|
||||
int32_t ttype;
|
||||
|
||||
fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
|
||||
fin.read(reinterpret_cast<char *>(&length), sizeof(length));
|
||||
fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype));
|
||||
|
||||
if (fin.eof()) {
|
||||
break;
|
||||
}
|
||||
|
||||
int32_t nelements = 1;
|
||||
int32_t ne[2] = {1, 1};
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i]));
|
||||
nelements *= ne[i];
|
||||
}
|
||||
|
||||
std::string name(length, 0);
|
||||
fin.read(&name[0], length);
|
||||
|
||||
if (model.tensors.find(name.data()) == model.tensors.end()) {
|
||||
fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.data());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto tensor = model.tensors[name.data()];
|
||||
if (ggml_nelements(tensor) != nelements) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.data());
|
||||
return false;
|
||||
}
|
||||
|
||||
if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) {
|
||||
fprintf(stderr,
|
||||
"%s: tensor '%s' has wrong shape in model file: got [%5d, "
|
||||
"%5d], expected [%5d, %5d]\n",
|
||||
__func__, name.data(), (int)tensor->ne[0], (int)tensor->ne[1], ne[0], ne[1]);
|
||||
return false;
|
||||
}
|
||||
|
||||
// for debugging
|
||||
if (0) {
|
||||
printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.data(), ne[0], ne[1],
|
||||
ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor) / 1024.0 / 1024.0, ggml_nbytes(tensor));
|
||||
}
|
||||
|
||||
const size_t bpe = ggml_type_size(ggml_type(ttype));
|
||||
|
||||
if ((nelements * bpe) / ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) {
|
||||
fprintf(stderr,
|
||||
"%s: tensor '%s' has wrong size in model file: got %zu, "
|
||||
"expected %zu\n",
|
||||
__func__, name.data(), ggml_nbytes(tensor), nelements * bpe);
|
||||
return false;
|
||||
}
|
||||
|
||||
fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor));
|
||||
|
||||
total_size += ggml_nbytes(tensor);
|
||||
if (++n_tensors % 8 == 0) {
|
||||
printf(".");
|
||||
fflush(stdout);
|
||||
}
|
||||
}
|
||||
|
||||
printf(" done\n");
|
||||
|
||||
printf("%s: model size = %8.2f MB / num tensors = %d\n", __func__, total_size / 1024.0 / 1024.0, n_tensors);
|
||||
}
|
||||
|
||||
fin.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// evaluate the transformer
|
||||
//
|
||||
// - model: the model
|
||||
// - n_threads: number of threads to use
|
||||
// - n_past: the context size so far
|
||||
// - embd_inp: the embeddings of the tokens in the context
|
||||
// - embd_w: the predicted logits for the next token
|
||||
//
|
||||
bool replit_eval(const replit_model & model, const int n_threads, const int n_past,
|
||||
const std::vector<gpt_vocab::id> & embd_inp, std::vector<float> & embd_w, size_t & mem_per_token) {
|
||||
const int N = embd_inp.size();
|
||||
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.d_model;
|
||||
const int n_layer = hparams.n_layers;
|
||||
const int n_ctx = hparams.max_seq_len;
|
||||
const int n_head = hparams.n_heads;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
static size_t buf_size = 256u * 1024 * 1024;
|
||||
static void * buf = malloc(buf_size);
|
||||
|
||||
if (mem_per_token > 0 && mem_per_token * N > buf_size) {
|
||||
const size_t buf_size_new = 1.1 * (mem_per_token * N); // add 10% to account for ggml object overhead
|
||||
// printf("\n%s: reallocating buffer from %zu to %zu bytes\n", __func__,
|
||||
// buf_size, buf_size_new);
|
||||
|
||||
// reallocate
|
||||
buf_size = buf_size_new;
|
||||
buf = realloc(buf, buf_size);
|
||||
if (buf == nullptr) {
|
||||
fprintf(stderr, "%s: failed to allocate %zu bytes\n", __func__, buf_size);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = buf_size,
|
||||
.mem_buffer = buf,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
struct ggml_cgraph gf = {.n_threads = n_threads};
|
||||
|
||||
struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N);
|
||||
memcpy(embd->data, embd_inp.data(), N * ggml_element_size(embd));
|
||||
|
||||
struct ggml_tensor * inpL = ggml_get_rows(ctx0, model.wte_weight, embd);
|
||||
|
||||
for (int il = 0; il < n_layer; ++il) {
|
||||
|
||||
struct ggml_tensor * cur;
|
||||
|
||||
// a = self.ln_1(x)
|
||||
{
|
||||
cur = ggml_norm(ctx0, inpL);
|
||||
|
||||
cur = ggml_mul(ctx0, ggml_repeat(ctx0, model.layers[il].ln_1_weight, cur), cur);
|
||||
}
|
||||
|
||||
// self-attention
|
||||
// b, _, past_key_value = self.attn(a, past_key_value=past_key_value,
|
||||
// attn_bias=attn_bias, attention_mask=attention_mask,
|
||||
// is_causal=is_causal)
|
||||
{
|
||||
|
||||
// compute QKV
|
||||
{ cur = ggml_mul_mat(ctx0, model.layers[il].c_attn_wqkv_weight, cur); }
|
||||
|
||||
struct ggml_tensor * Qcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 0 * sizeof(float) * n_embd);
|
||||
struct ggml_tensor * Kcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 1 * sizeof(float) * n_embd);
|
||||
struct ggml_tensor * Vcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 2 * sizeof(float) * n_embd);
|
||||
|
||||
// store key and value to memory
|
||||
{
|
||||
struct ggml_tensor * k =
|
||||
ggml_view_1d(ctx0, model.memory_k, N * n_embd,
|
||||
(ggml_element_size(model.memory_k) * n_embd) * (il * n_ctx + n_past));
|
||||
struct ggml_tensor * v =
|
||||
ggml_view_1d(ctx0, model.memory_v, N * n_embd,
|
||||
(ggml_element_size(model.memory_v) * n_embd) * (il * n_ctx + n_past));
|
||||
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Kcur, k));
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Vcur, v));
|
||||
}
|
||||
|
||||
// Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0,
|
||||
// 2, 1, 3) [64, N, 12]
|
||||
struct ggml_tensor * Q = ggml_permute(
|
||||
ctx0, ggml_cpy(ctx0, Qcur, ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_embd / n_head, n_head, N)), 0, 2,
|
||||
1, 3);
|
||||
|
||||
// K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1,
|
||||
// 3) [64, n_past + N, 12]
|
||||
struct ggml_tensor * K =
|
||||
ggml_permute(ctx0,
|
||||
ggml_reshape_3d(ctx0,
|
||||
ggml_view_1d(ctx0, model.memory_k, (n_past + N) * n_embd,
|
||||
il * n_ctx * ggml_element_size(model.memory_k) * n_embd),
|
||||
n_embd / n_head, n_head, n_past + N),
|
||||
0, 2, 1, 3);
|
||||
// K * Q
|
||||
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q);
|
||||
|
||||
// KQ_scaled = KQ / sqrt(n_embd/n_head)
|
||||
struct ggml_tensor * KQ_scaled =
|
||||
ggml_scale(ctx0, KQ, ggml_new_f32(ctx0, 1.0f / sqrt(float(n_embd) / n_head)));
|
||||
|
||||
struct ggml_tensor * KQ_scaled_alibi = ggml_alibi(ctx0, KQ_scaled, n_past, n_head, 8.0);
|
||||
|
||||
// KQ_masked = mask_past(KQ_scaled)
|
||||
struct ggml_tensor * KQ_masked = ggml_diag_mask_inf(ctx0, KQ_scaled_alibi, n_past);
|
||||
|
||||
// KQ = soft_max(KQ_masked)
|
||||
struct ggml_tensor * KQ_soft_max = ggml_soft_max(ctx0, KQ_masked);
|
||||
|
||||
// V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1,
|
||||
// 2, 0, 3).contiguous() [n_past + N, 64, 12]
|
||||
struct ggml_tensor * V_trans = ggml_cpy(
|
||||
ctx0,
|
||||
ggml_permute(ctx0,
|
||||
ggml_reshape_3d(ctx0,
|
||||
ggml_view_1d(ctx0, model.memory_v, (n_past + N) * n_embd,
|
||||
il * n_ctx * ggml_element_size(model.memory_v) * n_embd),
|
||||
n_embd / n_head, n_head, n_past + N),
|
||||
1, 2, 0, 3),
|
||||
ggml_new_tensor_3d(ctx0, model.memory_v->type, n_past + N, n_embd / n_head, n_head));
|
||||
|
||||
// KQV = transpose(V) * KQ_soft_max
|
||||
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V_trans, KQ_soft_max);
|
||||
|
||||
// KQV_merged = KQV.permute(0, 2, 1, 3)
|
||||
struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3);
|
||||
|
||||
// cur = KQV_merged.contiguous().view(n_embd, N)
|
||||
cur = ggml_cpy(ctx0, KQV_merged, ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N));
|
||||
|
||||
// projection
|
||||
{ cur = ggml_mul_mat(ctx0, model.layers[il].c_attn_out_proj_weight, cur); }
|
||||
}
|
||||
|
||||
inpL = ggml_add(ctx0, inpL, cur);
|
||||
|
||||
// m = self.ln_2(x)
|
||||
{
|
||||
cur = ggml_norm(ctx0, inpL);
|
||||
|
||||
cur = ggml_mul(ctx0, ggml_repeat(ctx0, model.layers[il].ln_2_weight, cur), cur);
|
||||
}
|
||||
|
||||
// n = self.mlp(m)
|
||||
{
|
||||
|
||||
cur = ggml_mul_mat(ctx0, model.layers[il].c_mlp_mlp_up_weight, cur);
|
||||
|
||||
// GELU activation
|
||||
cur = ggml_gelu(ctx0, cur);
|
||||
|
||||
// projection
|
||||
// cur = proj_w*cur + proj_b
|
||||
cur = ggml_mul_mat(ctx0, model.layers[il].c_mlp_mlp_down_weight, cur);
|
||||
}
|
||||
|
||||
// x = x + n
|
||||
inpL = ggml_add(ctx0, inpL, cur);
|
||||
}
|
||||
|
||||
// norm
|
||||
{
|
||||
inpL = ggml_norm(ctx0, inpL);
|
||||
// inpL = ln_f_g*inpL
|
||||
inpL = ggml_mul(ctx0, ggml_repeat(ctx0, model.ln_f_weight, inpL), inpL);
|
||||
}
|
||||
|
||||
// output embedding weight tied to input embedding
|
||||
inpL = ggml_mul_mat(ctx0, model.wte_weight, inpL);
|
||||
|
||||
// logits -> probs
|
||||
// inpL = ggml_soft_max(ctx0, inpL);
|
||||
|
||||
// run the computation
|
||||
ggml_build_forward_expand(&gf, inpL);
|
||||
ggml_graph_compute(ctx0, &gf);
|
||||
|
||||
// std::cout << "Qcur" << std::endl;
|
||||
// print_tensor(Qcur);
|
||||
|
||||
// if (n_past%100 == 0) {
|
||||
// ggml_graph_print(&gf);
|
||||
// ggml_graph_dump_dot(&gf, NULL, "replit-model.dot");
|
||||
// }
|
||||
|
||||
// return result for just the last token
|
||||
embd_w.resize(n_vocab);
|
||||
memcpy(embd_w.data(), (float *)ggml_get_data(inpL) + (n_vocab * (N - 1)), sizeof(float) * n_vocab);
|
||||
|
||||
if (mem_per_token == 0) {
|
||||
mem_per_token = ggml_used_mem(ctx0) / N;
|
||||
}
|
||||
// printf("used_mem = %zu\n", ggml_used_mem(ctx0));
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
int main(int argc, char ** argv) {
|
||||
ggml_time_init();
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
gpt_params params;
|
||||
params.model = "";
|
||||
|
||||
if (gpt_params_parse(argc, argv, params) == false) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
if (params.seed < 0) {
|
||||
params.seed = time(NULL);
|
||||
}
|
||||
|
||||
printf("%s: seed = %d\n", __func__, params.seed);
|
||||
|
||||
std::mt19937 rng(params.seed);
|
||||
if (params.prompt.empty()) {
|
||||
params.prompt = gpt_random_prompt(rng);
|
||||
}
|
||||
|
||||
int64_t t_load_us = 0;
|
||||
|
||||
replit_tokenizer vocab;
|
||||
replit_model model;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!replit_model_load(params.model, model, vocab)) {
|
||||
fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_load_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
int n_past = 0;
|
||||
|
||||
int64_t t_sample_us = 0;
|
||||
int64_t t_predict_us = 0;
|
||||
|
||||
std::vector<float> logits;
|
||||
|
||||
// tokenize the prompt
|
||||
std::vector<std::size_t> embd_inp = replit_tokenizer_tokenize(vocab, params.prompt);
|
||||
|
||||
printf("%s: number of tokens in prompt = %zu\n", __func__, embd_inp.size());
|
||||
|
||||
for (int i = 0; i < embd_inp.size(); i++) {
|
||||
printf("%s: token[%d] = %6lu\n", __func__, i, embd_inp[i]);
|
||||
// vocab.id_to_token.at(embd_inp[i]).c_str()
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
params.n_predict = std::min(params.n_predict, model.hparams.max_seq_len - (int)embd_inp.size());
|
||||
|
||||
std::vector<gpt_vocab::id> embd;
|
||||
|
||||
// determine the required inference memory per token:
|
||||
size_t mem_per_token = 0;
|
||||
replit_eval(model, params.n_threads, 0, {0, 1, 2, 3}, logits, mem_per_token);
|
||||
|
||||
for (int i = embd.size(); i < embd_inp.size() + params.n_predict; i++) {
|
||||
// predict
|
||||
if (embd.size() > 0) {
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!replit_eval(model, params.n_threads, n_past, embd, logits, mem_per_token)) {
|
||||
printf("Failed to predict\n");
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_predict_us += ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
n_past += embd.size();
|
||||
embd.clear();
|
||||
|
||||
if (i >= embd_inp.size()) {
|
||||
// sample next token
|
||||
const int top_k = params.top_k;
|
||||
const float top_p = params.top_p;
|
||||
const float temp = params.temp;
|
||||
|
||||
const int n_vocab = model.hparams.n_vocab;
|
||||
|
||||
gpt_vocab::id id = 0;
|
||||
|
||||
{
|
||||
const int64_t t_start_sample_us = ggml_time_us();
|
||||
|
||||
id = gpt_sample_top_k_top_p(vocab.raw_vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p,
|
||||
temp, rng);
|
||||
|
||||
t_sample_us += ggml_time_us() - t_start_sample_us;
|
||||
}
|
||||
|
||||
// add it to the context
|
||||
embd.push_back(id);
|
||||
} else {
|
||||
// if here, it means we are still processing the input prompt
|
||||
for (int k = i; k < embd_inp.size(); k++) {
|
||||
embd.push_back(embd_inp[k]);
|
||||
if (embd.size() > params.n_batch) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
i += embd.size() - 1;
|
||||
}
|
||||
|
||||
// display text
|
||||
for (auto id : embd) {
|
||||
printf("%s", replit_tokenizer_detokenize(vocab, {static_cast<std::size_t>(id)}).c_str());
|
||||
}
|
||||
fflush(stdout);
|
||||
|
||||
// end of text token
|
||||
if (embd.back() == 0) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n\n");
|
||||
printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token);
|
||||
printf("%s: load time = %8.2f ms\n", __func__, t_load_us / 1000.0f);
|
||||
printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us / 1000.0f);
|
||||
printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us / 1000.0f,
|
||||
t_predict_us / 1000.0f / n_past);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us) / 1000.0f);
|
||||
}
|
||||
|
||||
ggml_free(model.ctx);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,182 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common-ggml.h"
|
||||
#include "common.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <regex>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
struct mpt_hparams {
|
||||
int32_t d_model = 0;
|
||||
int32_t max_seq_len = 0;
|
||||
int32_t n_heads = 0;
|
||||
int32_t n_layers = 0;
|
||||
int32_t n_vocab = 0;
|
||||
int32_t ftype = 0;
|
||||
};
|
||||
|
||||
// quantize a model
|
||||
bool mpt_model_quantize(const std::string & fname_inp,
|
||||
const std::string & fname_out, ggml_ftype ftype) {
|
||||
|
||||
printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str());
|
||||
|
||||
auto finp = std::ifstream(fname_inp, std::ios::binary);
|
||||
if (!finp) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__,
|
||||
fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto fout = std::ofstream(fname_out, std::ios::binary);
|
||||
if (!fout) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__,
|
||||
fname_out.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
finp.read((char *)&magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n",
|
||||
__func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
fout.write((char *)&magic, sizeof(magic));
|
||||
}
|
||||
|
||||
mpt_hparams hparams;
|
||||
|
||||
// load hparams
|
||||
{
|
||||
finp.read((char *) &hparams.d_model, sizeof(hparams.d_model));
|
||||
finp.read((char *) &hparams.max_seq_len, sizeof(hparams.max_seq_len));
|
||||
finp.read((char *) &hparams.n_heads, sizeof(hparams.n_heads));
|
||||
finp.read((char *) &hparams.n_layers, sizeof(hparams.n_layers));
|
||||
finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
finp.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype;
|
||||
|
||||
printf("%s: d_model = %d\n", __func__, hparams.d_model);
|
||||
printf("%s: max_seq_len = %d\n", __func__, hparams.max_seq_len);
|
||||
printf("%s: n_heads = %d\n", __func__, hparams.n_heads);
|
||||
printf("%s: n_layers = %d\n", __func__, hparams.n_layers);
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: ftype (src) = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr (src) = %d\n", __func__, qntvr_src);
|
||||
printf("%s: ftype (dst) = %d\n", __func__, ftype_dst);
|
||||
printf("%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION);
|
||||
|
||||
fout.write((char *) &hparams.d_model, sizeof(hparams.d_model));
|
||||
fout.write((char *) &hparams.max_seq_len, sizeof(hparams.max_seq_len));
|
||||
fout.write((char *) &hparams.n_heads, sizeof(hparams.n_heads));
|
||||
fout.write((char *) &hparams.n_layers, sizeof(hparams.n_layers));
|
||||
fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fout.write((char *) &ftype_dst, sizeof(ftype_dst));
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
const int32_t n_vocab = hparams.n_vocab;
|
||||
|
||||
std::string word;
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
finp.read((char *)&len, sizeof(len));
|
||||
fout.write((char *)&len, sizeof(len));
|
||||
|
||||
word.resize(len);
|
||||
finp.read((char *)word.data(), len);
|
||||
fout.write((char *)word.data(), len);
|
||||
|
||||
float prob;
|
||||
finp.read((char *)&prob, sizeof(prob));
|
||||
fout.write((char *)&prob, sizeof(prob));
|
||||
}
|
||||
}
|
||||
|
||||
printf("%s: quantizing tensors\n", __func__);
|
||||
|
||||
// regexes of tensor names to be quantized
|
||||
const std::vector<std::string> to_quant = {
|
||||
".*weight",
|
||||
};
|
||||
|
||||
if (!ggml_common_quantize_0(finp, fout, ftype, to_quant, {})) {
|
||||
fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__,
|
||||
fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
finp.close();
|
||||
fout.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// usage:
|
||||
// ./replit-quantize models/replit/ggml-model.bin
|
||||
// models/replit/ggml-model-quant.bin type
|
||||
//
|
||||
int main(int argc, char ** argv) {
|
||||
if (argc != 4) {
|
||||
fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n",
|
||||
argv[0]);
|
||||
ggml_print_ftypes(stderr);
|
||||
return 1;
|
||||
}
|
||||
|
||||
// needed to initialize f16 tables
|
||||
{
|
||||
struct ggml_init_params params = {0, NULL, false};
|
||||
struct ggml_context * ctx = ggml_init(params);
|
||||
ggml_free(ctx);
|
||||
}
|
||||
|
||||
const std::string fname_inp = argv[1];
|
||||
const std::string fname_out = argv[2];
|
||||
|
||||
const ggml_ftype ftype = ggml_parse_ftype(argv[3]);
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
int64_t t_quantize_us = 0;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!mpt_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) {
|
||||
fprintf(stderr, "%s: failed to quantize model from '%s'\n",
|
||||
__func__, fname_inp.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_quantize_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n");
|
||||
printf("%s: quantize time = %8.2f ms\n", __func__,
|
||||
t_quantize_us / 1000.0f);
|
||||
printf("%s: total time = %8.2f ms\n", __func__,
|
||||
(t_main_end_us - t_main_start_us) / 1000.0f);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
#
|
||||
# starcoder
|
||||
|
||||
set(TEST_TARGET starcoder)
|
||||
add_executable(${TEST_TARGET} main.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
||||
#
|
||||
# starcoder-quantize
|
||||
|
||||
set(TEST_TARGET starcoder-quantize)
|
||||
add_executable(${TEST_TARGET} quantize.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
|
@ -0,0 +1,112 @@
|
|||
# 💫 StarCoder
|
||||
|
||||
This is a C++ example running 💫 StarCoder inference using the [ggml](https://github.com/ggerganov/ggml) library.
|
||||
|
||||
The program runs on the CPU - no video card is required.
|
||||
|
||||
The example supports the following 💫 StarCoder models:
|
||||
|
||||
- `bigcode/starcoder`
|
||||
- `bigcode/gpt_bigcode-santacoder` aka the smol StarCoder
|
||||
|
||||
Sample performance on MacBook M1 Pro:
|
||||
|
||||
TODO
|
||||
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
$ ./bin/starcoder -h
|
||||
usage: ./bin/starcoder [options]
|
||||
|
||||
options:
|
||||
-h, --help show this help message and exit
|
||||
-s SEED, --seed SEED RNG seed (default: -1)
|
||||
-t N, --threads N number of threads to use during computation (default: 8)
|
||||
-p PROMPT, --prompt PROMPT
|
||||
prompt to start generation with (default: random)
|
||||
-n N, --n_predict N number of tokens to predict (default: 200)
|
||||
--top_k N top-k sampling (default: 40)
|
||||
--top_p N top-p sampling (default: 0.9)
|
||||
--temp N temperature (default: 1.0)
|
||||
-b N, --batch_size N batch size for prompt processing (default: 8)
|
||||
-m FNAME, --model FNAME
|
||||
model path (default: models/starcoder-117M/ggml-model.bin)
|
||||
|
||||
$ ./bin/starcoder -m ../models/bigcode/gpt_bigcode-santacoder-ggml-q4_1.bin -p "def fibonnaci(" -t 4 --top_k 0 --top_p 0.95 --temp 0.2
|
||||
main: seed = 1683881276
|
||||
starcoder_model_load: loading model from '../models/bigcode/gpt_bigcode-santacoder-ggml-q4_1.bin'
|
||||
starcoder_model_load: n_vocab = 49280
|
||||
starcoder_model_load: n_ctx = 2048
|
||||
starcoder_model_load: n_embd = 2048
|
||||
starcoder_model_load: n_head = 16
|
||||
starcoder_model_load: n_layer = 24
|
||||
starcoder_model_load: ftype = 3
|
||||
starcoder_model_load: ggml ctx size = 1794.90 MB
|
||||
starcoder_model_load: memory size = 768.00 MB, n_mem = 49152
|
||||
starcoder_model_load: model size = 1026.83 MB
|
||||
main: prompt: 'def fibonnaci('
|
||||
main: number of tokens in prompt = 7, first 8 tokens: 563 24240 78 2658 64 2819 7
|
||||
|
||||
def fibonnaci(n):
|
||||
if n == 0:
|
||||
return 0
|
||||
elif n == 1:
|
||||
return 1
|
||||
else:
|
||||
return fibonacci(n-1) + fibonacci(n-2)
|
||||
|
||||
print(fibo(10))
|
||||
|
||||
main: mem per token = 9597928 bytes
|
||||
main: load time = 480.43 ms
|
||||
main: sample time = 26.21 ms
|
||||
main: predict time = 3987.95 ms / 19.36 ms per token
|
||||
main: total time = 4580.56 ms
|
||||
```
|
||||
|
||||
## Quick start
|
||||
```bash
|
||||
git clone https://github.com/ggerganov/ggml
|
||||
cd ggml
|
||||
|
||||
# Convert HF model to ggml
|
||||
python examples/starcoder/convert-hf-to-ggml.py bigcode/gpt_bigcode-santacoder
|
||||
|
||||
# Build ggml + examples
|
||||
mkdir build && cd build
|
||||
cmake .. && make -j4 starcoder starcoder-quantize
|
||||
|
||||
# quantize the model
|
||||
./bin/starcoder-quantize ../models/bigcode/gpt_bigcode-santacoder-ggml.bin ../models/bigcode/gpt_bigcode-santacoder-ggml-q4_1.bin 3
|
||||
|
||||
# run inference
|
||||
./bin/starcoder -m ../models/bigcode/gpt_bigcode-santacoder-ggml-q4_1.bin -p "def fibonnaci(" --top_k 0 --top_p 0.95 --temp 0.2
|
||||
```
|
||||
|
||||
|
||||
## Downloading and converting the original models (💫 StarCoder)
|
||||
|
||||
You can download the original model and convert it to `ggml` format using the script `convert-hf-to-ggml.py`:
|
||||
|
||||
```
|
||||
# Convert HF model to ggml
|
||||
python examples/starcoder/convert-hf-to-ggml.py bigcode/gpt_bigcode-santacoder
|
||||
```
|
||||
|
||||
This conversion requires that you have python and Transformers installed on your computer.
|
||||
|
||||
## Quantizing the models
|
||||
|
||||
You can also try to quantize the `ggml` models via 4-bit integer quantization.
|
||||
|
||||
```
|
||||
# quantize the model
|
||||
./bin/starcoder-quantize ../models/bigcode/gpt_bigcode-santacoder-ggml.bin ../models/bigcode/gpt_bigcode-santacoder-ggml-q4_1.bin 3
|
||||
```
|
||||
|
||||
| Model | Original size | Quantized size | Quantization type |
|
||||
| --- | --- | --- | --- |
|
||||
| `bigcode/gpt_bigcode-santacoder` | 5396.45 MB | 1026.83 MB | 4-bit integer (q4_1) |
|
||||
| `bigcode/starcoder` | 71628.23 MB | 13596.23 MB | 4-bit integer (q4_1) |
|
||||
|
|
@ -0,0 +1,212 @@
|
|||
# Convert HF models to ggml format
|
||||
#
|
||||
|
||||
import sys
|
||||
import struct
|
||||
import json
|
||||
import torch
|
||||
import numpy as np
|
||||
import re
|
||||
import os
|
||||
|
||||
from transformers import AutoModelForCausalLM
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, BloomForCausalLM
|
||||
|
||||
# ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py
|
||||
def bytes_to_unicode():
|
||||
"""
|
||||
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
||||
The reversible bpe codes work on unicode strings.
|
||||
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
||||
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
||||
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
||||
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
||||
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
||||
"""
|
||||
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
|
||||
cs = bs[:]
|
||||
n = 0
|
||||
for b in range(2**8):
|
||||
if b not in bs:
|
||||
bs.append(b)
|
||||
cs.append(2**8+n)
|
||||
n += 1
|
||||
cs = [chr(n) for n in cs]
|
||||
return dict(zip(bs, cs))
|
||||
|
||||
if len(sys.argv) < 2:
|
||||
print("Usage: python convert-hf-to-ggml.py hf-model-name [use-f32]")
|
||||
print("Example: python convert-hf-to-ggml.py bigcode/gpt_bigcode-santacoder")
|
||||
print("Example: python convert-hf-to-ggml.py bigcode/starcoder")
|
||||
sys.exit(1)
|
||||
|
||||
model_name = sys.argv[1].strip()
|
||||
fname_out = "models/" + sys.argv[1].strip() + "-ggml.bin"
|
||||
os.makedirs(os.path.dirname(fname_out), exist_ok=True)
|
||||
|
||||
|
||||
|
||||
# use 16-bit or 32-bit floats
|
||||
use_f16 = True
|
||||
if len(sys.argv) > 2:
|
||||
use_f16 = False
|
||||
|
||||
print("Loading model: ", model_name)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
||||
config = AutoConfig.from_pretrained(model_name, trust_remote_code=True)
|
||||
hparams = config.to_dict()
|
||||
model = AutoModelForCausalLM.from_pretrained(model_name, config=config, torch_dtype=torch.float16 if use_f16 else torch.float32, low_cpu_mem_usage=True, trust_remote_code=True, offload_state_dict=True)
|
||||
print("Model loaded: ", model_name)
|
||||
|
||||
#print (model)
|
||||
|
||||
list_vars = model.state_dict()
|
||||
#print (list_vars)
|
||||
|
||||
encoder = tokenizer.vocab
|
||||
# Add added_tokens (special tokens) to the encoder
|
||||
encoder.update(tokenizer.get_added_vocab())
|
||||
print(hparams)
|
||||
|
||||
print("Saving ggml model to: ", fname_out)
|
||||
fout = open(fname_out, "wb")
|
||||
|
||||
fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex
|
||||
vocab_size = hparams["vocab_size"]
|
||||
fout.write(struct.pack("i", vocab_size))
|
||||
# fout.write(struct.pack("i", len(encoder)))
|
||||
fout.write(struct.pack("i", hparams["n_positions"]))
|
||||
fout.write(struct.pack("i", hparams["n_embd"]))
|
||||
fout.write(struct.pack("i", hparams["n_head"]))
|
||||
fout.write(struct.pack("i", hparams["n_layer"]))
|
||||
fout.write(struct.pack("i", use_f16))
|
||||
|
||||
byte_encoder = bytes_to_unicode()
|
||||
byte_decoder = {v:k for k, v in byte_encoder.items()}
|
||||
|
||||
fout.write(struct.pack("i", vocab_size))
|
||||
|
||||
counter = 0
|
||||
# sort by value
|
||||
for key in sorted(encoder, key=encoder.get):
|
||||
text = bytearray([byte_decoder[c] for c in key])
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
counter += 1
|
||||
|
||||
# TODO: Repeat last token until vocab_size
|
||||
while counter < vocab_size:
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
counter += 1
|
||||
# assert counter == config.vocab_size
|
||||
|
||||
for name in list_vars.keys():
|
||||
data = list_vars[name].squeeze().numpy()
|
||||
print("Processing variable: " + name + " with shape: ", data.shape)
|
||||
|
||||
# rename headers to keep compatibility
|
||||
if name == "transformer.ln_f.weight":
|
||||
name = "model/ln_f/g"
|
||||
elif name == "transformer.ln_f.bias":
|
||||
name = "model/ln_f/b"
|
||||
elif name == "transformer.wte.weight":
|
||||
name = "model/wte"
|
||||
elif name == "transformer.wpe.weight":
|
||||
name = "model/wpe"
|
||||
elif name == "lm_head.weight":
|
||||
name = "model/lm_head"
|
||||
elif re.match(r"transformer.h\.\d+\.ln_1\.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_1/g"
|
||||
elif re.match(r"transformer.h\.\d+\.ln_1\.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_1/b"
|
||||
elif re.match(r"transformer.h\.\d+\.attn\.c_attn\.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_attn/w"
|
||||
elif re.match(r"transformer.h\.\d+\.attn\.c_attn\.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_attn/b"
|
||||
elif re.match(r"transformer.h\.\d+\.attn\.c_proj\.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_proj/w"
|
||||
elif re.match(r"transformer.h.\d+.attn.c_proj.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/attn/c_proj/b"
|
||||
elif re.match(r"transformer.h.\d+.ln_2.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_2/g"
|
||||
elif re.match(r"transformer.h.\d+.ln_2.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/ln_2/b"
|
||||
elif re.match(r"transformer.h.\d+.mlp.c_fc.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_fc/w"
|
||||
elif re.match(r"transformer.h.\d+.mlp.c_fc.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_fc/b"
|
||||
elif re.match(r"transformer.h.\d+.mlp.c_proj.weight", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_proj/w"
|
||||
elif re.match(r"transformer.h.\d+.mlp.c_proj.bias", name):
|
||||
i = re.findall("\d+", name)[0]
|
||||
name = f"model/h{i}/mlp/c_proj/b"
|
||||
else:
|
||||
print("Unrecognized variable name. %s", name)
|
||||
|
||||
# we don't need these
|
||||
if name.endswith("attn.masked_bias") or name.endswith(".attn.bias"):
|
||||
print(" Skipping variable: " + name)
|
||||
continue
|
||||
|
||||
n_dims = len(data.shape);
|
||||
|
||||
# ftype == 0 -> float32, ftype == 1 -> float16
|
||||
ftype = 0;
|
||||
if use_f16:
|
||||
if (name == "model/wte" or name == "model/lm_head" or name[-2:] == "/g" or name[-2:] == "/w") and n_dims == 2:
|
||||
print(" Converting to float16")
|
||||
data = data.astype(np.float16)
|
||||
ftype = 1
|
||||
else:
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype = 0
|
||||
|
||||
"model/h.*/attn/c_attn/w"
|
||||
"model/h.*/attn/c_proj/w"
|
||||
"model/h.*/mlp/c_fc/w"
|
||||
"model/h.*/mlp/c_proj/w"
|
||||
if name[-14:] == "/attn/c_attn/w" or name[-14:] == "/attn/c_attn/b":
|
||||
print(" Duplicate K,V heads to use MHA instead of MQA")
|
||||
|
||||
embed_dim = hparams["n_embd"]
|
||||
head_dim = embed_dim // hparams["n_head"]
|
||||
|
||||
# ((n_heads + 2) * head_dim, hidden_dim) -> (3 * n_heads * head_dim, hidden_dim)
|
||||
q, k ,v = np.split(data, (hparams["n_head"] * head_dim, (hparams["n_head"] + 1) * head_dim), axis=0)
|
||||
# duplicate k, v along the first axis (head_dim, hidden_dim) -> (n_heads * head_dim, hidden_dim)
|
||||
if len(k.shape) == 2:
|
||||
k = np.tile(k, (hparams["n_head"], 1))
|
||||
v = np.tile(v, (hparams["n_head"], 1))
|
||||
elif len(k.shape) == 1:
|
||||
k = np.tile(k, (hparams["n_head"]))
|
||||
v = np.tile(v, (hparams["n_head"]))
|
||||
# concat q, k, v along the first axis (n_heads * head_dim, hidden_dim) -> (3 * n_heads * head_dim, hidden_dim)
|
||||
data = np.concatenate((q, k, v), axis=0)
|
||||
|
||||
# header
|
||||
str = name.encode('utf-8')
|
||||
fout.write(struct.pack("iii", n_dims, len(str), ftype))
|
||||
for i in range(n_dims):
|
||||
fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
|
||||
fout.write(str);
|
||||
|
||||
# data
|
||||
data.tofile(fout)
|
||||
|
||||
fout.close()
|
||||
|
||||
print("Done. Output file: " + fname_out)
|
||||
print("")
|
||||
|
|
@ -0,0 +1,868 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
#include "common-ggml.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
|
||||
// default hparams (GPT-2 117M)
|
||||
// https://huggingface.co/bigcode/gpt_bigcode-santacoder/blob/main/config.json
|
||||
struct starcoder_hparams {
|
||||
int32_t n_vocab = 49280;
|
||||
int32_t n_ctx = 2048;
|
||||
int32_t n_embd = 2048;
|
||||
int32_t n_head = 16;
|
||||
int32_t n_layer = 24;
|
||||
int32_t ftype = 1;
|
||||
};
|
||||
|
||||
struct starcoder_layer {
|
||||
// normalization
|
||||
struct ggml_tensor * ln_1_g;
|
||||
struct ggml_tensor * ln_1_b;
|
||||
|
||||
struct ggml_tensor * ln_2_g;
|
||||
struct ggml_tensor * ln_2_b;
|
||||
|
||||
// attention
|
||||
struct ggml_tensor * c_attn_attn_w;
|
||||
struct ggml_tensor * c_attn_attn_b;
|
||||
|
||||
struct ggml_tensor * c_attn_proj_w;
|
||||
struct ggml_tensor * c_attn_proj_b;
|
||||
|
||||
// mlp
|
||||
struct ggml_tensor * c_mlp_fc_w;
|
||||
struct ggml_tensor * c_mlp_fc_b;
|
||||
|
||||
struct ggml_tensor * c_mlp_proj_w;
|
||||
struct ggml_tensor * c_mlp_proj_b;
|
||||
};
|
||||
|
||||
struct starcoder_model {
|
||||
starcoder_hparams hparams;
|
||||
|
||||
// normalization
|
||||
struct ggml_tensor * ln_f_g;
|
||||
struct ggml_tensor * ln_f_b;
|
||||
|
||||
struct ggml_tensor * wte; // position embedding
|
||||
struct ggml_tensor * wpe; // token embedding
|
||||
struct ggml_tensor * lm_head; // language model head
|
||||
|
||||
std::vector<starcoder_layer> layers;
|
||||
|
||||
// key + value memory
|
||||
struct ggml_tensor * memory_k;
|
||||
struct ggml_tensor * memory_v;
|
||||
|
||||
//
|
||||
struct ggml_context * ctx;
|
||||
std::map<std::string, struct ggml_tensor *> tensors;
|
||||
};
|
||||
|
||||
// load the model's weights from a file
|
||||
bool starcoder_model_load(const std::string & fname, starcoder_model & model, gpt_vocab & vocab) {
|
||||
printf("%s: loading model from '%s'\n", __func__, fname.c_str());
|
||||
|
||||
auto fin = std::ifstream(fname, std::ios::binary);
|
||||
if (!fin) {
|
||||
fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
fin.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str());
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// load hparams
|
||||
{
|
||||
auto & hparams = model.hparams;
|
||||
|
||||
fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
fin.read((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
fin.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx);
|
||||
printf("%s: n_embd = %d\n", __func__, hparams.n_embd);
|
||||
printf("%s: n_head = %d\n", __func__, hparams.n_head);
|
||||
printf("%s: n_layer = %d\n", __func__, hparams.n_layer);
|
||||
printf("%s: ftype = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr = %d\n", __func__, qntvr);
|
||||
|
||||
hparams.ftype %= GGML_QNT_VERSION_FACTOR;
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
int32_t n_vocab = 0;
|
||||
fin.read((char *) &n_vocab, sizeof(n_vocab));
|
||||
|
||||
if (n_vocab != model.hparams.n_vocab) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n",
|
||||
__func__, fname.c_str(), n_vocab, model.hparams.n_vocab);
|
||||
return false;
|
||||
}
|
||||
|
||||
std::string word;
|
||||
std::vector<char> buf(128);
|
||||
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
fin.read((char *) &len, sizeof(len));
|
||||
|
||||
buf.resize(len);
|
||||
fin.read((char *) buf.data(), len);
|
||||
word.assign(buf.data(), len);
|
||||
|
||||
vocab.token_to_id[word] = i;
|
||||
vocab.id_to_token[i] = word;
|
||||
|
||||
// if (i < 10) fprintf(stderr, "%.s: vocab[%d] = '%s'\n", __func__, i, word.c_str());
|
||||
}
|
||||
}
|
||||
|
||||
// for the big tensors, we have the option to store the data in 16-bit floats or quantized
|
||||
// in order to save memory and also to speed up the computation
|
||||
ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype));
|
||||
if (wtype == GGML_TYPE_COUNT) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n",
|
||||
__func__, fname.c_str(), model.hparams.ftype);
|
||||
return false;
|
||||
}
|
||||
|
||||
auto & ctx = model.ctx;
|
||||
|
||||
size_t ctx_size = 0;
|
||||
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
const int head_dim = n_embd / hparams.n_head;
|
||||
const int kv_heads = hparams.n_head; // 1 if MQA else hparams.n_head
|
||||
const int kv_dim = kv_heads * head_dim;
|
||||
|
||||
ctx_size += n_embd*ggml_type_sizef(GGML_TYPE_F32); // ln_f_g
|
||||
ctx_size += n_embd*ggml_type_sizef(GGML_TYPE_F32); // ln_f_b
|
||||
|
||||
ctx_size += n_vocab*n_embd*ggml_type_sizef(wtype); // wte
|
||||
ctx_size += n_ctx*n_embd*ggml_type_sizef(GGML_TYPE_F32); // wpe
|
||||
ctx_size += n_vocab*n_embd*ggml_type_sizef(wtype); // lm_head
|
||||
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_1_g
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_1_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_2_g
|
||||
ctx_size += n_layer*(n_embd*ggml_type_sizef(GGML_TYPE_F32)); // ln_2_b
|
||||
|
||||
ctx_size += n_layer*((n_embd + 2*kv_dim)*n_embd*ggml_type_sizef(wtype)); // c_attn_attn_w // TODO:
|
||||
ctx_size += n_layer*( (n_embd + 2*kv_dim)*ggml_type_sizef(GGML_TYPE_F32)); // c_attn_attn_b
|
||||
|
||||
ctx_size += n_layer*(n_embd*n_embd*ggml_type_sizef(wtype)); // c_attn_proj_w
|
||||
ctx_size += n_layer*( n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_attn_proj_b
|
||||
|
||||
ctx_size += n_layer*(4*n_embd*n_embd*ggml_type_sizef(wtype)); // c_mlp_fc_w
|
||||
ctx_size += n_layer*( 4*n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_mlp_fc_b
|
||||
|
||||
ctx_size += n_layer*(4*n_embd*n_embd*ggml_type_sizef(wtype)); // c_mlp_proj_w
|
||||
ctx_size += n_layer*( n_embd*ggml_type_sizef(GGML_TYPE_F32)); // c_mlp_proj_b
|
||||
|
||||
ctx_size += n_ctx*n_layer*n_embd*ggml_type_sizef(GGML_TYPE_F32); // memory_k
|
||||
ctx_size += n_ctx*n_layer*n_embd*ggml_type_sizef(GGML_TYPE_F32); // memory_v
|
||||
|
||||
ctx_size += (6 + 12*n_layer)*512; // object overhead
|
||||
|
||||
printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0));
|
||||
}
|
||||
|
||||
// create the ggml context
|
||||
{
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = ctx_size,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
model.ctx = ggml_init(params);
|
||||
if (!model.ctx) {
|
||||
fprintf(stderr, "%s: ggml_init() failed\n", __func__);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
// prepare memory for the weights
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
const int head_dim = n_embd / hparams.n_head;
|
||||
const int kv_heads = hparams.n_head; // 1 if MQA else hparams.n_head
|
||||
const int kv_dim = kv_heads * head_dim;
|
||||
|
||||
model.layers.resize(n_layer);
|
||||
|
||||
model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab);
|
||||
model.wpe = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_ctx);
|
||||
model.lm_head = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab);
|
||||
|
||||
// map by name
|
||||
model.tensors["model/ln_f/g"] = model.ln_f_g;
|
||||
model.tensors["model/ln_f/b"] = model.ln_f_b;
|
||||
|
||||
model.tensors["model/wte"] = model.wte;
|
||||
model.tensors["model/wpe"] = model.wpe;
|
||||
model.tensors["model/lm_head"] = model.lm_head;
|
||||
|
||||
for (int i = 0; i < n_layer; ++i) {
|
||||
auto & layer = model.layers[i];
|
||||
|
||||
layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.ln_2_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
layer.ln_2_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.c_attn_attn_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd + 2*kv_dim);
|
||||
layer.c_attn_attn_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd + 2*kv_dim);
|
||||
|
||||
layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd);
|
||||
layer.c_attn_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd); //TODO: 4*n_embd = config.n_inner
|
||||
layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd);
|
||||
|
||||
layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd);
|
||||
layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
|
||||
|
||||
// map by name
|
||||
model.tensors["model/h" + std::to_string(i) + "/ln_1/g"] = layer.ln_1_g;
|
||||
model.tensors["model/h" + std::to_string(i) + "/ln_1/b"] = layer.ln_1_b;
|
||||
|
||||
model.tensors["model/h" + std::to_string(i) + "/ln_2/g"] = layer.ln_2_g;
|
||||
model.tensors["model/h" + std::to_string(i) + "/ln_2/b"] = layer.ln_2_b;
|
||||
|
||||
model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/w"] = layer.c_attn_attn_w;
|
||||
model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/b"] = layer.c_attn_attn_b;
|
||||
|
||||
model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/w"] = layer.c_attn_proj_w;
|
||||
model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/b"] = layer.c_attn_proj_b;
|
||||
|
||||
model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/w"] = layer.c_mlp_fc_w;
|
||||
model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/b"] = layer.c_mlp_fc_b;
|
||||
|
||||
model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/w"] = layer.c_mlp_proj_w;
|
||||
model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/b"] = layer.c_mlp_proj_b;
|
||||
}
|
||||
}
|
||||
|
||||
// key + value memory
|
||||
{
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
|
||||
const int n_mem = n_layer*n_ctx;
|
||||
const int n_elements = n_embd*n_mem;
|
||||
|
||||
model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements);
|
||||
model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements);
|
||||
|
||||
const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v);
|
||||
|
||||
printf("%s: memory size = %8.2f MB, n_mem = %d\n", __func__, memory_size/1024.0/1024.0, n_mem);
|
||||
}
|
||||
|
||||
// load weights
|
||||
{
|
||||
size_t total_size = 0;
|
||||
|
||||
bool has_lm_head = false;
|
||||
|
||||
while (true) {
|
||||
int32_t n_dims;
|
||||
int32_t length;
|
||||
int32_t ttype;
|
||||
|
||||
fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims));
|
||||
fin.read(reinterpret_cast<char *>(&length), sizeof(length));
|
||||
fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype));
|
||||
|
||||
if (fin.eof()) {
|
||||
break;
|
||||
}
|
||||
|
||||
int32_t nelements = 1;
|
||||
int32_t ne[2] = { 1, 1 };
|
||||
for (int i = 0; i < n_dims; ++i) {
|
||||
fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i]));
|
||||
nelements *= ne[i];
|
||||
}
|
||||
|
||||
std::string name(length, 0);
|
||||
fin.read(&name[0], length);
|
||||
|
||||
if (model.tensors.find(name.data()) == model.tensors.end()) {
|
||||
fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.data());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto tensor = model.tensors[name.data()];
|
||||
if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%d, %d], expected [%d, %d]\n",
|
||||
__func__, name.data(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]);
|
||||
return false;
|
||||
}
|
||||
if (ggml_nelements(tensor) != nelements) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong size in model file. got %d, expected %d\n",
|
||||
__func__, name.data(), (int) ggml_nelements(tensor), nelements);
|
||||
return false;
|
||||
}
|
||||
|
||||
// for debugging
|
||||
if (0) {
|
||||
printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.data(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor));
|
||||
}
|
||||
|
||||
const size_t bpe = ggml_type_size(ggml_type(ttype));
|
||||
|
||||
if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) {
|
||||
fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n",
|
||||
__func__, name.data(), ggml_nbytes(tensor), nelements*bpe);
|
||||
return false;
|
||||
}
|
||||
|
||||
fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor));
|
||||
|
||||
// GPT-2 models share the WTE tensor as the LM head
|
||||
if (name == "model/wte" && has_lm_head == false) {
|
||||
memcpy(model.lm_head->data, tensor->data, ggml_nbytes(tensor));
|
||||
}
|
||||
|
||||
if (name == "model/lm_head") {
|
||||
has_lm_head = true;
|
||||
}
|
||||
|
||||
total_size += ggml_nbytes(tensor);
|
||||
}
|
||||
|
||||
printf("%s: model size = %8.2f MB\n", __func__, total_size/1024.0/1024.0);
|
||||
}
|
||||
|
||||
fin.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// evaluate the transformer
|
||||
//
|
||||
// - model: the model
|
||||
// - n_threads: number of threads to use
|
||||
// - n_past: the context size so far
|
||||
// - embd_inp: the embeddings of the tokens in the context
|
||||
// - embd_w: the predicted logits for the next token
|
||||
//
|
||||
bool starcoder_eval(
|
||||
const starcoder_model & model,
|
||||
const int n_threads,
|
||||
const int n_past,
|
||||
const std::vector<gpt_vocab::id> & embd_inp,
|
||||
std::vector<float> & embd_w,
|
||||
size_t & mem_per_token) {
|
||||
const int N = embd_inp.size();
|
||||
|
||||
const auto & hparams = model.hparams;
|
||||
|
||||
const int n_embd = hparams.n_embd;
|
||||
const int n_layer = hparams.n_layer;
|
||||
const int n_ctx = hparams.n_ctx;
|
||||
const int n_head = hparams.n_head;
|
||||
const int n_vocab = hparams.n_vocab;
|
||||
|
||||
static size_t buf_size = 256u*1024*1024;
|
||||
static void * buf = malloc(buf_size);
|
||||
|
||||
// use 2 scratch buffers
|
||||
// TODO: very hacky solution - reimplement in a more elegant way
|
||||
static size_t scr0_size = 256u*1024*1024;
|
||||
static void * scr0 = malloc(scr0_size);
|
||||
|
||||
static size_t scr1_size = 256u*1024*1024;
|
||||
static void * scr1 = malloc(scr1_size);
|
||||
|
||||
if (mem_per_token > 0 && mem_per_token*N > buf_size) {
|
||||
const size_t buf_size_new = 1.1*(mem_per_token*N); // add 10% to account for ggml object overhead
|
||||
//printf("\n%s: reallocating buffer from %zu to %zu bytes\n", __func__, buf_size, buf_size_new);
|
||||
|
||||
// reallocate
|
||||
buf_size = buf_size_new;
|
||||
buf = realloc(buf, buf_size);
|
||||
if (buf == nullptr) {
|
||||
fprintf(stderr, "%s: failed to allocate %zu bytes\n", __func__, buf_size);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = buf_size,
|
||||
.mem_buffer = buf,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
struct ggml_cgraph gf = {};
|
||||
gf.n_threads = n_threads;
|
||||
|
||||
struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N);
|
||||
memcpy(embd->data, embd_inp.data(), N*ggml_element_size(embd));
|
||||
|
||||
struct ggml_tensor * position = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N);
|
||||
for (int i = 0; i < N; ++i) {
|
||||
((int32_t *) position->data)[i] = n_past + i;
|
||||
}
|
||||
|
||||
// wte + wpe
|
||||
struct ggml_tensor * inpL =
|
||||
ggml_add(ctx0,
|
||||
ggml_get_rows(ctx0, model.wte, embd),
|
||||
ggml_get_rows(ctx0, model.wpe, position));
|
||||
|
||||
for (int il = 0; il < n_layer; ++il) {
|
||||
struct ggml_tensor * cur;
|
||||
|
||||
ggml_set_scratch(ctx0, { 0, scr0_size, scr0, });
|
||||
|
||||
// norm
|
||||
{
|
||||
// [ 768, N]
|
||||
cur = ggml_norm(ctx0, inpL);
|
||||
|
||||
// cur = ln_1_g*cur + ln_1_b
|
||||
// [ 768, N]
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].ln_1_g, cur),
|
||||
cur),
|
||||
ggml_repeat(ctx0, model.layers[il].ln_1_b, cur));
|
||||
}
|
||||
|
||||
// attn
|
||||
// [2304, 768] - model.layers[il].c_attn_attn_w
|
||||
// [2304, 1] - model.layers[il].c_attn_attn_b
|
||||
// [ 768, N] - cur (in)
|
||||
// [2304, N] - cur (out)
|
||||
//
|
||||
// cur = attn_w*cur + attn_b
|
||||
// [2304, N]
|
||||
{
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_attn_attn_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_attn_attn_b, cur),
|
||||
cur);
|
||||
}
|
||||
|
||||
// self-attention
|
||||
{
|
||||
struct ggml_tensor * Qcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 0*sizeof(float)*n_embd);
|
||||
struct ggml_tensor * Kcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 1*sizeof(float)*n_embd);
|
||||
struct ggml_tensor * Vcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 2*sizeof(float)*n_embd);
|
||||
|
||||
// store key and value to memory
|
||||
if (N >= 1) {
|
||||
struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past));
|
||||
struct ggml_tensor * v = ggml_view_1d(ctx0, model.memory_v, N*n_embd, (ggml_element_size(model.memory_v)*n_embd)*(il*n_ctx + n_past));
|
||||
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Kcur, k));
|
||||
ggml_build_forward_expand(&gf, ggml_cpy(ctx0, Vcur, v));
|
||||
}
|
||||
|
||||
// Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3)
|
||||
// [64, N, 12]
|
||||
struct ggml_tensor * Q =
|
||||
ggml_permute(ctx0,
|
||||
ggml_cpy(ctx0,
|
||||
Qcur,
|
||||
ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_embd/n_head, n_head, N)),
|
||||
0, 2, 1, 3);
|
||||
|
||||
// K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3)
|
||||
// [64, n_past + N, 12]
|
||||
struct ggml_tensor * K =
|
||||
ggml_permute(ctx0,
|
||||
ggml_reshape_3d(ctx0,
|
||||
ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd),
|
||||
n_embd/n_head, n_head, n_past + N),
|
||||
0, 2, 1, 3); //TODO: need to be tiled
|
||||
|
||||
// GG: flash attention
|
||||
//struct ggml_tensor * V =
|
||||
// ggml_cpy(ctx0,
|
||||
// ggml_permute(ctx0,
|
||||
// ggml_reshape_3d(ctx0,
|
||||
// ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd),
|
||||
// n_embd/n_head, n_head, n_past + N),
|
||||
// 1, 2, 0, 3),
|
||||
// ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_past + N, n_embd/n_head, n_head));
|
||||
|
||||
//struct ggml_tensor * KQV = ggml_flash_attn(ctx0, Q, K, V, true);
|
||||
|
||||
// K * Q
|
||||
// [n_past + N, N, 12]
|
||||
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); //TODO: check if it broadcasts
|
||||
|
||||
// KQ_scaled = KQ / sqrt(n_embd/n_head)
|
||||
// [n_past + N, N, 12]
|
||||
struct ggml_tensor * KQ_scaled =
|
||||
ggml_scale_inplace(ctx0,
|
||||
KQ,
|
||||
ggml_new_f32(ctx0, 1.0f/sqrt(float(n_embd)/n_head))
|
||||
);
|
||||
|
||||
// KQ_masked = mask_past(KQ_scaled)
|
||||
// [n_past + N, N, 12]
|
||||
struct ggml_tensor * KQ_masked = ggml_diag_mask_inf_inplace(ctx0, KQ_scaled, n_past);
|
||||
|
||||
// KQ = soft_max(KQ_masked)
|
||||
// [n_past + N, N, 12]
|
||||
struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked);
|
||||
|
||||
// V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous()
|
||||
// [n_past + N, 64, 12]
|
||||
struct ggml_tensor * V_trans =
|
||||
ggml_cpy(ctx0,
|
||||
ggml_permute(ctx0,
|
||||
ggml_reshape_3d(ctx0,
|
||||
ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd),
|
||||
n_embd/n_head, n_head, n_past + N),
|
||||
1, 2, 0, 3),
|
||||
ggml_new_tensor_3d(ctx0, model.memory_v->type, n_past + N, n_embd/n_head, n_head));
|
||||
|
||||
// KQV = transpose(V) * KQ_soft_max
|
||||
// [64, N, 12]
|
||||
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V_trans, KQ_soft_max);
|
||||
|
||||
// KQV_merged = KQV.permute(0, 2, 1, 3)
|
||||
// [64, 12, N]
|
||||
struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3);
|
||||
|
||||
// cur = KQV_merged.contiguous().view(n_embd, N)
|
||||
// [768, N]
|
||||
cur = ggml_cpy(ctx0,
|
||||
KQV_merged,
|
||||
ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N));
|
||||
}
|
||||
|
||||
// projection
|
||||
// [ 768, 768] - model.layers[il].c_attn_proj_w
|
||||
// [ 768, 1] - model.layers[il].c_attn_proj_b
|
||||
// [ 768, N] - cur (in)
|
||||
// [ 768, N] - cur (out)
|
||||
//
|
||||
// cur = proj_w*cur + proj_b
|
||||
// [768, N]
|
||||
{
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_attn_proj_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_attn_proj_b, cur),
|
||||
cur);
|
||||
}
|
||||
|
||||
// add the input
|
||||
cur = ggml_add(ctx0, cur, inpL);
|
||||
|
||||
struct ggml_tensor * inpFF = cur;
|
||||
|
||||
ggml_set_scratch(ctx0, { 0, scr1_size, scr1, });
|
||||
|
||||
// feed-forward network
|
||||
{
|
||||
// norm
|
||||
{
|
||||
cur = ggml_norm(ctx0, inpFF);
|
||||
|
||||
// cur = ln_2_g*cur + ln_2_b
|
||||
// [ 768, N]
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].ln_2_g, cur),
|
||||
cur),
|
||||
ggml_repeat(ctx0, model.layers[il].ln_2_b, cur));
|
||||
}
|
||||
|
||||
// fully connected
|
||||
// [3072, 768] - model.layers[il].c_mlp_fc_w
|
||||
// [3072, 1] - model.layers[il].c_mlp_fc_b
|
||||
// [ 768, N] - cur (in)
|
||||
// [3072, N] - cur (out)
|
||||
//
|
||||
// cur = fc_w*cur + fc_b
|
||||
// [3072, N]
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_mlp_fc_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_mlp_fc_b, cur),
|
||||
cur);
|
||||
|
||||
// GELU activation
|
||||
// [3072, N]
|
||||
cur = ggml_gelu(ctx0, cur);
|
||||
|
||||
// projection
|
||||
// [ 768, 3072] - model.layers[il].c_mlp_proj_w
|
||||
// [ 768, 1] - model.layers[il].c_mlp_proj_b
|
||||
// [3072, N] - cur (in)
|
||||
// [ 768, N] - cur (out)
|
||||
//
|
||||
// cur = proj_w*cur + proj_b
|
||||
// [768, N]
|
||||
cur = ggml_mul_mat(ctx0,
|
||||
model.layers[il].c_mlp_proj_w,
|
||||
cur);
|
||||
|
||||
cur = ggml_add(ctx0,
|
||||
ggml_repeat(ctx0, model.layers[il].c_mlp_proj_b, cur),
|
||||
cur);
|
||||
}
|
||||
|
||||
// input for next layer
|
||||
inpL = ggml_add(ctx0, cur, inpFF);
|
||||
}
|
||||
|
||||
ggml_set_scratch(ctx0, { 0, scr0_size, scr0, });
|
||||
|
||||
// norm
|
||||
{
|
||||
// [ 768, N]
|
||||
inpL = ggml_norm(ctx0, inpL);
|
||||
|
||||
// inpL = ln_f_g*inpL + ln_f_b
|
||||
// [ 768, N]
|
||||
inpL = ggml_add(ctx0,
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, model.ln_f_g, inpL),
|
||||
inpL),
|
||||
ggml_repeat(ctx0, model.ln_f_b, inpL));
|
||||
}
|
||||
|
||||
ggml_set_scratch(ctx0, { 0, 0, nullptr, });
|
||||
|
||||
// inpL = WTE * inpL
|
||||
// [ 768, 50257] - model.lm_head
|
||||
// [ 768, N] - inpL
|
||||
inpL = ggml_mul_mat(ctx0, model.lm_head, inpL);
|
||||
|
||||
// logits -> probs
|
||||
//inpL = ggml_soft_max_inplace(ctx0, inpL);
|
||||
|
||||
// run the computation
|
||||
ggml_build_forward_expand(&gf, inpL);
|
||||
ggml_graph_compute (ctx0, &gf);
|
||||
|
||||
//if (n_past%100 == 0) {
|
||||
// ggml_graph_print (&gf);
|
||||
// ggml_graph_dump_dot(&gf, NULL, "gpt-2.dot");
|
||||
//}
|
||||
|
||||
//embd_w.resize(n_vocab*N);
|
||||
//memcpy(embd_w.data(), ggml_get_data(inpL), sizeof(float)*n_vocab*N);
|
||||
|
||||
// return result just for the last token
|
||||
embd_w.resize(n_vocab);
|
||||
memcpy(embd_w.data(), (float *) ggml_get_data(inpL) + (n_vocab*(N-1)), sizeof(float)*n_vocab);
|
||||
|
||||
if (mem_per_token == 0) {
|
||||
mem_per_token = ggml_used_mem(ctx0)/N;
|
||||
}
|
||||
//printf("used_mem = %zu MB\n", ggml_used_mem(ctx0)/(1024*1024));
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
int main(int argc, char ** argv) {
|
||||
ggml_time_init();
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
gpt_params params;
|
||||
params.model = "models/gpt-2-117M/ggml-model.bin";
|
||||
|
||||
if (gpt_params_parse(argc, argv, params) == false) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
if (params.seed < 0) {
|
||||
params.seed = time(NULL);
|
||||
}
|
||||
|
||||
printf("%s: seed = %d\n", __func__, params.seed);
|
||||
|
||||
std::mt19937 rng(params.seed);
|
||||
if (params.prompt.empty()) {
|
||||
params.prompt = gpt_random_prompt(rng);
|
||||
}
|
||||
|
||||
int64_t t_load_us = 0;
|
||||
|
||||
gpt_vocab vocab;
|
||||
starcoder_model model;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!starcoder_model_load(params.model, model, vocab)) {
|
||||
fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_load_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
int n_past = 0;
|
||||
|
||||
int64_t t_sample_us = 0;
|
||||
int64_t t_predict_us = 0;
|
||||
|
||||
std::vector<float> logits;
|
||||
|
||||
// tokenize the prompt
|
||||
std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, params.prompt);
|
||||
|
||||
params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size());
|
||||
|
||||
printf("%s: prompt: '%s'\n", __func__, params.prompt.c_str());
|
||||
printf("%s: number of tokens in prompt = %zu\n", __func__, embd_inp.size());
|
||||
for (int i = 0; i < embd_inp.size(); i++) {
|
||||
printf("%s: token[%d] = %6d, %s\n", __func__, i, embd_inp[i], vocab.id_to_token.at(embd_inp[i]).c_str());
|
||||
}
|
||||
printf("\n\n");
|
||||
|
||||
// submit the input prompt token-by-token
|
||||
// this reduces the memory usage during inference, at the cost of a bit of speed at the beginning
|
||||
std::vector<gpt_vocab::id> embd;
|
||||
|
||||
// determine the required inference memory per token:
|
||||
size_t mem_per_token = 0;
|
||||
starcoder_eval(model, params.n_threads, 0, { 0, 1, 2, 3 }, logits, mem_per_token);
|
||||
|
||||
for (int i = embd.size(); i < embd_inp.size() + params.n_predict; i++) {
|
||||
// predict
|
||||
if (embd.size() > 0) {
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!starcoder_eval(model, params.n_threads, n_past, embd, logits, mem_per_token)) {
|
||||
printf("Failed to predict\n");
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_predict_us += ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
n_past += embd.size();
|
||||
embd.clear();
|
||||
|
||||
if (i >= embd_inp.size()) {
|
||||
// sample next token
|
||||
const int top_k = params.top_k;
|
||||
const float top_p = params.top_p;
|
||||
const float temp = params.temp;
|
||||
|
||||
const int n_vocab = model.hparams.n_vocab;
|
||||
|
||||
gpt_vocab::id id = 0;
|
||||
|
||||
{
|
||||
const int64_t t_start_sample_us = ggml_time_us();
|
||||
|
||||
id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng);
|
||||
|
||||
t_sample_us += ggml_time_us() - t_start_sample_us;
|
||||
}
|
||||
|
||||
// add it to the context
|
||||
embd.push_back(id);
|
||||
} else {
|
||||
// if here, it means we are still processing the input prompt
|
||||
for (int k = i; k < embd_inp.size(); k++) {
|
||||
embd.push_back(embd_inp[k]);
|
||||
if (embd.size() >= params.n_batch) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
i += embd.size() - 1;
|
||||
}
|
||||
|
||||
// display text
|
||||
for (auto id : embd) {
|
||||
printf("%s", vocab.id_to_token[id].c_str());
|
||||
}
|
||||
fflush(stdout);
|
||||
|
||||
// check if model is santacoder
|
||||
if (model.hparams.n_layer <= 30 && embd.back() == 49152) {
|
||||
break;
|
||||
}
|
||||
// check if model is starcoder
|
||||
else if (embd.back() == 0) { //TODO: this is only for starcoder
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n\n");
|
||||
printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token);
|
||||
printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f);
|
||||
printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f);
|
||||
printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us/1000.0f, t_predict_us/1000.0f/n_past);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f);
|
||||
}
|
||||
|
||||
ggml_free(model.ctx);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,184 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
#include "common-ggml.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <regex>
|
||||
|
||||
// default hparams (GPT-2 117M)
|
||||
struct starcoder_hparams {
|
||||
int32_t n_vocab = 49280;
|
||||
int32_t n_ctx = 2048;
|
||||
int32_t n_embd = 2048;
|
||||
int32_t n_head = 16;
|
||||
int32_t n_layer = 24;
|
||||
int32_t ftype = 1;
|
||||
};
|
||||
|
||||
// quantize a model
|
||||
bool starcoder_model_quantize(const std::string & fname_inp, const std::string & fname_out, ggml_ftype ftype) {
|
||||
gpt_vocab vocab;
|
||||
|
||||
printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str());
|
||||
|
||||
auto finp = std::ifstream(fname_inp, std::ios::binary);
|
||||
if (!finp) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto fout = std::ofstream(fname_out, std::ios::binary);
|
||||
if (!fout) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname_out.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
finp.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
fout.write((char *) &magic, sizeof(magic));
|
||||
}
|
||||
|
||||
starcoder_hparams hparams;
|
||||
|
||||
// load hparams
|
||||
{
|
||||
finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
finp.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
finp.read((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
finp.read((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
finp.read((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
finp.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype;
|
||||
|
||||
printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx);
|
||||
printf("%s: n_embd = %d\n", __func__, hparams.n_embd);
|
||||
printf("%s: n_head = %d\n", __func__, hparams.n_head);
|
||||
printf("%s: n_layer = %d\n", __func__, hparams.n_layer);
|
||||
printf("%s: ftype (src) = %d\n", __func__, hparams.ftype);
|
||||
printf("%s: qntvr (src) = %d\n", __func__, qntvr_src);
|
||||
printf("%s: ftype (dst) = %d\n", __func__, ftype_dst);
|
||||
printf("%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION);
|
||||
|
||||
fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fout.write((char *) &hparams.n_ctx, sizeof(hparams.n_ctx));
|
||||
fout.write((char *) &hparams.n_embd, sizeof(hparams.n_embd));
|
||||
fout.write((char *) &hparams.n_head, sizeof(hparams.n_head));
|
||||
fout.write((char *) &hparams.n_layer, sizeof(hparams.n_layer));
|
||||
fout.write((char *) &ftype_dst, sizeof(ftype_dst));
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
int32_t n_vocab = 0;
|
||||
finp.read ((char *) &n_vocab, sizeof(n_vocab));
|
||||
fout.write((char *) &n_vocab, sizeof(n_vocab));
|
||||
|
||||
if (n_vocab != hparams.n_vocab) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n",
|
||||
__func__, fname_inp.c_str(), n_vocab, hparams.n_vocab);
|
||||
return false;
|
||||
}
|
||||
|
||||
std::string word;
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
finp.read ((char *) &len, sizeof(len));
|
||||
fout.write((char *) &len, sizeof(len));
|
||||
|
||||
word.resize(len);
|
||||
finp.read ((char *) word.data(), len);
|
||||
fout.write((char *) word.data(), len);
|
||||
|
||||
vocab.token_to_id[word] = i;
|
||||
vocab.id_to_token[i] = word;
|
||||
}
|
||||
}
|
||||
|
||||
// regexes of tensor names to be quantized
|
||||
const std::vector<std::string> to_quant = {
|
||||
"model/wte",
|
||||
"model/lm_head",
|
||||
"model/h.*/attn/c_attn/w",
|
||||
"model/h.*/attn/c_proj/w",
|
||||
"model/h.*/mlp/c_fc/w",
|
||||
"model/h.*/mlp/c_proj/w",
|
||||
};
|
||||
|
||||
if (!ggml_common_quantize_0(finp, fout, ftype, to_quant, {})) {
|
||||
fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
finp.close();
|
||||
fout.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// usage:
|
||||
// ./gpt-2-quantize models/gpt-2-117M/ggml-model.bin models/gpt-2-117M/ggml-model-quant.bin type
|
||||
//
|
||||
int main(int argc, char ** argv) {
|
||||
if (argc != 4) {
|
||||
fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n", argv[0]);
|
||||
ggml_print_ftypes(stderr);
|
||||
return 1;
|
||||
}
|
||||
|
||||
// needed to initialize f16 tables
|
||||
{
|
||||
struct ggml_init_params params = { 0, NULL, false };
|
||||
struct ggml_context * ctx = ggml_init(params);
|
||||
ggml_free(ctx);
|
||||
}
|
||||
|
||||
const std::string fname_inp = argv[1];
|
||||
const std::string fname_out = argv[2];
|
||||
|
||||
const ggml_ftype ftype = ggml_parse_ftype(argv[3]);
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
int64_t t_quantize_us = 0;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!starcoder_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) {
|
||||
fprintf(stderr, "%s: failed to quantize model from '%s'\n", __func__, fname_inp.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_quantize_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n");
|
||||
printf("%s: quantize time = %8.2f ms\n", __func__, t_quantize_us/1000.0f);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,22 @@
|
|||
#
|
||||
# whisper
|
||||
|
||||
add_library(whisper-cpp
|
||||
whisper.cpp
|
||||
)
|
||||
|
||||
target_link_libraries(whisper-cpp PRIVATE
|
||||
ggml
|
||||
)
|
||||
|
||||
set(TEST_TARGET whisper)
|
||||
add_executable(${TEST_TARGET} main.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE whisper-cpp common)
|
||||
target_include_directories(${TEST_TARGET} PRIVATE ${CMAKE_CURRENT_SOURCE_DIR}/..)
|
||||
|
||||
#
|
||||
# whisper-quantize
|
||||
|
||||
set(TEST_TARGET whisper-quantize)
|
||||
add_executable(${TEST_TARGET} quantize.cpp)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml)
|
||||
|
|
@ -0,0 +1,29 @@
|
|||
# whisper
|
||||
|
||||
Port of [OpenAI's Whisper](https://github.com/openai/whisper) ASR model in C/C++ using
|
||||
[ggml](https://github.com/ggerganov/ggml)
|
||||
|
||||
## More info
|
||||
|
||||
Checkout https://github.com/ggerganov/whisper.cpp
|
||||
|
||||
## Memory usage
|
||||
|
||||
| Model | Disk | Mem |
|
||||
| --- | --- | --- |
|
||||
| tiny | 75 MB | ~280 MB |
|
||||
| base | 142 MB | ~430 MB |
|
||||
| small | 466 MB | ~1.0 GB |
|
||||
| medium | 1.5 GB | ~2.6 GB |
|
||||
| large | 2.9 GB | ~4.7 GB |
|
||||
|
||||
## ggml format
|
||||
|
||||
The original models are converted to a custom binary format. This allows to pack everything needed into a single file:
|
||||
|
||||
- model parameters
|
||||
- mel filters
|
||||
- vocabulary
|
||||
- weights
|
||||
|
||||
For more details, see the conversion script [convert-pt-to-ggml.py](convert-pt-to-ggml.py)
|
||||
|
|
@ -0,0 +1,329 @@
|
|||
# Convert Whisper transformer model from PyTorch to ggml format
|
||||
#
|
||||
# Usage: python convert-pt-to-ggml.py ~/.cache/whisper/medium.pt ~/path/to/repo/whisper/ ./models/whisper-medium
|
||||
#
|
||||
# You need to clone the original repo in ~/path/to/repo/whisper/
|
||||
#
|
||||
# git clone https://github.com/openai/whisper ~/path/to/repo/whisper/
|
||||
#
|
||||
# It is used to various assets needed by the algorithm:
|
||||
#
|
||||
# - tokenizer
|
||||
# - mel filters
|
||||
#
|
||||
# Also, you need to have the original models in ~/.cache/whisper/
|
||||
# See the original repo for more details.
|
||||
#
|
||||
# This script loads the specified model and whisper assets and saves them in ggml format.
|
||||
# The output is a single binary file containing the following information:
|
||||
#
|
||||
# - hparams
|
||||
# - mel filters
|
||||
# - tokenizer vocab
|
||||
# - model variables
|
||||
#
|
||||
# For each variable, write the following:
|
||||
#
|
||||
# - Number of dimensions (int)
|
||||
# - Name length (int)
|
||||
# - Dimensions (int[n_dims])
|
||||
# - Name (char[name_length])
|
||||
# - Data (float[n_dims])
|
||||
#
|
||||
|
||||
import io
|
||||
import os
|
||||
import sys
|
||||
import struct
|
||||
import json
|
||||
import code
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
from transformers import GPTJForCausalLM
|
||||
from transformers import GPT2TokenizerFast
|
||||
|
||||
# ref: https://github.com/openai/whisper/blob/8cf36f3508c9acd341a45eb2364239a3d81458b9/whisper/tokenizer.py#L10-L110
|
||||
LANGUAGES = {
|
||||
"en": "english",
|
||||
"zh": "chinese",
|
||||
"de": "german",
|
||||
"es": "spanish",
|
||||
"ru": "russian",
|
||||
"ko": "korean",
|
||||
"fr": "french",
|
||||
"ja": "japanese",
|
||||
"pt": "portuguese",
|
||||
"tr": "turkish",
|
||||
"pl": "polish",
|
||||
"ca": "catalan",
|
||||
"nl": "dutch",
|
||||
"ar": "arabic",
|
||||
"sv": "swedish",
|
||||
"it": "italian",
|
||||
"id": "indonesian",
|
||||
"hi": "hindi",
|
||||
"fi": "finnish",
|
||||
"vi": "vietnamese",
|
||||
"iw": "hebrew",
|
||||
"uk": "ukrainian",
|
||||
"el": "greek",
|
||||
"ms": "malay",
|
||||
"cs": "czech",
|
||||
"ro": "romanian",
|
||||
"da": "danish",
|
||||
"hu": "hungarian",
|
||||
"ta": "tamil",
|
||||
"no": "norwegian",
|
||||
"th": "thai",
|
||||
"ur": "urdu",
|
||||
"hr": "croatian",
|
||||
"bg": "bulgarian",
|
||||
"lt": "lithuanian",
|
||||
"la": "latin",
|
||||
"mi": "maori",
|
||||
"ml": "malayalam",
|
||||
"cy": "welsh",
|
||||
"sk": "slovak",
|
||||
"te": "telugu",
|
||||
"fa": "persian",
|
||||
"lv": "latvian",
|
||||
"bn": "bengali",
|
||||
"sr": "serbian",
|
||||
"az": "azerbaijani",
|
||||
"sl": "slovenian",
|
||||
"kn": "kannada",
|
||||
"et": "estonian",
|
||||
"mk": "macedonian",
|
||||
"br": "breton",
|
||||
"eu": "basque",
|
||||
"is": "icelandic",
|
||||
"hy": "armenian",
|
||||
"ne": "nepali",
|
||||
"mn": "mongolian",
|
||||
"bs": "bosnian",
|
||||
"kk": "kazakh",
|
||||
"sq": "albanian",
|
||||
"sw": "swahili",
|
||||
"gl": "galician",
|
||||
"mr": "marathi",
|
||||
"pa": "punjabi",
|
||||
"si": "sinhala",
|
||||
"km": "khmer",
|
||||
"sn": "shona",
|
||||
"yo": "yoruba",
|
||||
"so": "somali",
|
||||
"af": "afrikaans",
|
||||
"oc": "occitan",
|
||||
"ka": "georgian",
|
||||
"be": "belarusian",
|
||||
"tg": "tajik",
|
||||
"sd": "sindhi",
|
||||
"gu": "gujarati",
|
||||
"am": "amharic",
|
||||
"yi": "yiddish",
|
||||
"lo": "lao",
|
||||
"uz": "uzbek",
|
||||
"fo": "faroese",
|
||||
"ht": "haitian creole",
|
||||
"ps": "pashto",
|
||||
"tk": "turkmen",
|
||||
"nn": "nynorsk",
|
||||
"mt": "maltese",
|
||||
"sa": "sanskrit",
|
||||
"lb": "luxembourgish",
|
||||
"my": "myanmar",
|
||||
"bo": "tibetan",
|
||||
"tl": "tagalog",
|
||||
"mg": "malagasy",
|
||||
"as": "assamese",
|
||||
"tt": "tatar",
|
||||
"haw": "hawaiian",
|
||||
"ln": "lingala",
|
||||
"ha": "hausa",
|
||||
"ba": "bashkir",
|
||||
"jw": "javanese",
|
||||
"su": "sundanese",
|
||||
}
|
||||
|
||||
# ref: https://github.com/openai/whisper/blob/8cf36f3508c9acd341a45eb2364239a3d81458b9/whisper/tokenizer.py#L273-L292
|
||||
def build_tokenizer(path_to_whisper_repo: str, name: str = "gpt2"):
|
||||
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
||||
path = os.path.join(path_to_whisper_repo, "whisper/assets", name)
|
||||
tokenizer = GPT2TokenizerFast.from_pretrained(path)
|
||||
|
||||
specials = [
|
||||
"<|startoftranscript|>",
|
||||
*[f"<|{lang}|>" for lang in LANGUAGES.keys()],
|
||||
"<|translate|>",
|
||||
"<|transcribe|>",
|
||||
"<|startoflm|>",
|
||||
"<|startofprev|>",
|
||||
"<|nocaptions|>",
|
||||
"<|notimestamps|>",
|
||||
]
|
||||
|
||||
tokenizer.add_special_tokens(dict(additional_special_tokens=specials))
|
||||
return tokenizer
|
||||
|
||||
# ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py
|
||||
def bytes_to_unicode():
|
||||
"""
|
||||
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
||||
The reversible bpe codes work on unicode strings.
|
||||
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
||||
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
||||
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
||||
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
||||
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
||||
"""
|
||||
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
|
||||
cs = bs[:]
|
||||
n = 0
|
||||
for b in range(2**8):
|
||||
if b not in bs:
|
||||
bs.append(b)
|
||||
cs.append(2**8+n)
|
||||
n += 1
|
||||
cs = [chr(n) for n in cs]
|
||||
return dict(zip(bs, cs))
|
||||
|
||||
|
||||
if len(sys.argv) < 4:
|
||||
print("Usage: convert-pt-to-ggml.py model.pt path-to-whisper-repo dir-output [use-f32]\n")
|
||||
sys.exit(1)
|
||||
|
||||
fname_inp = sys.argv[1]
|
||||
dir_whisper = sys.argv[2]
|
||||
dir_out = sys.argv[3]
|
||||
|
||||
# try to load PyTorch binary data
|
||||
try:
|
||||
model_bytes = open(fname_inp, "rb").read()
|
||||
with io.BytesIO(model_bytes) as fp:
|
||||
checkpoint = torch.load(fp, map_location="cpu")
|
||||
except:
|
||||
print("Error: failed to load PyTorch model file: %s" % fname_inp)
|
||||
sys.exit(1)
|
||||
|
||||
hparams = checkpoint["dims"]
|
||||
print("hparams:", hparams)
|
||||
|
||||
list_vars = checkpoint["model_state_dict"]
|
||||
|
||||
#print(list_vars['encoder.positional_embedding'])
|
||||
#print(list_vars['encoder.conv1.weight'])
|
||||
#print(list_vars['encoder.conv1.weight'].shape)
|
||||
|
||||
# load mel filters
|
||||
n_mels = hparams["n_mels"]
|
||||
with np.load(os.path.join(dir_whisper, "whisper/assets", "mel_filters.npz")) as f:
|
||||
filters = torch.from_numpy(f[f"mel_{n_mels}"])
|
||||
#print (filters)
|
||||
|
||||
#code.interact(local=locals())
|
||||
|
||||
multilingual = hparams["n_vocab"] == 51865
|
||||
tokenizer = build_tokenizer(dir_whisper, multilingual and "multilingual" or "gpt2")
|
||||
|
||||
#print(tokenizer)
|
||||
#print(tokenizer.name_or_path)
|
||||
#print(len(tokenizer.additional_special_tokens))
|
||||
dir_tokenizer = tokenizer.name_or_path
|
||||
|
||||
# output in the same directory as the model
|
||||
fname_out = dir_out + "/ggml-model.bin"
|
||||
|
||||
with open(dir_tokenizer + "/vocab.json", "r") as f:
|
||||
tokens = json.load(f)
|
||||
|
||||
# use 16-bit or 32-bit floats
|
||||
use_f16 = True
|
||||
if len(sys.argv) > 4:
|
||||
use_f16 = False
|
||||
fname_out = dir_out + "/ggml-model-f32.bin"
|
||||
|
||||
fout = open(fname_out, "wb")
|
||||
|
||||
fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex
|
||||
fout.write(struct.pack("i", hparams["n_vocab"]))
|
||||
fout.write(struct.pack("i", hparams["n_audio_ctx"]))
|
||||
fout.write(struct.pack("i", hparams["n_audio_state"]))
|
||||
fout.write(struct.pack("i", hparams["n_audio_head"]))
|
||||
fout.write(struct.pack("i", hparams["n_audio_layer"]))
|
||||
fout.write(struct.pack("i", hparams["n_text_ctx"]))
|
||||
fout.write(struct.pack("i", hparams["n_text_state"]))
|
||||
fout.write(struct.pack("i", hparams["n_text_head"]))
|
||||
fout.write(struct.pack("i", hparams["n_text_layer"]))
|
||||
fout.write(struct.pack("i", hparams["n_mels"]))
|
||||
fout.write(struct.pack("i", use_f16))
|
||||
|
||||
# write mel filters
|
||||
fout.write(struct.pack("i", filters.shape[0]))
|
||||
fout.write(struct.pack("i", filters.shape[1]))
|
||||
for i in range(filters.shape[0]):
|
||||
for j in range(filters.shape[1]):
|
||||
fout.write(struct.pack("f", filters[i][j]))
|
||||
|
||||
byte_encoder = bytes_to_unicode()
|
||||
byte_decoder = {v:k for k, v in byte_encoder.items()}
|
||||
|
||||
fout.write(struct.pack("i", len(tokens)))
|
||||
|
||||
for key in tokens:
|
||||
text = bytearray([byte_decoder[c] for c in key])
|
||||
fout.write(struct.pack("i", len(text)))
|
||||
fout.write(text)
|
||||
|
||||
for name in list_vars.keys():
|
||||
data = list_vars[name].squeeze().numpy()
|
||||
print("Processing variable: " + name + " with shape: ", data.shape)
|
||||
|
||||
# reshape conv bias from [n] to [n, 1]
|
||||
if name == "encoder.conv1.bias" or \
|
||||
name == "encoder.conv2.bias":
|
||||
data = data.reshape(data.shape[0], 1)
|
||||
print(" Reshaped variable: " + name + " to shape: ", data.shape)
|
||||
|
||||
n_dims = len(data.shape);
|
||||
|
||||
# looks like the whisper models are in f16 by default
|
||||
# so we need to convert the small tensors to f32 until we fully support f16 in ggml
|
||||
# ftype == 0 -> float32, ftype == 1 -> float16
|
||||
ftype = 1;
|
||||
if use_f16:
|
||||
if n_dims < 2 or \
|
||||
name == "encoder.conv1.bias" or \
|
||||
name == "encoder.conv2.bias" or \
|
||||
name == "encoder.positional_embedding" or \
|
||||
name == "decoder.positional_embedding":
|
||||
ftype = 0
|
||||
data = data.astype(np.float32)
|
||||
print(" Converting to float32")
|
||||
data = data.astype(np.float32)
|
||||
ftype = 0
|
||||
else:
|
||||
if n_dims < 3 and data.dtype != np.float32:
|
||||
data = data.astype(np.float32)
|
||||
ftype = 0
|
||||
|
||||
#if name.startswith("encoder"):
|
||||
# if name.endswith("mlp.0.weight") or \
|
||||
# name.endswith("mlp.2.weight"):
|
||||
# print(" Transposing")
|
||||
# data = data.transpose()
|
||||
|
||||
# header
|
||||
str = name.encode('utf-8')
|
||||
fout.write(struct.pack("iii", n_dims, len(str), ftype))
|
||||
for i in range(n_dims):
|
||||
fout.write(struct.pack("i", data.shape[n_dims - 1 - i]))
|
||||
fout.write(str);
|
||||
|
||||
# data
|
||||
data.tofile(fout)
|
||||
|
||||
fout.close()
|
||||
|
||||
print("Done. Output file: " + fname_out)
|
||||
print("")
|
||||
|
|
@ -0,0 +1,871 @@
|
|||
#include "common.h"
|
||||
|
||||
#include "whisper.h"
|
||||
|
||||
#include <cmath>
|
||||
#include <fstream>
|
||||
#include <cstdio>
|
||||
#include <string>
|
||||
#include <thread>
|
||||
#include <vector>
|
||||
#include <cstring>
|
||||
|
||||
// Terminal color map. 10 colors grouped in ranges [0.0, 0.1, ..., 0.9]
|
||||
// Lowest is red, middle is yellow, highest is green.
|
||||
const std::vector<std::string> k_colors = {
|
||||
"\033[38;5;196m", "\033[38;5;202m", "\033[38;5;208m", "\033[38;5;214m", "\033[38;5;220m",
|
||||
"\033[38;5;226m", "\033[38;5;190m", "\033[38;5;154m", "\033[38;5;118m", "\033[38;5;82m",
|
||||
};
|
||||
|
||||
// 500 -> 00:05.000
|
||||
// 6000 -> 01:00.000
|
||||
std::string to_timestamp(int64_t t, bool comma = false) {
|
||||
int64_t msec = t * 10;
|
||||
int64_t hr = msec / (1000 * 60 * 60);
|
||||
msec = msec - hr * (1000 * 60 * 60);
|
||||
int64_t min = msec / (1000 * 60);
|
||||
msec = msec - min * (1000 * 60);
|
||||
int64_t sec = msec / 1000;
|
||||
msec = msec - sec * 1000;
|
||||
|
||||
char buf[32];
|
||||
snprintf(buf, sizeof(buf), "%02d:%02d:%02d%s%03d", (int) hr, (int) min, (int) sec, comma ? "," : ".", (int) msec);
|
||||
|
||||
return std::string(buf);
|
||||
}
|
||||
|
||||
int timestamp_to_sample(int64_t t, int n_samples) {
|
||||
return std::max(0, std::min((int) n_samples - 1, (int) ((t*WHISPER_SAMPLE_RATE)/100)));
|
||||
}
|
||||
|
||||
// helper function to replace substrings
|
||||
void replace_all(std::string & s, const std::string & search, const std::string & replace) {
|
||||
for (size_t pos = 0; ; pos += replace.length()) {
|
||||
pos = s.find(search, pos);
|
||||
if (pos == std::string::npos) break;
|
||||
s.erase(pos, search.length());
|
||||
s.insert(pos, replace);
|
||||
}
|
||||
}
|
||||
|
||||
// command-line parameters
|
||||
struct whisper_params {
|
||||
int32_t n_threads = std::min(4, (int32_t) std::thread::hardware_concurrency());
|
||||
int32_t n_processors = 1;
|
||||
int32_t offset_t_ms = 0;
|
||||
int32_t offset_n = 0;
|
||||
int32_t duration_ms = 0;
|
||||
int32_t max_context = -1;
|
||||
int32_t max_len = 0;
|
||||
int32_t best_of = 2;
|
||||
int32_t beam_size = -1;
|
||||
|
||||
float word_thold = 0.01f;
|
||||
float entropy_thold = 2.40f;
|
||||
float logprob_thold = -1.00f;
|
||||
|
||||
bool speed_up = false;
|
||||
bool translate = false;
|
||||
bool detect_language= false;
|
||||
bool diarize = false;
|
||||
bool split_on_word = false;
|
||||
bool no_fallback = false;
|
||||
bool output_txt = false;
|
||||
bool output_vtt = false;
|
||||
bool output_srt = false;
|
||||
bool output_wts = false;
|
||||
bool output_csv = false;
|
||||
bool output_jsn = false;
|
||||
bool output_lrc = false;
|
||||
bool print_special = false;
|
||||
bool print_colors = false;
|
||||
bool print_progress = false;
|
||||
bool no_timestamps = false;
|
||||
|
||||
std::string language = "en";
|
||||
std::string prompt;
|
||||
std::string font_path = "/System/Library/Fonts/Supplemental/Courier New Bold.ttf";
|
||||
std::string model = "models/ggml-base.en.bin";
|
||||
|
||||
std::vector<std::string> fname_inp = {};
|
||||
std::vector<std::string> fname_out = {};
|
||||
};
|
||||
|
||||
void whisper_print_usage(int argc, char ** argv, const whisper_params & params);
|
||||
|
||||
bool whisper_params_parse(int argc, char ** argv, whisper_params & params) {
|
||||
for (int i = 1; i < argc; i++) {
|
||||
std::string arg = argv[i];
|
||||
|
||||
if (arg == "-"){
|
||||
params.fname_inp.push_back(arg);
|
||||
continue;
|
||||
}
|
||||
|
||||
if (arg[0] != '-') {
|
||||
params.fname_inp.push_back(arg);
|
||||
continue;
|
||||
}
|
||||
|
||||
if (arg == "-h" || arg == "--help") {
|
||||
whisper_print_usage(argc, argv, params);
|
||||
exit(0);
|
||||
}
|
||||
else if (arg == "-t" || arg == "--threads") { params.n_threads = std::stoi(argv[++i]); }
|
||||
else if (arg == "-p" || arg == "--processors") { params.n_processors = std::stoi(argv[++i]); }
|
||||
else if (arg == "-ot" || arg == "--offset-t") { params.offset_t_ms = std::stoi(argv[++i]); }
|
||||
else if (arg == "-on" || arg == "--offset-n") { params.offset_n = std::stoi(argv[++i]); }
|
||||
else if (arg == "-d" || arg == "--duration") { params.duration_ms = std::stoi(argv[++i]); }
|
||||
else if (arg == "-mc" || arg == "--max-context") { params.max_context = std::stoi(argv[++i]); }
|
||||
else if (arg == "-ml" || arg == "--max-len") { params.max_len = std::stoi(argv[++i]); }
|
||||
else if (arg == "-bo" || arg == "--best-of") { params.best_of = std::stoi(argv[++i]); }
|
||||
else if (arg == "-bs" || arg == "--beam-size") { params.beam_size = std::stoi(argv[++i]); }
|
||||
else if (arg == "-wt" || arg == "--word-thold") { params.word_thold = std::stof(argv[++i]); }
|
||||
else if (arg == "-et" || arg == "--entropy-thold") { params.entropy_thold = std::stof(argv[++i]); }
|
||||
else if (arg == "-lpt" || arg == "--logprob-thold") { params.logprob_thold = std::stof(argv[++i]); }
|
||||
else if (arg == "-su" || arg == "--speed-up") { params.speed_up = true; }
|
||||
else if (arg == "-tr" || arg == "--translate") { params.translate = true; }
|
||||
else if (arg == "-di" || arg == "--diarize") { params.diarize = true; }
|
||||
else if (arg == "-sow" || arg == "--split-on-word") { params.split_on_word = true; }
|
||||
else if (arg == "-nf" || arg == "--no-fallback") { params.no_fallback = true; }
|
||||
else if (arg == "-otxt" || arg == "--output-txt") { params.output_txt = true; }
|
||||
else if (arg == "-ovtt" || arg == "--output-vtt") { params.output_vtt = true; }
|
||||
else if (arg == "-osrt" || arg == "--output-srt") { params.output_srt = true; }
|
||||
else if (arg == "-owts" || arg == "--output-words") { params.output_wts = true; }
|
||||
else if (arg == "-olrc" || arg == "--output-lrc") { params.output_lrc = true; }
|
||||
else if (arg == "-fp" || arg == "--font-path") { params.font_path = argv[++i]; }
|
||||
else if (arg == "-ocsv" || arg == "--output-csv") { params.output_csv = true; }
|
||||
else if (arg == "-oj" || arg == "--output-json") { params.output_jsn = true; }
|
||||
else if (arg == "-of" || arg == "--output-file") { params.fname_out.emplace_back(argv[++i]); }
|
||||
else if (arg == "-ps" || arg == "--print-special") { params.print_special = true; }
|
||||
else if (arg == "-pc" || arg == "--print-colors") { params.print_colors = true; }
|
||||
else if (arg == "-pp" || arg == "--print-progress") { params.print_progress = true; }
|
||||
else if (arg == "-nt" || arg == "--no-timestamps") { params.no_timestamps = true; }
|
||||
else if (arg == "-l" || arg == "--language") { params.language = argv[++i]; }
|
||||
else if (arg == "-dl" || arg == "--detect-language"){ params.detect_language= true; }
|
||||
else if ( arg == "--prompt") { params.prompt = argv[++i]; }
|
||||
else if (arg == "-m" || arg == "--model") { params.model = argv[++i]; }
|
||||
else if (arg == "-f" || arg == "--file") { params.fname_inp.emplace_back(argv[++i]); }
|
||||
else {
|
||||
fprintf(stderr, "error: unknown argument: %s\n", arg.c_str());
|
||||
whisper_print_usage(argc, argv, params);
|
||||
exit(0);
|
||||
}
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
void whisper_print_usage(int /*argc*/, char ** argv, const whisper_params & params) {
|
||||
fprintf(stderr, "\n");
|
||||
fprintf(stderr, "usage: %s [options] file0.wav file1.wav ...\n", argv[0]);
|
||||
fprintf(stderr, "\n");
|
||||
fprintf(stderr, "options:\n");
|
||||
fprintf(stderr, " -h, --help [default] show this help message and exit\n");
|
||||
fprintf(stderr, " -t N, --threads N [%-7d] number of threads to use during computation\n", params.n_threads);
|
||||
fprintf(stderr, " -p N, --processors N [%-7d] number of processors to use during computation\n", params.n_processors);
|
||||
fprintf(stderr, " -ot N, --offset-t N [%-7d] time offset in milliseconds\n", params.offset_t_ms);
|
||||
fprintf(stderr, " -on N, --offset-n N [%-7d] segment index offset\n", params.offset_n);
|
||||
fprintf(stderr, " -d N, --duration N [%-7d] duration of audio to process in milliseconds\n", params.duration_ms);
|
||||
fprintf(stderr, " -mc N, --max-context N [%-7d] maximum number of text context tokens to store\n", params.max_context);
|
||||
fprintf(stderr, " -ml N, --max-len N [%-7d] maximum segment length in characters\n", params.max_len);
|
||||
fprintf(stderr, " -sow, --split-on-word [%-7s] split on word rather than on token\n", params.split_on_word ? "true" : "false");
|
||||
fprintf(stderr, " -bo N, --best-of N [%-7d] number of best candidates to keep\n", params.best_of);
|
||||
fprintf(stderr, " -bs N, --beam-size N [%-7d] beam size for beam search\n", params.beam_size);
|
||||
fprintf(stderr, " -wt N, --word-thold N [%-7.2f] word timestamp probability threshold\n", params.word_thold);
|
||||
fprintf(stderr, " -et N, --entropy-thold N [%-7.2f] entropy threshold for decoder fail\n", params.entropy_thold);
|
||||
fprintf(stderr, " -lpt N, --logprob-thold N [%-7.2f] log probability threshold for decoder fail\n", params.logprob_thold);
|
||||
fprintf(stderr, " -su, --speed-up [%-7s] speed up audio by x2 (reduced accuracy)\n", params.speed_up ? "true" : "false");
|
||||
fprintf(stderr, " -tr, --translate [%-7s] translate from source language to english\n", params.translate ? "true" : "false");
|
||||
fprintf(stderr, " -di, --diarize [%-7s] stereo audio diarization\n", params.diarize ? "true" : "false");
|
||||
fprintf(stderr, " -nf, --no-fallback [%-7s] do not use temperature fallback while decoding\n", params.no_fallback ? "true" : "false");
|
||||
fprintf(stderr, " -otxt, --output-txt [%-7s] output result in a text file\n", params.output_txt ? "true" : "false");
|
||||
fprintf(stderr, " -ovtt, --output-vtt [%-7s] output result in a vtt file\n", params.output_vtt ? "true" : "false");
|
||||
fprintf(stderr, " -osrt, --output-srt [%-7s] output result in a srt file\n", params.output_srt ? "true" : "false");
|
||||
fprintf(stderr, " -olrc, --output-lrc [%-7s] output result in a lrc file\n", params.output_lrc ? "true" : "false");
|
||||
fprintf(stderr, " -owts, --output-words [%-7s] output script for generating karaoke video\n", params.output_wts ? "true" : "false");
|
||||
fprintf(stderr, " -fp, --font-path [%-7s] path to a monospace font for karaoke video\n", params.font_path.c_str());
|
||||
fprintf(stderr, " -ocsv, --output-csv [%-7s] output result in a CSV file\n", params.output_csv ? "true" : "false");
|
||||
fprintf(stderr, " -oj, --output-json [%-7s] output result in a JSON file\n", params.output_jsn ? "true" : "false");
|
||||
fprintf(stderr, " -of FNAME, --output-file FNAME [%-7s] output file path (without file extension)\n", "");
|
||||
fprintf(stderr, " -ps, --print-special [%-7s] print special tokens\n", params.print_special ? "true" : "false");
|
||||
fprintf(stderr, " -pc, --print-colors [%-7s] print colors\n", params.print_colors ? "true" : "false");
|
||||
fprintf(stderr, " -pp, --print-progress [%-7s] print progress\n", params.print_progress ? "true" : "false");
|
||||
fprintf(stderr, " -nt, --no-timestamps [%-7s] do not print timestamps\n", params.no_timestamps ? "true" : "false");
|
||||
fprintf(stderr, " -l LANG, --language LANG [%-7s] spoken language ('auto' for auto-detect)\n", params.language.c_str());
|
||||
fprintf(stderr, " -dl, --detect-language [%-7s] exit after automatically detecting language\n", params.detect_language ? "true" : "false");
|
||||
fprintf(stderr, " --prompt PROMPT [%-7s] initial prompt\n", params.prompt.c_str());
|
||||
fprintf(stderr, " -m FNAME, --model FNAME [%-7s] model path\n", params.model.c_str());
|
||||
fprintf(stderr, " -f FNAME, --file FNAME [%-7s] input WAV file path\n", "");
|
||||
fprintf(stderr, "\n");
|
||||
}
|
||||
|
||||
struct whisper_print_user_data {
|
||||
const whisper_params * params;
|
||||
|
||||
const std::vector<std::vector<float>> * pcmf32s;
|
||||
};
|
||||
|
||||
void whisper_print_segment_callback(struct whisper_context * ctx, struct whisper_state * /*state*/, int n_new, void * user_data) {
|
||||
const auto & params = *((whisper_print_user_data *) user_data)->params;
|
||||
const auto & pcmf32s = *((whisper_print_user_data *) user_data)->pcmf32s;
|
||||
|
||||
const int n_segments = whisper_full_n_segments(ctx);
|
||||
|
||||
std::string speaker = "";
|
||||
|
||||
int64_t t0 = 0;
|
||||
int64_t t1 = 0;
|
||||
|
||||
// print the last n_new segments
|
||||
const int s0 = n_segments - n_new;
|
||||
|
||||
if (s0 == 0) {
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
for (int i = s0; i < n_segments; i++) {
|
||||
if (!params.no_timestamps || params.diarize) {
|
||||
t0 = whisper_full_get_segment_t0(ctx, i);
|
||||
t1 = whisper_full_get_segment_t1(ctx, i);
|
||||
}
|
||||
|
||||
if (!params.no_timestamps) {
|
||||
printf("[%s --> %s] ", to_timestamp(t0).c_str(), to_timestamp(t1).c_str());
|
||||
}
|
||||
|
||||
if (params.diarize && pcmf32s.size() == 2) {
|
||||
const int64_t n_samples = pcmf32s[0].size();
|
||||
|
||||
const int64_t is0 = timestamp_to_sample(t0, n_samples);
|
||||
const int64_t is1 = timestamp_to_sample(t1, n_samples);
|
||||
|
||||
double energy0 = 0.0f;
|
||||
double energy1 = 0.0f;
|
||||
|
||||
for (int64_t j = is0; j < is1; j++) {
|
||||
energy0 += fabs(pcmf32s[0][j]);
|
||||
energy1 += fabs(pcmf32s[1][j]);
|
||||
}
|
||||
|
||||
if (energy0 > 1.1*energy1) {
|
||||
speaker = "(speaker 0)";
|
||||
} else if (energy1 > 1.1*energy0) {
|
||||
speaker = "(speaker 1)";
|
||||
} else {
|
||||
speaker = "(speaker ?)";
|
||||
}
|
||||
|
||||
//printf("is0 = %lld, is1 = %lld, energy0 = %f, energy1 = %f, %s\n", is0, is1, energy0, energy1, speaker.c_str());
|
||||
}
|
||||
|
||||
if (params.print_colors) {
|
||||
for (int j = 0; j < whisper_full_n_tokens(ctx, i); ++j) {
|
||||
if (params.print_special == false) {
|
||||
const whisper_token id = whisper_full_get_token_id(ctx, i, j);
|
||||
if (id >= whisper_token_eot(ctx)) {
|
||||
continue;
|
||||
}
|
||||
}
|
||||
|
||||
const char * text = whisper_full_get_token_text(ctx, i, j);
|
||||
const float p = whisper_full_get_token_p (ctx, i, j);
|
||||
|
||||
const int col = std::max(0, std::min((int) k_colors.size() - 1, (int) (std::pow(p, 3)*float(k_colors.size()))));
|
||||
|
||||
printf("%s%s%s%s", speaker.c_str(), k_colors[col].c_str(), text, "\033[0m");
|
||||
}
|
||||
} else {
|
||||
const char * text = whisper_full_get_segment_text(ctx, i);
|
||||
|
||||
printf("%s%s", speaker.c_str(), text);
|
||||
}
|
||||
|
||||
// with timestamps or speakers: each segment on new line
|
||||
if (!params.no_timestamps || params.diarize) {
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
fflush(stdout);
|
||||
}
|
||||
}
|
||||
|
||||
bool output_txt(struct whisper_context * ctx, const char * fname) {
|
||||
std::ofstream fout(fname);
|
||||
if (!fout.is_open()) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname);
|
||||
return false;
|
||||
}
|
||||
|
||||
fprintf(stderr, "%s: saving output to '%s'\n", __func__, fname);
|
||||
|
||||
const int n_segments = whisper_full_n_segments(ctx);
|
||||
for (int i = 0; i < n_segments; ++i) {
|
||||
const char * text = whisper_full_get_segment_text(ctx, i);
|
||||
fout << text << "\n";
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
bool output_vtt(struct whisper_context * ctx, const char * fname) {
|
||||
std::ofstream fout(fname);
|
||||
if (!fout.is_open()) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname);
|
||||
return false;
|
||||
}
|
||||
|
||||
fprintf(stderr, "%s: saving output to '%s'\n", __func__, fname);
|
||||
|
||||
fout << "WEBVTT\n\n";
|
||||
|
||||
const int n_segments = whisper_full_n_segments(ctx);
|
||||
for (int i = 0; i < n_segments; ++i) {
|
||||
const char * text = whisper_full_get_segment_text(ctx, i);
|
||||
const int64_t t0 = whisper_full_get_segment_t0(ctx, i);
|
||||
const int64_t t1 = whisper_full_get_segment_t1(ctx, i);
|
||||
|
||||
fout << to_timestamp(t0) << " --> " << to_timestamp(t1) << "\n";
|
||||
fout << text << "\n\n";
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
bool output_srt(struct whisper_context * ctx, const char * fname, const whisper_params & params) {
|
||||
std::ofstream fout(fname);
|
||||
if (!fout.is_open()) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname);
|
||||
return false;
|
||||
}
|
||||
|
||||
fprintf(stderr, "%s: saving output to '%s'\n", __func__, fname);
|
||||
|
||||
const int n_segments = whisper_full_n_segments(ctx);
|
||||
for (int i = 0; i < n_segments; ++i) {
|
||||
const char * text = whisper_full_get_segment_text(ctx, i);
|
||||
const int64_t t0 = whisper_full_get_segment_t0(ctx, i);
|
||||
const int64_t t1 = whisper_full_get_segment_t1(ctx, i);
|
||||
|
||||
fout << i + 1 + params.offset_n << "\n";
|
||||
fout << to_timestamp(t0, true) << " --> " << to_timestamp(t1, true) << "\n";
|
||||
fout << text << "\n\n";
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
char *escape_double_quotes_and_backslashes(const char *str) {
|
||||
if (str == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
|
||||
size_t escaped_length = strlen(str) + 1;
|
||||
|
||||
for (size_t i = 0; str[i] != '\0'; i++) {
|
||||
if (str[i] == '"' || str[i] == '\\') {
|
||||
escaped_length++;
|
||||
}
|
||||
}
|
||||
|
||||
char *escaped = (char *)calloc(escaped_length, 1); // pre-zeroed
|
||||
if (escaped == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
|
||||
size_t pos = 0;
|
||||
for (size_t i = 0; str[i] != '\0'; i++) {
|
||||
if (str[i] == '"' || str[i] == '\\') {
|
||||
escaped[pos++] = '\\';
|
||||
}
|
||||
escaped[pos++] = str[i];
|
||||
}
|
||||
|
||||
// no need to set zero due to calloc() being used prior
|
||||
|
||||
return escaped;
|
||||
}
|
||||
|
||||
bool output_csv(struct whisper_context * ctx, const char * fname) {
|
||||
std::ofstream fout(fname);
|
||||
if (!fout.is_open()) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname);
|
||||
return false;
|
||||
}
|
||||
|
||||
fprintf(stderr, "%s: saving output to '%s'\n", __func__, fname);
|
||||
|
||||
const int n_segments = whisper_full_n_segments(ctx);
|
||||
fout << "start,end,text\n";
|
||||
for (int i = 0; i < n_segments; ++i) {
|
||||
const char * text = whisper_full_get_segment_text(ctx, i);
|
||||
const int64_t t0 = whisper_full_get_segment_t0(ctx, i);
|
||||
const int64_t t1 = whisper_full_get_segment_t1(ctx, i);
|
||||
char * text_escaped = escape_double_quotes_and_backslashes(text);
|
||||
|
||||
//need to multiply times returned from whisper_full_get_segment_t{0,1}() by 10 to get milliseconds.
|
||||
fout << 10 * t0 << "," << 10 * t1 << ",\"" << text_escaped << "\"\n";
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
bool output_json(struct whisper_context * ctx, const char * fname, const whisper_params & params) {
|
||||
std::ofstream fout(fname);
|
||||
int indent = 0;
|
||||
|
||||
auto doindent = [&]() {
|
||||
for (int i = 0; i < indent; i++) fout << "\t";
|
||||
};
|
||||
|
||||
auto start_arr = [&](const char *name) {
|
||||
doindent();
|
||||
fout << "\"" << name << "\": [\n";
|
||||
indent++;
|
||||
};
|
||||
|
||||
auto end_arr = [&](bool end = false) {
|
||||
indent--;
|
||||
doindent();
|
||||
fout << (end ? "]\n" : "},\n");
|
||||
};
|
||||
|
||||
auto start_obj = [&](const char *name = nullptr) {
|
||||
doindent();
|
||||
if (name) {
|
||||
fout << "\"" << name << "\": {\n";
|
||||
} else {
|
||||
fout << "{\n";
|
||||
}
|
||||
indent++;
|
||||
};
|
||||
|
||||
auto end_obj = [&](bool end = false) {
|
||||
indent--;
|
||||
doindent();
|
||||
fout << (end ? "}\n" : "},\n");
|
||||
};
|
||||
|
||||
auto start_value = [&](const char *name) {
|
||||
doindent();
|
||||
fout << "\"" << name << "\": ";
|
||||
};
|
||||
|
||||
auto value_s = [&](const char *name, const char *val, bool end = false) {
|
||||
start_value(name);
|
||||
char * val_escaped = escape_double_quotes_and_backslashes(val);
|
||||
fout << "\"" << val_escaped << (end ? "\"\n" : "\",\n");
|
||||
free(val_escaped);
|
||||
};
|
||||
|
||||
auto end_value = [&](bool end = false) {
|
||||
fout << (end ? "\n" : ",\n");
|
||||
};
|
||||
|
||||
auto value_i = [&](const char *name, const int64_t val, bool end = false) {
|
||||
start_value(name);
|
||||
fout << val;
|
||||
end_value(end);
|
||||
};
|
||||
|
||||
auto value_b = [&](const char *name, const bool val, bool end = false) {
|
||||
start_value(name);
|
||||
fout << (val ? "true" : "false");
|
||||
end_value(end);
|
||||
};
|
||||
|
||||
if (!fout.is_open()) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname);
|
||||
return false;
|
||||
}
|
||||
|
||||
fprintf(stderr, "%s: saving output to '%s'\n", __func__, fname);
|
||||
start_obj();
|
||||
value_s("systeminfo", whisper_print_system_info());
|
||||
start_obj("model");
|
||||
value_s("type", whisper_model_type_readable(ctx));
|
||||
value_b("multilingual", whisper_is_multilingual(ctx));
|
||||
value_i("vocab", whisper_model_n_vocab(ctx));
|
||||
start_obj("audio");
|
||||
value_i("ctx", whisper_model_n_audio_ctx(ctx));
|
||||
value_i("state", whisper_model_n_audio_state(ctx));
|
||||
value_i("head", whisper_model_n_audio_head(ctx));
|
||||
value_i("layer", whisper_model_n_audio_layer(ctx), true);
|
||||
end_obj();
|
||||
start_obj("text");
|
||||
value_i("ctx", whisper_model_n_text_ctx(ctx));
|
||||
value_i("state", whisper_model_n_text_state(ctx));
|
||||
value_i("head", whisper_model_n_text_head(ctx));
|
||||
value_i("layer", whisper_model_n_text_layer(ctx), true);
|
||||
end_obj();
|
||||
value_i("mels", whisper_model_n_mels(ctx));
|
||||
value_i("ftype", whisper_model_ftype(ctx), true);
|
||||
end_obj();
|
||||
start_obj("params");
|
||||
value_s("model", params.model.c_str());
|
||||
value_s("language", params.language.c_str());
|
||||
value_b("translate", params.translate, true);
|
||||
end_obj();
|
||||
start_obj("result");
|
||||
value_s("language", whisper_lang_str(whisper_full_lang_id(ctx)), true);
|
||||
end_obj();
|
||||
start_arr("transcription");
|
||||
|
||||
const int n_segments = whisper_full_n_segments(ctx);
|
||||
for (int i = 0; i < n_segments; ++i) {
|
||||
const char * text = whisper_full_get_segment_text(ctx, i);
|
||||
const int64_t t0 = whisper_full_get_segment_t0(ctx, i);
|
||||
const int64_t t1 = whisper_full_get_segment_t1(ctx, i);
|
||||
|
||||
start_obj();
|
||||
start_obj("timestamps");
|
||||
value_s("from", to_timestamp(t0, true).c_str());
|
||||
value_s("to", to_timestamp(t1, true).c_str(), true);
|
||||
end_obj();
|
||||
start_obj("offsets");
|
||||
value_i("from", t0 * 10);
|
||||
value_i("to", t1 * 10, true);
|
||||
end_obj();
|
||||
value_s("text", text, true);
|
||||
end_obj(i == (n_segments - 1));
|
||||
}
|
||||
|
||||
end_arr(true);
|
||||
end_obj(true);
|
||||
return true;
|
||||
}
|
||||
|
||||
// karaoke video generation
|
||||
// outputs a bash script that uses ffmpeg to generate a video with the subtitles
|
||||
// TODO: font parameter adjustments
|
||||
bool output_wts(struct whisper_context * ctx, const char * fname, const char * fname_inp, const whisper_params & params, float t_sec) {
|
||||
std::ofstream fout(fname);
|
||||
|
||||
fprintf(stderr, "%s: saving output to '%s'\n", __func__, fname);
|
||||
|
||||
static const char * font = params.font_path.c_str();
|
||||
|
||||
std::ifstream fin(font);
|
||||
if (!fin.is_open()) {
|
||||
fprintf(stderr, "%s: font not found at '%s', please specify a monospace font with -fp\n", __func__, font);
|
||||
return false;
|
||||
}
|
||||
|
||||
fout << "#!/bin/bash" << "\n";
|
||||
fout << "\n";
|
||||
|
||||
fout << "ffmpeg -i " << fname_inp << " -f lavfi -i color=size=1200x120:duration=" << t_sec << ":rate=25:color=black -vf \"";
|
||||
|
||||
for (int i = 0; i < whisper_full_n_segments(ctx); i++) {
|
||||
const int64_t t0 = whisper_full_get_segment_t0(ctx, i);
|
||||
const int64_t t1 = whisper_full_get_segment_t1(ctx, i);
|
||||
|
||||
const int n = whisper_full_n_tokens(ctx, i);
|
||||
|
||||
std::vector<whisper_token_data> tokens(n);
|
||||
for (int j = 0; j < n; ++j) {
|
||||
tokens[j] = whisper_full_get_token_data(ctx, i, j);
|
||||
}
|
||||
|
||||
if (i > 0) {
|
||||
fout << ",";
|
||||
}
|
||||
|
||||
// background text
|
||||
fout << "drawtext=fontfile='" << font << "':fontsize=24:fontcolor=gray:x=(w-text_w)/2:y=h/2:text='':enable='between(t," << t0/100.0 << "," << t0/100.0 << ")'";
|
||||
|
||||
bool is_first = true;
|
||||
|
||||
for (int j = 0; j < n; ++j) {
|
||||
const auto & token = tokens[j];
|
||||
|
||||
if (tokens[j].id >= whisper_token_eot(ctx)) {
|
||||
continue;
|
||||
}
|
||||
|
||||
std::string txt_bg;
|
||||
std::string txt_fg; // highlight token
|
||||
std::string txt_ul; // underline
|
||||
|
||||
txt_bg = "> ";
|
||||
txt_fg = "> ";
|
||||
txt_ul = "\\ \\ ";
|
||||
|
||||
{
|
||||
for (int k = 0; k < n; ++k) {
|
||||
const auto & token2 = tokens[k];
|
||||
|
||||
if (tokens[k].id >= whisper_token_eot(ctx)) {
|
||||
continue;
|
||||
}
|
||||
|
||||
const std::string txt = whisper_token_to_str(ctx, token2.id);
|
||||
|
||||
txt_bg += txt;
|
||||
|
||||
if (k == j) {
|
||||
for (int l = 0; l < (int) txt.size(); ++l) {
|
||||
txt_fg += txt[l];
|
||||
txt_ul += "_";
|
||||
}
|
||||
txt_fg += "|";
|
||||
} else {
|
||||
for (int l = 0; l < (int) txt.size(); ++l) {
|
||||
txt_fg += "\\ ";
|
||||
txt_ul += "\\ ";
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
::replace_all(txt_bg, "'", "\u2019");
|
||||
::replace_all(txt_bg, "\"", "\\\"");
|
||||
::replace_all(txt_fg, "'", "\u2019");
|
||||
::replace_all(txt_fg, "\"", "\\\"");
|
||||
}
|
||||
|
||||
if (is_first) {
|
||||
// background text
|
||||
fout << ",drawtext=fontfile='" << font << "':fontsize=24:fontcolor=gray:x=(w-text_w)/2:y=h/2:text='" << txt_bg << "':enable='between(t," << t0/100.0 << "," << t1/100.0 << ")'";
|
||||
is_first = false;
|
||||
}
|
||||
|
||||
// foreground text
|
||||
fout << ",drawtext=fontfile='" << font << "':fontsize=24:fontcolor=lightgreen:x=(w-text_w)/2+8:y=h/2:text='" << txt_fg << "':enable='between(t," << token.t0/100.0 << "," << token.t1/100.0 << ")'";
|
||||
|
||||
// underline
|
||||
fout << ",drawtext=fontfile='" << font << "':fontsize=24:fontcolor=lightgreen:x=(w-text_w)/2+8:y=h/2+16:text='" << txt_ul << "':enable='between(t," << token.t0/100.0 << "," << token.t1/100.0 << ")'";
|
||||
}
|
||||
}
|
||||
|
||||
fout << "\" -c:v libx264 -pix_fmt yuv420p -y " << fname_inp << ".mp4" << "\n";
|
||||
|
||||
fout << "\n\n";
|
||||
fout << "echo \"Your video has been saved to " << fname_inp << ".mp4\"" << "\n";
|
||||
fout << "\n";
|
||||
fout << "echo \" ffplay " << fname_inp << ".mp4\"\n";
|
||||
fout << "\n";
|
||||
|
||||
fout.close();
|
||||
|
||||
fprintf(stderr, "%s: run 'source %s' to generate karaoke video\n", __func__, fname);
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
bool output_lrc(struct whisper_context * ctx, const char * fname) {
|
||||
|
||||
std::ofstream fout(fname);
|
||||
if (!fout.is_open()) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname);
|
||||
return false;
|
||||
}
|
||||
|
||||
fprintf(stderr, "%s: saving output to '%s'\n", __func__, fname);
|
||||
|
||||
fout << "[by:whisper.cpp]\n";
|
||||
|
||||
const int n_segments = whisper_full_n_segments(ctx);
|
||||
for (int i = 0; i < n_segments; ++i) {
|
||||
const char * text = whisper_full_get_segment_text(ctx, i);
|
||||
const int64_t t = whisper_full_get_segment_t0(ctx, i);
|
||||
|
||||
int64_t msec = t * 10;
|
||||
int64_t min = msec / (1000 * 60);
|
||||
msec = msec - min * (1000 * 60);
|
||||
int64_t sec = msec / 1000;
|
||||
msec = msec - sec * 1000;
|
||||
|
||||
char buf[16];
|
||||
snprintf(buf, sizeof(buf), "%02d:%02d.%02d", (int) min, (int) sec, (int) ( msec / 10));
|
||||
std::string timestamp_lrc = std::string(buf);
|
||||
|
||||
fout << '[' << timestamp_lrc << ']' << text << "\n";
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
int main(int argc, char ** argv) {
|
||||
whisper_params params;
|
||||
|
||||
if (whisper_params_parse(argc, argv, params) == false) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
if (params.fname_inp.empty()) {
|
||||
fprintf(stderr, "error: no input files specified\n");
|
||||
whisper_print_usage(argc, argv, params);
|
||||
return 2;
|
||||
}
|
||||
|
||||
if (params.language != "auto" && whisper_lang_id(params.language.c_str()) == -1) {
|
||||
fprintf(stderr, "error: unknown language '%s'\n", params.language.c_str());
|
||||
whisper_print_usage(argc, argv, params);
|
||||
exit(0);
|
||||
}
|
||||
|
||||
// whisper init
|
||||
|
||||
struct whisper_context * ctx = whisper_init_from_file(params.model.c_str());
|
||||
|
||||
if (ctx == nullptr) {
|
||||
fprintf(stderr, "error: failed to initialize whisper context\n");
|
||||
return 3;
|
||||
}
|
||||
|
||||
for (int f = 0; f < (int) params.fname_inp.size(); ++f) {
|
||||
const auto fname_inp = params.fname_inp[f];
|
||||
const auto fname_out = f < (int) params.fname_out.size() && !params.fname_out[f].empty() ? params.fname_out[f] : params.fname_inp[f];
|
||||
|
||||
std::vector<float> pcmf32; // mono-channel F32 PCM
|
||||
std::vector<std::vector<float>> pcmf32s; // stereo-channel F32 PCM
|
||||
|
||||
if (!::read_wav(fname_inp, pcmf32, pcmf32s, params.diarize)) {
|
||||
fprintf(stderr, "error: failed to read WAV file '%s'\n", fname_inp.c_str());
|
||||
continue;
|
||||
}
|
||||
|
||||
// print system information
|
||||
{
|
||||
fprintf(stderr, "\n");
|
||||
fprintf(stderr, "system_info: n_threads = %d / %d | %s\n",
|
||||
params.n_threads*params.n_processors, std::thread::hardware_concurrency(), whisper_print_system_info());
|
||||
}
|
||||
|
||||
// print some info about the processing
|
||||
{
|
||||
fprintf(stderr, "\n");
|
||||
if (!whisper_is_multilingual(ctx)) {
|
||||
if (params.language != "en" || params.translate) {
|
||||
params.language = "en";
|
||||
params.translate = false;
|
||||
fprintf(stderr, "%s: WARNING: model is not multilingual, ignoring language and translation options\n", __func__);
|
||||
}
|
||||
}
|
||||
if (params.detect_language) {
|
||||
params.language = "auto";
|
||||
}
|
||||
fprintf(stderr, "%s: processing '%s' (%d samples, %.1f sec), %d threads, %d processors, lang = %s, task = %s, timestamps = %d ...\n",
|
||||
__func__, fname_inp.c_str(), int(pcmf32.size()), float(pcmf32.size())/WHISPER_SAMPLE_RATE,
|
||||
params.n_threads, params.n_processors,
|
||||
params.language.c_str(),
|
||||
params.translate ? "translate" : "transcribe",
|
||||
params.no_timestamps ? 0 : 1);
|
||||
|
||||
fprintf(stderr, "\n");
|
||||
}
|
||||
|
||||
// run the inference
|
||||
{
|
||||
whisper_full_params wparams = whisper_full_default_params(WHISPER_SAMPLING_GREEDY);
|
||||
|
||||
wparams.strategy = params.beam_size > 1 ? WHISPER_SAMPLING_BEAM_SEARCH : WHISPER_SAMPLING_GREEDY;
|
||||
|
||||
wparams.print_realtime = false;
|
||||
wparams.print_progress = params.print_progress;
|
||||
wparams.print_timestamps = !params.no_timestamps;
|
||||
wparams.print_special = params.print_special;
|
||||
wparams.translate = params.translate;
|
||||
wparams.language = params.language.c_str();
|
||||
wparams.detect_language = params.detect_language;
|
||||
wparams.n_threads = params.n_threads;
|
||||
wparams.n_max_text_ctx = params.max_context >= 0 ? params.max_context : wparams.n_max_text_ctx;
|
||||
wparams.offset_ms = params.offset_t_ms;
|
||||
wparams.duration_ms = params.duration_ms;
|
||||
|
||||
wparams.token_timestamps = params.output_wts || params.max_len > 0;
|
||||
wparams.thold_pt = params.word_thold;
|
||||
wparams.max_len = params.output_wts && params.max_len == 0 ? 60 : params.max_len;
|
||||
wparams.split_on_word = params.split_on_word;
|
||||
|
||||
wparams.speed_up = params.speed_up;
|
||||
|
||||
wparams.initial_prompt = params.prompt.c_str();
|
||||
|
||||
wparams.greedy.best_of = params.best_of;
|
||||
wparams.beam_search.beam_size = params.beam_size;
|
||||
|
||||
wparams.temperature_inc = params.no_fallback ? 0.0f : wparams.temperature_inc;
|
||||
wparams.entropy_thold = params.entropy_thold;
|
||||
wparams.logprob_thold = params.logprob_thold;
|
||||
|
||||
whisper_print_user_data user_data = { ¶ms, &pcmf32s };
|
||||
|
||||
// this callback is called on each new segment
|
||||
if (!wparams.print_realtime) {
|
||||
wparams.new_segment_callback = whisper_print_segment_callback;
|
||||
wparams.new_segment_callback_user_data = &user_data;
|
||||
}
|
||||
|
||||
// example for abort mechanism
|
||||
// in this example, we do not abort the processing, but we could if the flag is set to true
|
||||
// the callback is called before every encoder run - if it returns false, the processing is aborted
|
||||
{
|
||||
static bool is_aborted = false; // NOTE: this should be atomic to avoid data race
|
||||
|
||||
wparams.encoder_begin_callback = [](struct whisper_context * /*ctx*/, struct whisper_state * /*state*/, void * user_data) {
|
||||
bool is_aborted = *(bool*)user_data;
|
||||
return !is_aborted;
|
||||
};
|
||||
wparams.encoder_begin_callback_user_data = &is_aborted;
|
||||
}
|
||||
|
||||
if (whisper_full_parallel(ctx, wparams, pcmf32.data(), pcmf32.size(), params.n_processors) != 0) {
|
||||
fprintf(stderr, "%s: failed to process audio\n", argv[0]);
|
||||
return 10;
|
||||
}
|
||||
}
|
||||
|
||||
// output stuff
|
||||
{
|
||||
printf("\n");
|
||||
|
||||
// output to text file
|
||||
if (params.output_txt) {
|
||||
const auto fname_txt = fname_out + ".txt";
|
||||
output_txt(ctx, fname_txt.c_str());
|
||||
}
|
||||
|
||||
// output to VTT file
|
||||
if (params.output_vtt) {
|
||||
const auto fname_vtt = fname_out + ".vtt";
|
||||
output_vtt(ctx, fname_vtt.c_str());
|
||||
}
|
||||
|
||||
// output to SRT file
|
||||
if (params.output_srt) {
|
||||
const auto fname_srt = fname_out + ".srt";
|
||||
output_srt(ctx, fname_srt.c_str(), params);
|
||||
}
|
||||
|
||||
// output to WTS file
|
||||
if (params.output_wts) {
|
||||
const auto fname_wts = fname_out + ".wts";
|
||||
output_wts(ctx, fname_wts.c_str(), fname_inp.c_str(), params, float(pcmf32.size() + 1000)/WHISPER_SAMPLE_RATE);
|
||||
}
|
||||
|
||||
// output to CSV file
|
||||
if (params.output_csv) {
|
||||
const auto fname_csv = fname_out + ".csv";
|
||||
output_csv(ctx, fname_csv.c_str());
|
||||
}
|
||||
|
||||
// output to JSON file
|
||||
if (params.output_jsn) {
|
||||
const auto fname_jsn = fname_out + ".json";
|
||||
output_json(ctx, fname_jsn.c_str(), params);
|
||||
}
|
||||
|
||||
// output to LRC file
|
||||
if (params.output_lrc) {
|
||||
const auto fname_lrc = fname_out + ".lrc";
|
||||
output_lrc(ctx, fname_lrc.c_str());
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
whisper_print_timings(ctx);
|
||||
whisper_free(ctx);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,221 @@
|
|||
#include "ggml.h"
|
||||
|
||||
#include "common.h"
|
||||
#include "common-ggml.h"
|
||||
|
||||
#include <cassert>
|
||||
#include <cmath>
|
||||
#include <cstdio>
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <map>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <regex>
|
||||
|
||||
// default hparams (Whisper tiny)
|
||||
struct whisper_hparams {
|
||||
int32_t n_vocab = 51864;
|
||||
int32_t n_audio_ctx = 1500;
|
||||
int32_t n_audio_state = 384;
|
||||
int32_t n_audio_head = 6;
|
||||
int32_t n_audio_layer = 4;
|
||||
int32_t n_text_ctx = 448;
|
||||
int32_t n_text_state = 384;
|
||||
int32_t n_text_head = 6;
|
||||
int32_t n_text_layer = 4;
|
||||
int32_t n_mels = 80;
|
||||
int32_t ftype = 1;
|
||||
};
|
||||
|
||||
struct whisper_filters {
|
||||
int32_t n_mel;
|
||||
int32_t n_fft;
|
||||
|
||||
std::vector<float> data;
|
||||
};
|
||||
|
||||
// quantize a model
|
||||
bool whisper_model_quantize(const std::string & fname_inp, const std::string & fname_out, ggml_ftype ftype) {
|
||||
gpt_vocab vocab;
|
||||
|
||||
printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str());
|
||||
|
||||
auto finp = std::ifstream(fname_inp, std::ios::binary);
|
||||
if (!finp) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
auto fout = std::ofstream(fname_out, std::ios::binary);
|
||||
if (!fout) {
|
||||
fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname_out.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
// verify magic
|
||||
{
|
||||
uint32_t magic;
|
||||
finp.read((char *) &magic, sizeof(magic));
|
||||
if (magic != 0x67676d6c) {
|
||||
fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
fout.write((char *) &magic, sizeof(magic));
|
||||
}
|
||||
|
||||
whisper_hparams hparams;
|
||||
|
||||
// load hparams
|
||||
{
|
||||
finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
finp.read((char *) &hparams.n_audio_ctx, sizeof(hparams.n_audio_ctx));
|
||||
finp.read((char *) &hparams.n_audio_state, sizeof(hparams.n_audio_state));
|
||||
finp.read((char *) &hparams.n_audio_head, sizeof(hparams.n_audio_head));
|
||||
finp.read((char *) &hparams.n_audio_layer, sizeof(hparams.n_audio_layer));
|
||||
finp.read((char *) &hparams.n_text_ctx, sizeof(hparams.n_text_ctx));
|
||||
finp.read((char *) &hparams.n_text_state, sizeof(hparams.n_text_state));
|
||||
finp.read((char *) &hparams.n_text_head, sizeof(hparams.n_text_head));
|
||||
finp.read((char *) &hparams.n_text_layer, sizeof(hparams.n_text_layer));
|
||||
finp.read((char *) &hparams.n_mels, sizeof(hparams.n_mels));
|
||||
finp.read((char *) &hparams.ftype, sizeof(hparams.ftype));
|
||||
|
||||
const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR;
|
||||
const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype;
|
||||
|
||||
fprintf(stderr, "%s: n_vocab = %d\n", __func__, hparams.n_vocab);
|
||||
fprintf(stderr, "%s: n_audio_ctx = %d\n", __func__, hparams.n_audio_ctx);
|
||||
fprintf(stderr, "%s: n_audio_state = %d\n", __func__, hparams.n_audio_state);
|
||||
fprintf(stderr, "%s: n_audio_head = %d\n", __func__, hparams.n_audio_head);
|
||||
fprintf(stderr, "%s: n_audio_layer = %d\n", __func__, hparams.n_audio_layer);
|
||||
fprintf(stderr, "%s: n_text_ctx = %d\n", __func__, hparams.n_text_ctx);
|
||||
fprintf(stderr, "%s: n_text_state = %d\n", __func__, hparams.n_text_state);
|
||||
fprintf(stderr, "%s: n_text_head = %d\n", __func__, hparams.n_text_head);
|
||||
fprintf(stderr, "%s: n_text_layer = %d\n", __func__, hparams.n_text_layer);
|
||||
fprintf(stderr, "%s: n_mels = %d\n", __func__, hparams.n_mels);
|
||||
fprintf(stderr, "%s: ftype (src) = %d\n", __func__, hparams.ftype);
|
||||
fprintf(stderr, "%s: qntvr (src) = %d\n", __func__, qntvr_src);
|
||||
fprintf(stderr, "%s: ftype (dst) = %d\n", __func__, ftype_dst);
|
||||
fprintf(stderr, "%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION);
|
||||
|
||||
fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab));
|
||||
fout.write((char *) &hparams.n_audio_ctx, sizeof(hparams.n_audio_ctx));
|
||||
fout.write((char *) &hparams.n_audio_state, sizeof(hparams.n_audio_state));
|
||||
fout.write((char *) &hparams.n_audio_head, sizeof(hparams.n_audio_head));
|
||||
fout.write((char *) &hparams.n_audio_layer, sizeof(hparams.n_audio_layer));
|
||||
fout.write((char *) &hparams.n_text_ctx, sizeof(hparams.n_text_ctx));
|
||||
fout.write((char *) &hparams.n_text_state, sizeof(hparams.n_text_state));
|
||||
fout.write((char *) &hparams.n_text_head, sizeof(hparams.n_text_head));
|
||||
fout.write((char *) &hparams.n_text_layer, sizeof(hparams.n_text_layer));
|
||||
fout.write((char *) &hparams.n_mels, sizeof(hparams.n_mels));
|
||||
fout.write((char *) &ftype_dst, sizeof(hparams.ftype));
|
||||
}
|
||||
|
||||
// load mel filters
|
||||
{
|
||||
whisper_filters filters;
|
||||
|
||||
finp.read ((char *) &filters.n_mel, sizeof(filters.n_mel));
|
||||
fout.write((char *) &filters.n_mel, sizeof(filters.n_mel));
|
||||
finp.read ((char *) &filters.n_fft, sizeof(filters.n_fft));
|
||||
fout.write((char *) &filters.n_fft, sizeof(filters.n_fft));
|
||||
|
||||
filters.data.resize(filters.n_mel * filters.n_fft);
|
||||
finp.read ((char *) filters.data.data(), filters.data.size() * sizeof(float));
|
||||
fout.write((char *) filters.data.data(), filters.data.size() * sizeof(float));
|
||||
}
|
||||
|
||||
// load vocab
|
||||
{
|
||||
int32_t n_vocab = 0;
|
||||
finp.read ((char *) &n_vocab, sizeof(n_vocab));
|
||||
fout.write((char *) &n_vocab, sizeof(n_vocab));
|
||||
|
||||
//if (n_vocab != hparams.n_vocab) {
|
||||
// fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n",
|
||||
// __func__, fname_inp.c_str(), n_vocab, hparams.n_vocab);
|
||||
// return false;
|
||||
//}
|
||||
|
||||
std::string word;
|
||||
for (int i = 0; i < n_vocab; i++) {
|
||||
uint32_t len;
|
||||
finp.read ((char *) &len, sizeof(len));
|
||||
fout.write((char *) &len, sizeof(len));
|
||||
|
||||
word.resize(len);
|
||||
finp.read ((char *) word.data(), len);
|
||||
fout.write((char *) word.data(), len);
|
||||
|
||||
vocab.token_to_id[word] = i;
|
||||
vocab.id_to_token[i] = word;
|
||||
}
|
||||
}
|
||||
|
||||
// regexes of tensor names to not be quantized
|
||||
const std::vector<std::string> to_skip = {
|
||||
//"encoder.*",
|
||||
"encoder.conv1.bias",
|
||||
"encoder.conv2.bias",
|
||||
"encoder.positional_embedding",
|
||||
"decoder.positional_embedding",
|
||||
};
|
||||
|
||||
if (!ggml_common_quantize_0(finp, fout, ftype, { ".*" }, to_skip)) {
|
||||
fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__, fname_inp.c_str());
|
||||
return false;
|
||||
}
|
||||
|
||||
finp.close();
|
||||
fout.close();
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
int main(int argc, char ** argv) {
|
||||
if (argc != 4) {
|
||||
fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n", argv[0]);
|
||||
ggml_print_ftypes(stderr);
|
||||
return 1;
|
||||
}
|
||||
|
||||
// needed to initialize f16 tables
|
||||
{
|
||||
struct ggml_init_params params = { 0, NULL, false };
|
||||
struct ggml_context * ctx = ggml_init(params);
|
||||
ggml_free(ctx);
|
||||
}
|
||||
|
||||
const std::string fname_inp = argv[1];
|
||||
const std::string fname_out = argv[2];
|
||||
|
||||
const ggml_ftype ftype = ggml_parse_ftype(argv[3]);
|
||||
|
||||
const int64_t t_main_start_us = ggml_time_us();
|
||||
|
||||
int64_t t_quantize_us = 0;
|
||||
|
||||
// load the model
|
||||
{
|
||||
const int64_t t_start_us = ggml_time_us();
|
||||
|
||||
if (!whisper_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) {
|
||||
fprintf(stderr, "%s: failed to quantize model from '%s'\n", __func__, fname_inp.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
t_quantize_us = ggml_time_us() - t_start_us;
|
||||
}
|
||||
|
||||
// report timing
|
||||
{
|
||||
const int64_t t_main_end_us = ggml_time_us();
|
||||
|
||||
printf("\n");
|
||||
printf("%s: quantize time = %8.2f ms\n", __func__, t_quantize_us/1000.0f);
|
||||
printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,497 @@
|
|||
#ifndef WHISPER_H
|
||||
#define WHISPER_H
|
||||
|
||||
#include <stddef.h>
|
||||
#include <stdint.h>
|
||||
#include <stdbool.h>
|
||||
|
||||
#ifdef WHISPER_SHARED
|
||||
# ifdef _WIN32
|
||||
# ifdef WHISPER_BUILD
|
||||
# define WHISPER_API __declspec(dllexport)
|
||||
# else
|
||||
# define WHISPER_API __declspec(dllimport)
|
||||
# endif
|
||||
# else
|
||||
# define WHISPER_API __attribute__ ((visibility ("default")))
|
||||
# endif
|
||||
#else
|
||||
# define WHISPER_API
|
||||
#endif
|
||||
|
||||
#define WHISPER_SAMPLE_RATE 16000
|
||||
#define WHISPER_N_FFT 400
|
||||
#define WHISPER_N_MEL 80
|
||||
#define WHISPER_HOP_LENGTH 160
|
||||
#define WHISPER_CHUNK_SIZE 30
|
||||
|
||||
#ifdef __cplusplus
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
//
|
||||
// C interface
|
||||
//
|
||||
// The following interface is thread-safe as long as the sample whisper_context is not used by multiple threads
|
||||
// concurrently.
|
||||
//
|
||||
// Basic usage:
|
||||
//
|
||||
// #include "whisper.h"
|
||||
//
|
||||
// ...
|
||||
//
|
||||
// struct whisper_context * ctx = whisper_init_from_file("/path/to/ggml-base.en.bin");
|
||||
//
|
||||
// if (whisper_full(ctx, wparams, pcmf32.data(), pcmf32.size()) != 0) {
|
||||
// fprintf(stderr, "failed to process audio\n");
|
||||
// return 7;
|
||||
// }
|
||||
//
|
||||
// const int n_segments = whisper_full_n_segments(ctx);
|
||||
// for (int i = 0; i < n_segments; ++i) {
|
||||
// const char * text = whisper_full_get_segment_text(ctx, i);
|
||||
// printf("%s", text);
|
||||
// }
|
||||
//
|
||||
// whisper_free(ctx);
|
||||
//
|
||||
// ...
|
||||
//
|
||||
// This is a demonstration of the most straightforward usage of the library.
|
||||
// "pcmf32" contains the RAW audio data in 32-bit floating point format.
|
||||
//
|
||||
// The interface also allows for more fine-grained control over the computation, but it requires a deeper
|
||||
// understanding of how the model works.
|
||||
//
|
||||
|
||||
struct whisper_context;
|
||||
struct whisper_state;
|
||||
|
||||
typedef int whisper_token;
|
||||
|
||||
typedef struct whisper_token_data {
|
||||
whisper_token id; // token id
|
||||
whisper_token tid; // forced timestamp token id
|
||||
|
||||
float p; // probability of the token
|
||||
float plog; // log probability of the token
|
||||
float pt; // probability of the timestamp token
|
||||
float ptsum; // sum of probabilities of all timestamp tokens
|
||||
|
||||
// token-level timestamp data
|
||||
// do not use if you haven't computed token-level timestamps
|
||||
int64_t t0; // start time of the token
|
||||
int64_t t1; // end time of the token
|
||||
|
||||
float vlen; // voice length of the token
|
||||
} whisper_token_data;
|
||||
|
||||
typedef struct whisper_model_loader {
|
||||
void * context;
|
||||
|
||||
size_t (*read)(void * ctx, void * output, size_t read_size);
|
||||
bool (*eof)(void * ctx);
|
||||
void (*close)(void * ctx);
|
||||
} whisper_model_loader;
|
||||
|
||||
// Various functions for loading a ggml whisper model.
|
||||
// Allocate (almost) all memory needed for the model.
|
||||
// Return NULL on failure
|
||||
WHISPER_API struct whisper_context * whisper_init_from_file(const char * path_model);
|
||||
WHISPER_API struct whisper_context * whisper_init_from_buffer(void * buffer, size_t buffer_size);
|
||||
WHISPER_API struct whisper_context * whisper_init(struct whisper_model_loader * loader);
|
||||
|
||||
// These are the same as the above, but the internal state of the context is not allocated automatically
|
||||
// It is the responsibility of the caller to allocate the state using whisper_init_state() (#523)
|
||||
WHISPER_API struct whisper_context * whisper_init_from_file_no_state(const char * path_model);
|
||||
WHISPER_API struct whisper_context * whisper_init_from_buffer_no_state(void * buffer, size_t buffer_size);
|
||||
WHISPER_API struct whisper_context * whisper_init_no_state(struct whisper_model_loader * loader);
|
||||
|
||||
WHISPER_API struct whisper_state * whisper_init_state(struct whisper_context * ctx);
|
||||
|
||||
// Frees all allocated memory
|
||||
WHISPER_API void whisper_free (struct whisper_context * ctx);
|
||||
WHISPER_API void whisper_free_state(struct whisper_state * state);
|
||||
|
||||
// Convert RAW PCM audio to log mel spectrogram.
|
||||
// The resulting spectrogram is stored inside the default state of the provided whisper context.
|
||||
// Returns 0 on success
|
||||
WHISPER_API int whisper_pcm_to_mel(
|
||||
struct whisper_context * ctx,
|
||||
const float * samples,
|
||||
int n_samples,
|
||||
int n_threads);
|
||||
|
||||
WHISPER_API int whisper_pcm_to_mel_with_state(
|
||||
struct whisper_context * ctx,
|
||||
struct whisper_state * state,
|
||||
const float * samples,
|
||||
int n_samples,
|
||||
int n_threads);
|
||||
|
||||
// Convert RAW PCM audio to log mel spectrogram but applies a Phase Vocoder to speed up the audio x2.
|
||||
// The resulting spectrogram is stored inside the default state of the provided whisper context.
|
||||
// Returns 0 on success
|
||||
WHISPER_API int whisper_pcm_to_mel_phase_vocoder(
|
||||
struct whisper_context * ctx,
|
||||
const float * samples,
|
||||
int n_samples,
|
||||
int n_threads);
|
||||
|
||||
WHISPER_API int whisper_pcm_to_mel_phase_vocoder_with_state(
|
||||
struct whisper_context * ctx,
|
||||
struct whisper_state * state,
|
||||
const float * samples,
|
||||
int n_samples,
|
||||
int n_threads);
|
||||
|
||||
// This can be used to set a custom log mel spectrogram inside the default state of the provided whisper context.
|
||||
// Use this instead of whisper_pcm_to_mel() if you want to provide your own log mel spectrogram.
|
||||
// n_mel must be 80
|
||||
// Returns 0 on success
|
||||
WHISPER_API int whisper_set_mel(
|
||||
struct whisper_context * ctx,
|
||||
const float * data,
|
||||
int n_len,
|
||||
int n_mel);
|
||||
|
||||
WHISPER_API int whisper_set_mel_with_state(
|
||||
struct whisper_context * ctx,
|
||||
struct whisper_state * state,
|
||||
const float * data,
|
||||
int n_len,
|
||||
int n_mel);
|
||||
|
||||
// Run the Whisper encoder on the log mel spectrogram stored inside the default state in the provided whisper context.
|
||||
// Make sure to call whisper_pcm_to_mel() or whisper_set_mel() first.
|
||||
// offset can be used to specify the offset of the first frame in the spectrogram.
|
||||
// Returns 0 on success
|
||||
WHISPER_API int whisper_encode(
|
||||
struct whisper_context * ctx,
|
||||
int offset,
|
||||
int n_threads);
|
||||
|
||||
WHISPER_API int whisper_encode_with_state(
|
||||
struct whisper_context * ctx,
|
||||
struct whisper_state * state,
|
||||
int offset,
|
||||
int n_threads);
|
||||
|
||||
// Run the Whisper decoder to obtain the logits and probabilities for the next token.
|
||||
// Make sure to call whisper_encode() first.
|
||||
// tokens + n_tokens is the provided context for the decoder.
|
||||
// n_past is the number of tokens to use from previous decoder calls.
|
||||
// Returns 0 on success
|
||||
// TODO: add support for multiple decoders
|
||||
WHISPER_API int whisper_decode(
|
||||
struct whisper_context * ctx,
|
||||
const whisper_token * tokens,
|
||||
int n_tokens,
|
||||
int n_past,
|
||||
int n_threads);
|
||||
|
||||
WHISPER_API int whisper_decode_with_state(
|
||||
struct whisper_context * ctx,
|
||||
struct whisper_state * state,
|
||||
const whisper_token * tokens,
|
||||
int n_tokens,
|
||||
int n_past,
|
||||
int n_threads);
|
||||
|
||||
// Convert the provided text into tokens.
|
||||
// The tokens pointer must be large enough to hold the resulting tokens.
|
||||
// Returns the number of tokens on success, no more than n_max_tokens
|
||||
// Returns -1 on failure
|
||||
// TODO: not sure if correct
|
||||
WHISPER_API int whisper_tokenize(
|
||||
struct whisper_context * ctx,
|
||||
const char * text,
|
||||
whisper_token * tokens,
|
||||
int n_max_tokens);
|
||||
|
||||
// Largest language id (i.e. number of available languages - 1)
|
||||
WHISPER_API int whisper_lang_max_id();
|
||||
|
||||
// Return the id of the specified language, returns -1 if not found
|
||||
// Examples:
|
||||
// "de" -> 2
|
||||
// "german" -> 2
|
||||
WHISPER_API int whisper_lang_id(const char * lang);
|
||||
|
||||
// Return the short string of the specified language id (e.g. 2 -> "de"), returns nullptr if not found
|
||||
WHISPER_API const char * whisper_lang_str(int id);
|
||||
|
||||
// Use mel data at offset_ms to try and auto-detect the spoken language
|
||||
// Make sure to call whisper_pcm_to_mel() or whisper_set_mel() first
|
||||
// Returns the top language id or negative on failure
|
||||
// If not null, fills the lang_probs array with the probabilities of all languages
|
||||
// The array must be whisper_lang_max_id() + 1 in size
|
||||
// ref: https://github.com/openai/whisper/blob/main/whisper/decoding.py#L18-L69
|
||||
WHISPER_API int whisper_lang_auto_detect(
|
||||
struct whisper_context * ctx,
|
||||
int offset_ms,
|
||||
int n_threads,
|
||||
float * lang_probs);
|
||||
|
||||
WHISPER_API int whisper_lang_auto_detect_with_state(
|
||||
struct whisper_context * ctx,
|
||||
struct whisper_state * state,
|
||||
int offset_ms,
|
||||
int n_threads,
|
||||
float * lang_probs);
|
||||
|
||||
WHISPER_API int whisper_n_len (struct whisper_context * ctx); // mel length
|
||||
WHISPER_API int whisper_n_len_from_state(struct whisper_state * state); // mel length
|
||||
WHISPER_API int whisper_n_vocab (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_n_text_ctx (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_n_audio_ctx (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_is_multilingual (struct whisper_context * ctx);
|
||||
|
||||
WHISPER_API int whisper_model_n_vocab (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_model_n_audio_ctx (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_model_n_audio_state(struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_model_n_audio_head (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_model_n_audio_layer(struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_model_n_text_ctx (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_model_n_text_state (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_model_n_text_head (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_model_n_text_layer (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_model_n_mels (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_model_ftype (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_model_type (struct whisper_context * ctx);
|
||||
|
||||
// Token logits obtained from the last call to whisper_decode()
|
||||
// The logits for the last token are stored in the last row
|
||||
// Rows: n_tokens
|
||||
// Cols: n_vocab
|
||||
WHISPER_API float * whisper_get_logits (struct whisper_context * ctx);
|
||||
WHISPER_API float * whisper_get_logits_from_state(struct whisper_state * state);
|
||||
|
||||
// Token Id -> String. Uses the vocabulary in the provided context
|
||||
WHISPER_API const char * whisper_token_to_str(struct whisper_context * ctx, whisper_token token);
|
||||
WHISPER_API const char * whisper_model_type_readable(struct whisper_context * ctx);
|
||||
|
||||
|
||||
// Special tokens
|
||||
WHISPER_API whisper_token whisper_token_eot (struct whisper_context * ctx);
|
||||
WHISPER_API whisper_token whisper_token_sot (struct whisper_context * ctx);
|
||||
WHISPER_API whisper_token whisper_token_prev(struct whisper_context * ctx);
|
||||
WHISPER_API whisper_token whisper_token_solm(struct whisper_context * ctx);
|
||||
WHISPER_API whisper_token whisper_token_not (struct whisper_context * ctx);
|
||||
WHISPER_API whisper_token whisper_token_beg (struct whisper_context * ctx);
|
||||
WHISPER_API whisper_token whisper_token_lang(struct whisper_context * ctx, int lang_id);
|
||||
|
||||
// Task tokens
|
||||
WHISPER_API whisper_token whisper_token_translate (void);
|
||||
WHISPER_API whisper_token whisper_token_transcribe(void);
|
||||
|
||||
// Performance information from the default state.
|
||||
WHISPER_API void whisper_print_timings(struct whisper_context * ctx);
|
||||
WHISPER_API void whisper_reset_timings(struct whisper_context * ctx);
|
||||
|
||||
// Print system information
|
||||
WHISPER_API const char * whisper_print_system_info(void);
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
// Available sampling strategies
|
||||
enum whisper_sampling_strategy {
|
||||
WHISPER_SAMPLING_GREEDY, // similar to OpenAI's GreedyDecoder
|
||||
WHISPER_SAMPLING_BEAM_SEARCH, // similar to OpenAI's BeamSearchDecoder
|
||||
};
|
||||
|
||||
// Text segment callback
|
||||
// Called on every newly generated text segment
|
||||
// Use the whisper_full_...() functions to obtain the text segments
|
||||
typedef void (*whisper_new_segment_callback)(struct whisper_context * ctx, struct whisper_state * state, int n_new, void * user_data);
|
||||
|
||||
// Progress callback
|
||||
typedef void (*whisper_progress_callback)(struct whisper_context * ctx, struct whisper_state * state, int progress, void * user_data);
|
||||
|
||||
// Encoder begin callback
|
||||
// If not NULL, called before the encoder starts
|
||||
// If it returns false, the computation is aborted
|
||||
typedef bool (*whisper_encoder_begin_callback)(struct whisper_context * ctx, struct whisper_state * state, void * user_data);
|
||||
|
||||
// Logits filter callback
|
||||
// Can be used to modify the logits before sampling
|
||||
// If not NULL, called after applying temperature to logits
|
||||
typedef void (*whisper_logits_filter_callback)(
|
||||
struct whisper_context * ctx,
|
||||
struct whisper_state * state,
|
||||
const whisper_token_data * tokens,
|
||||
int n_tokens,
|
||||
float * logits,
|
||||
void * user_data);
|
||||
|
||||
// Parameters for the whisper_full() function
|
||||
// If you chnage the order or add new parameters, make sure to update the default values in whisper.cpp:
|
||||
// whisper_full_default_params()
|
||||
struct whisper_full_params {
|
||||
enum whisper_sampling_strategy strategy;
|
||||
|
||||
int n_threads;
|
||||
int n_max_text_ctx; // max tokens to use from past text as prompt for the decoder
|
||||
int offset_ms; // start offset in ms
|
||||
int duration_ms; // audio duration to process in ms
|
||||
|
||||
bool translate;
|
||||
bool no_context; // do not use past transcription (if any) as initial prompt for the decoder
|
||||
bool single_segment; // force single segment output (useful for streaming)
|
||||
bool print_special; // print special tokens (e.g. <SOT>, <EOT>, <BEG>, etc.)
|
||||
bool print_progress; // print progress information
|
||||
bool print_realtime; // print results from within whisper.cpp (avoid it, use callback instead)
|
||||
bool print_timestamps; // print timestamps for each text segment when printing realtime
|
||||
|
||||
// [EXPERIMENTAL] token-level timestamps
|
||||
bool token_timestamps; // enable token-level timestamps
|
||||
float thold_pt; // timestamp token probability threshold (~0.01)
|
||||
float thold_ptsum; // timestamp token sum probability threshold (~0.01)
|
||||
int max_len; // max segment length in characters
|
||||
bool split_on_word; // split on word rather than on token (when used with max_len)
|
||||
int max_tokens; // max tokens per segment (0 = no limit)
|
||||
|
||||
// [EXPERIMENTAL] speed-up techniques
|
||||
// note: these can significantly reduce the quality of the output
|
||||
bool speed_up; // speed-up the audio by 2x using Phase Vocoder
|
||||
int audio_ctx; // overwrite the audio context size (0 = use default)
|
||||
|
||||
// tokens to provide to the whisper decoder as initial prompt
|
||||
// these are prepended to any existing text context from a previous call
|
||||
const char * initial_prompt;
|
||||
const whisper_token * prompt_tokens;
|
||||
int prompt_n_tokens;
|
||||
|
||||
// for auto-detection, set to nullptr, "" or "auto"
|
||||
const char * language;
|
||||
bool detect_language;
|
||||
|
||||
// common decoding parameters:
|
||||
bool suppress_blank; // ref: https://github.com/openai/whisper/blob/f82bc59f5ea234d4b97fb2860842ed38519f7e65/whisper/decoding.py#L89
|
||||
bool suppress_non_speech_tokens; // ref: https://github.com/openai/whisper/blob/7858aa9c08d98f75575035ecd6481f462d66ca27/whisper/tokenizer.py#L224-L253
|
||||
|
||||
float temperature; // initial decoding temperature, ref: https://ai.stackexchange.com/a/32478
|
||||
float max_initial_ts; // ref: https://github.com/openai/whisper/blob/f82bc59f5ea234d4b97fb2860842ed38519f7e65/whisper/decoding.py#L97
|
||||
float length_penalty; // ref: https://github.com/openai/whisper/blob/f82bc59f5ea234d4b97fb2860842ed38519f7e65/whisper/transcribe.py#L267
|
||||
|
||||
// fallback parameters
|
||||
// ref: https://github.com/openai/whisper/blob/f82bc59f5ea234d4b97fb2860842ed38519f7e65/whisper/transcribe.py#L274-L278
|
||||
float temperature_inc;
|
||||
float entropy_thold; // similar to OpenAI's "compression_ratio_threshold"
|
||||
float logprob_thold;
|
||||
float no_speech_thold; // TODO: not implemented
|
||||
|
||||
struct {
|
||||
int best_of; // ref: https://github.com/openai/whisper/blob/f82bc59f5ea234d4b97fb2860842ed38519f7e65/whisper/transcribe.py#L264
|
||||
} greedy;
|
||||
|
||||
struct {
|
||||
int beam_size; // ref: https://github.com/openai/whisper/blob/f82bc59f5ea234d4b97fb2860842ed38519f7e65/whisper/transcribe.py#L265
|
||||
|
||||
float patience; // TODO: not implemented, ref: https://arxiv.org/pdf/2204.05424.pdf
|
||||
} beam_search;
|
||||
|
||||
// called for every newly generated text segment
|
||||
whisper_new_segment_callback new_segment_callback;
|
||||
void * new_segment_callback_user_data;
|
||||
|
||||
// called on each progress update
|
||||
whisper_progress_callback progress_callback;
|
||||
void * progress_callback_user_data;
|
||||
|
||||
// called each time before the encoder starts
|
||||
whisper_encoder_begin_callback encoder_begin_callback;
|
||||
void * encoder_begin_callback_user_data;
|
||||
|
||||
// called by each decoder to filter obtained logits
|
||||
whisper_logits_filter_callback logits_filter_callback;
|
||||
void * logits_filter_callback_user_data;
|
||||
};
|
||||
|
||||
WHISPER_API struct whisper_full_params whisper_full_default_params(enum whisper_sampling_strategy strategy);
|
||||
|
||||
// Run the entire model: PCM -> log mel spectrogram -> encoder -> decoder -> text
|
||||
// Not thread safe for same context
|
||||
// Uses the specified decoding strategy to obtain the text.
|
||||
WHISPER_API int whisper_full(
|
||||
struct whisper_context * ctx,
|
||||
struct whisper_full_params params,
|
||||
const float * samples,
|
||||
int n_samples);
|
||||
|
||||
WHISPER_API int whisper_full_with_state(
|
||||
struct whisper_context * ctx,
|
||||
struct whisper_state * state,
|
||||
struct whisper_full_params params,
|
||||
const float * samples,
|
||||
int n_samples);
|
||||
|
||||
// Split the input audio in chunks and process each chunk separately using whisper_full_with_state()
|
||||
// Result is stored in the default state of the context
|
||||
// Not thread safe if executed in parallel on the same context.
|
||||
// It seems this approach can offer some speedup in some cases.
|
||||
// However, the transcription accuracy can be worse at the beginning and end of each chunk.
|
||||
WHISPER_API int whisper_full_parallel(
|
||||
struct whisper_context * ctx,
|
||||
struct whisper_full_params params,
|
||||
const float * samples,
|
||||
int n_samples,
|
||||
int n_processors);
|
||||
|
||||
// Number of generated text segments
|
||||
// A segment can be a few words, a sentence, or even a paragraph.
|
||||
WHISPER_API int whisper_full_n_segments (struct whisper_context * ctx);
|
||||
WHISPER_API int whisper_full_n_segments_from_state(struct whisper_state * state);
|
||||
|
||||
// Language id associated with the context's default state
|
||||
WHISPER_API int whisper_full_lang_id(struct whisper_context * ctx);
|
||||
|
||||
// Language id associated with the provided state
|
||||
WHISPER_API int whisper_full_lang_id_from_state(struct whisper_state * state);
|
||||
|
||||
// Get the start and end time of the specified segment
|
||||
WHISPER_API int64_t whisper_full_get_segment_t0 (struct whisper_context * ctx, int i_segment);
|
||||
WHISPER_API int64_t whisper_full_get_segment_t0_from_state(struct whisper_state * state, int i_segment);
|
||||
|
||||
WHISPER_API int64_t whisper_full_get_segment_t1 (struct whisper_context * ctx, int i_segment);
|
||||
WHISPER_API int64_t whisper_full_get_segment_t1_from_state(struct whisper_state * state, int i_segment);
|
||||
|
||||
// Get the text of the specified segment
|
||||
WHISPER_API const char * whisper_full_get_segment_text (struct whisper_context * ctx, int i_segment);
|
||||
WHISPER_API const char * whisper_full_get_segment_text_from_state(struct whisper_state * state, int i_segment);
|
||||
|
||||
// Get number of tokens in the specified segment
|
||||
WHISPER_API int whisper_full_n_tokens (struct whisper_context * ctx, int i_segment);
|
||||
WHISPER_API int whisper_full_n_tokens_from_state(struct whisper_state * state, int i_segment);
|
||||
|
||||
// Get the token text of the specified token in the specified segment
|
||||
WHISPER_API const char * whisper_full_get_token_text (struct whisper_context * ctx, int i_segment, int i_token);
|
||||
WHISPER_API const char * whisper_full_get_token_text_from_state(struct whisper_context * ctx, struct whisper_state * state, int i_segment, int i_token);
|
||||
|
||||
WHISPER_API whisper_token whisper_full_get_token_id (struct whisper_context * ctx, int i_segment, int i_token);
|
||||
WHISPER_API whisper_token whisper_full_get_token_id_from_state(struct whisper_state * state, int i_segment, int i_token);
|
||||
|
||||
// Get token data for the specified token in the specified segment
|
||||
// This contains probabilities, timestamps, etc.
|
||||
WHISPER_API whisper_token_data whisper_full_get_token_data (struct whisper_context * ctx, int i_segment, int i_token);
|
||||
WHISPER_API whisper_token_data whisper_full_get_token_data_from_state(struct whisper_state * state, int i_segment, int i_token);
|
||||
|
||||
// Get the probability of the specified token in the specified segment
|
||||
WHISPER_API float whisper_full_get_token_p (struct whisper_context * ctx, int i_segment, int i_token);
|
||||
WHISPER_API float whisper_full_get_token_p_from_state(struct whisper_state * state, int i_segment, int i_token);
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////
|
||||
|
||||
// Temporary helpers needed for exposing ggml interface
|
||||
|
||||
WHISPER_API int whisper_bench_memcpy(int n_threads);
|
||||
WHISPER_API const char * whisper_bench_memcpy_str(int n_threads);
|
||||
WHISPER_API int whisper_bench_ggml_mul_mat(int n_threads);
|
||||
WHISPER_API const char * whisper_bench_ggml_mul_mat_str(int n_threads);
|
||||
|
||||
#ifdef __cplusplus
|
||||
}
|
||||
#endif
|
||||
|
||||
#endif
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,8 @@
|
|||
#!/bin/bash
|
||||
|
||||
cp -rpv ../llama.cpp/ggml.c src/ggml.c
|
||||
cp -rpv ../llama.cpp/ggml-cuda.h src/ggml-cuda.h
|
||||
cp -rpv ../llama.cpp/ggml-cuda.cu src/ggml-cuda.cu
|
||||
cp -rpv ../llama.cpp/ggml-opencl.h src/ggml-opencl.h
|
||||
cp -rpv ../llama.cpp/ggml-opencl.c src/ggml-opencl.c
|
||||
cp -rpv ../llama.cpp/ggml.h include/ggml/ggml.h
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
#!/bin/bash
|
||||
|
||||
cp -rpv ../whisper.cpp/ggml.c src/ggml.c
|
||||
cp -rpv ../whisper.cpp/ggml-cuda.h src/ggml-cuda.h
|
||||
cp -rpv ../whisper.cpp/ggml-cuda.cu src/ggml-cuda.cu
|
||||
cp -rpv ../whisper.cpp/ggml-opencl.h src/ggml-opencl.h
|
||||
cp -rpv ../whisper.cpp/ggml-opencl.c src/ggml-opencl.c
|
||||
cp -rpv ../whisper.cpp/ggml.h include/ggml/ggml.h
|
||||
cp -rpv ../whisper.cpp/examples/common.h examples/common.h
|
||||
cp -rpv ../whisper.cpp/examples/common.cpp examples/common.cpp
|
||||
cp -rpv ../whisper.cpp/examples/common-ggml.h examples/common-ggml.h
|
||||
cp -rpv ../whisper.cpp/examples/common-ggml.cpp examples/common-ggml.cpp
|
||||
cp -rpv ../whisper.cpp/whisper.h examples/whisper/whisper.h
|
||||
cp -rpv ../whisper.cpp/whisper.cpp examples/whisper/whisper.cpp
|
||||
cp -rpv ../whisper.cpp/examples/main/main.cpp examples/whisper/main.cpp
|
||||
cp -rpv ../whisper.cpp/examples/quantize/quantize.cpp examples/whisper/quantize.cpp
|
||||
|
|
@ -0,0 +1,241 @@
|
|||
if (GGML_ALL_WARNINGS)
|
||||
if (CMAKE_COMPILER_IS_GNUCC OR CMAKE_C_COMPILER_ID MATCHES "Clang")
|
||||
#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -Wall -Wextra")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} \
|
||||
-Wall \
|
||||
-Wextra \
|
||||
-Wpedantic \
|
||||
-Wshadow \
|
||||
-Wcast-qual \
|
||||
-Wstrict-prototypes \
|
||||
-Wpointer-arith \
|
||||
-Wdouble-promotion \
|
||||
-Wno-unused-function \
|
||||
")
|
||||
else()
|
||||
# todo : windows
|
||||
endif()
|
||||
endif()
|
||||
|
||||
# compiler flags
|
||||
|
||||
if (NOT MSVC)
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -Werror=vla")
|
||||
#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fno-math-errno -ffinite-math-only -funsafe-math-optimizations")
|
||||
endif()
|
||||
|
||||
message(STATUS "CMAKE_SYSTEM_PROCESSOR: ${CMAKE_SYSTEM_PROCESSOR}")
|
||||
|
||||
if (NOT UNAME_S)
|
||||
execute_process(COMMAND uname -s OUTPUT_VARIABLE UNAME_S)
|
||||
endif()
|
||||
if (NOT UNAME_P)
|
||||
execute_process(COMMAND uname -p OUTPUT_VARIABLE UNAME_P)
|
||||
endif()
|
||||
if (NOT UNAME_M)
|
||||
execute_process(COMMAND uname -m OUTPUT_VARIABLE UNAME_M)
|
||||
endif()
|
||||
#message(STATUS "UNAME_S: ${UNAME_S} UNAME_P: ${UNAME_P} UNAME_M: ${UNAME_M}")
|
||||
|
||||
# Mac OS + Arm can report x86_64
|
||||
# ref: https://github.com/ggerganov/whisper.cpp/issues/66#issuecomment-1282546789
|
||||
if (UNAME_S MATCHES "Darwin")
|
||||
if (NOT UNAME_P MATCHES "arm")
|
||||
execute_process(COMMAND sysctl -n hw.optional.arm64 OUTPUT_VARIABLE SYSCTL_M)
|
||||
if (SYSCTL_M MATCHES "1")
|
||||
#set(UNAME_P "arm")
|
||||
#set(UNAME_M "arm64")
|
||||
message(WARNING "Your arch is announced as x86_64, but it seems to actually be ARM64. Not fixing that can lead to bad performance. For more info see: https://github.com/ggerganov/whisper.cpp/issues/66\#issuecomment-#1282546789")
|
||||
endif()
|
||||
endif()
|
||||
endif()
|
||||
|
||||
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "arm" OR ${CMAKE_SYSTEM_PROCESSOR} MATCHES "aarch64")
|
||||
message(STATUS "ARM detected")
|
||||
#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mcpu=apple-m1")
|
||||
else()
|
||||
message(STATUS "x86 detected")
|
||||
#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mavx -mavx2 -mfma -mf16c")
|
||||
if (UNAME_S MATCHES "Darwin")
|
||||
execute_process(COMMAND sysctl machdep.cpu.features OUTPUT_VARIABLE AVX1_M)
|
||||
if (AVX1_M MATCHES "AVX1.0")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mavx")
|
||||
endif()
|
||||
execute_process(COMMAND sysctl machdep.cpu.leaf7_features OUTPUT_VARIABLE AVX2_M)
|
||||
if (AVX2_M MATCHES "AVX2")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mavx2")
|
||||
endif()
|
||||
if (AVX1_M MATCHES "FMA")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mfma")
|
||||
endif()
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mf16c")
|
||||
elseif (UNAME_S MATCHES "Linux")
|
||||
message(STATUS "Linux detected")
|
||||
execute_process(COMMAND grep "avx " /proc/cpuinfo OUTPUT_VARIABLE AVX1_M)
|
||||
if (AVX1_M MATCHES "avx")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mavx")
|
||||
endif()
|
||||
execute_process(COMMAND grep "avx2 " /proc/cpuinfo OUTPUT_VARIABLE AVX2_M)
|
||||
if (AVX2_M MATCHES "avx2")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mavx2")
|
||||
endif()
|
||||
execute_process(COMMAND grep "fma " /proc/cpuinfo OUTPUT_VARIABLE FMA_M)
|
||||
if (FMA_M MATCHES "fma")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mfma")
|
||||
endif()
|
||||
execute_process(COMMAND grep "f16c " /proc/cpuinfo OUTPUT_VARIABLE F16C_M)
|
||||
if (F16C_M MATCHES "f16c")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mf16c")
|
||||
endif()
|
||||
execute_process(COMMAND grep "sse3 " /proc/cpuinfo OUTPUT_VARIABLE SSE3_M)
|
||||
if (SSE3_M MATCHES "sse3")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -msse3")
|
||||
endif()
|
||||
elseif (UNAME_S MATCHES "Haiku")
|
||||
message(STATUS "Haiku detected")
|
||||
execute_process(COMMAND sysinfo -cpu COMMAND grep "AVX " OUTPUT_VARIABLE AVX1_M)
|
||||
if (AVX1_M MATCHES "avx")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mavx")
|
||||
endif()
|
||||
execute_process(COMMAND sysinfo -cpu COMMAND grep "AVX2 " OUTPUT_VARIABLE AVX2_M)
|
||||
if (AVX2_M MATCHES "avx2")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mavx2")
|
||||
endif()
|
||||
execute_process(COMMAND sysinfo -cpu COMMAND grep "FMA " OUTPUT_VARIABLE FMA_M)
|
||||
if (FMA_M MATCHES "fma")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mfma")
|
||||
endif()
|
||||
execute_process(COMMAND sysinfo -cpu COMMAND grep "F16C " OUTPUT_VARIABLE F16C_M)
|
||||
if (F16C_M MATCHES "f16c")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mf16c")
|
||||
endif()
|
||||
else()
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mfma -mf16c -mavx -mavx2")
|
||||
endif()
|
||||
endif()
|
||||
|
||||
|
||||
# ggml
|
||||
|
||||
set(TARGET ggml)
|
||||
|
||||
# on APPLE - include Accelerate framework
|
||||
if (APPLE AND NOT GGML_NO_ACCELERATE)
|
||||
find_library(ACCELERATE_FRAMEWORK Accelerate)
|
||||
if (ACCELERATE_FRAMEWORK)
|
||||
message(STATUS "Accelerate framework found")
|
||||
|
||||
set(GGML_EXTRA_LIBS ${GGML_EXTRA_LIBS} ${ACCELERATE_FRAMEWORK})
|
||||
set(GGML_EXTRA_FLAGS ${GGML_EXTRA_FLAGS} -DGGML_USE_ACCELERATE)
|
||||
else()
|
||||
message(WARNING "Accelerate framework not found")
|
||||
endif()
|
||||
endif()
|
||||
|
||||
if (GGML_OPENBLAS)
|
||||
set(OPENBLAS_INCLUDE_SEARCH_PATHS
|
||||
/usr/include
|
||||
/usr/include/openblas
|
||||
/usr/include/openblas-base
|
||||
/usr/local/include
|
||||
/usr/local/include/openblas
|
||||
/usr/local/include/openblas-base
|
||||
/opt/OpenBLAS/include
|
||||
$ENV{OpenBLAS_HOME}
|
||||
$ENV{OpenBLAS_HOME}/include
|
||||
)
|
||||
find_path(OPENBLAS_INC NAMES cblas.h PATHS ${OPENBLAS_INCLUDE_SEARCH_PATHS})
|
||||
find_library(OPENBLAS_LIB NAMES openblas libopenblas)
|
||||
if (OPENBLAS_LIB)
|
||||
message(STATUS "OpenBLAS found")
|
||||
|
||||
set(GGML_EXTRA_LIBS ${GGML_EXTRA_LIBS} ${OPENBLAS_LIB})
|
||||
set(GGML_EXTRA_INCS ${GGML_EXTRA_INCS} ${OPENBLAS_INC})
|
||||
set(GGML_EXTRA_FLAGS ${GGML_EXTRA_FLAGS} -DGGML_USE_OPENBLAS)
|
||||
else()
|
||||
message(WARNING "OpenBLAS not found")
|
||||
endif()
|
||||
endif()
|
||||
|
||||
if (GGML_CUBLAS)
|
||||
cmake_minimum_required(VERSION 3.17)
|
||||
|
||||
find_package(CUDAToolkit)
|
||||
if (CUDAToolkit_FOUND)
|
||||
message(STATUS "cuBLAS found")
|
||||
|
||||
enable_language(CUDA)
|
||||
|
||||
set(GGML_CUDA_SOURCES ggml-cuda.cu ggml-cuda.h)
|
||||
|
||||
add_compile_definitions(GGML_USE_CUBLAS)
|
||||
|
||||
if (GGML_STATIC)
|
||||
set(GGML_EXTRA_LIBS ${GGML_EXTRA_LIBS} CUDA::cudart_static CUDA::cublas_static CUDA::cublasLt_static)
|
||||
else()
|
||||
set(GGML_EXTRA_LIBS ${GGML_EXTRA_LIBS} CUDA::cudart CUDA::cublas CUDA::cublasLt)
|
||||
endif()
|
||||
|
||||
else()
|
||||
message(WARNING "cuBLAS not found")
|
||||
endif()
|
||||
endif()
|
||||
|
||||
|
||||
if (GGML_PERF)
|
||||
set(GGML_EXTRA_FLAGS ${GGML_EXTRA_FLAGS} -DGGML_PERF)
|
||||
endif()
|
||||
|
||||
add_library(${TARGET}
|
||||
ggml.c
|
||||
../include/ggml/ggml.h
|
||||
${GGML_CUDA_SOURCES})
|
||||
|
||||
target_include_directories(${TARGET} PUBLIC
|
||||
.
|
||||
../include
|
||||
../include/ggml
|
||||
${GGML_EXTRA_INCS}
|
||||
)
|
||||
|
||||
if (MSVC)
|
||||
target_link_libraries(${TARGET} PUBLIC ${GGML_EXTRA_LIBS} ${CMAKE_THREAD_LIBS_INIT})
|
||||
else()
|
||||
target_link_libraries(${TARGET} PUBLIC m ${GGML_EXTRA_LIBS} ${CMAKE_THREAD_LIBS_INIT})
|
||||
endif()
|
||||
|
||||
if (BUILD_SHARED_LIBS)
|
||||
target_link_libraries(${TARGET} PUBLIC
|
||||
${CMAKE_DL_LIBS}
|
||||
)
|
||||
|
||||
target_compile_definitions(${TARGET} PUBLIC
|
||||
GGML_SHARED
|
||||
)
|
||||
|
||||
target_compile_definitions(${TARGET} PRIVATE
|
||||
GGML_BUILD
|
||||
)
|
||||
endif()
|
||||
|
||||
target_compile_definitions(${TARGET} PUBLIC
|
||||
${GGML_EXTRA_FLAGS}
|
||||
)
|
||||
|
||||
if (MINGW)
|
||||
target_link_libraries(${TARGET} PUBLIC
|
||||
stdc++
|
||||
)
|
||||
endif()
|
||||
|
||||
if (GGML_CUDA_SOURCES)
|
||||
message(STATUS "GGML CUDA sources found, configuring CUDA architecture")
|
||||
set_property(TARGET ggml PROPERTY CUDA_ARCHITECTURES OFF)
|
||||
set_property(TARGET ggml PROPERTY CUDA_SELECT_NVCC_ARCH_FLAGS "Auto")
|
||||
target_link_libraries(ggml PUBLIC stdc++)
|
||||
endif()
|
||||
|
||||
install(TARGETS ${TARGET}
|
||||
LIBRARY DESTINATION lib
|
||||
ARCHIVE DESTINATION lib/static
|
||||
)
|
||||
|
|
@ -0,0 +1,925 @@
|
|||
#include <cstddef>
|
||||
#include <cstdint>
|
||||
#include <stdint.h>
|
||||
#include <stdio.h>
|
||||
#include <atomic>
|
||||
|
||||
#include <cuda_runtime.h>
|
||||
#include <cublas_v2.h>
|
||||
#include <cuda_fp16.h>
|
||||
|
||||
#include "ggml-cuda.h"
|
||||
#include "ggml.h"
|
||||
|
||||
static_assert(sizeof(half) == sizeof(ggml_fp16_t), "wrong fp16 size");
|
||||
|
||||
#define CUDA_CHECK(err) \
|
||||
do { \
|
||||
cudaError_t err_ = (err); \
|
||||
if (err_ != cudaSuccess) { \
|
||||
fprintf(stderr, "CUDA error %d at %s:%d: %s\n", err_, __FILE__, __LINE__, \
|
||||
cudaGetErrorString(err_)); \
|
||||
exit(1); \
|
||||
} \
|
||||
} while (0)
|
||||
|
||||
#define CUBLAS_CHECK(err) \
|
||||
do { \
|
||||
cublasStatus_t err_ = (err); \
|
||||
if (err_ != CUBLAS_STATUS_SUCCESS) { \
|
||||
fprintf(stderr, "cuBLAS error %d at %s:%d\n", err_, __FILE__, __LINE__); \
|
||||
exit(1); \
|
||||
} \
|
||||
} while (0)
|
||||
|
||||
typedef void (*dequantize_kernel_t)(const void * vx, const int ib, const int iqs, float & v0, float & v1);
|
||||
typedef void (*to_fp32_cuda_t)(const void * x, float * y, int k, cudaStream_t stream);
|
||||
typedef void (*dequantize_mul_mat_vec_cuda_t)(const void * vx, const float * y, float * dst, const int ncols, const int nrows, cudaStream_t stream);
|
||||
|
||||
// QK = number of values after dequantization
|
||||
// QR = QK / number of values before dequantization
|
||||
|
||||
#define QK4_0 32
|
||||
#define QR4_0 2
|
||||
typedef struct {
|
||||
half d; // delta
|
||||
uint8_t qs[QK4_0 / 2]; // nibbles / quants
|
||||
} block_q4_0;
|
||||
static_assert(sizeof(block_q4_0) == sizeof(ggml_fp16_t) + QK4_0 / 2, "wrong q4_0 block size/padding");
|
||||
|
||||
#define QK4_1 32
|
||||
#define QR4_1 2
|
||||
typedef struct {
|
||||
half d; // delta
|
||||
half m; // min
|
||||
uint8_t qs[QK4_1 / 2]; // nibbles / quants
|
||||
} block_q4_1;
|
||||
static_assert(sizeof(block_q4_1) == sizeof(ggml_fp16_t) * 2 + QK4_1 / 2, "wrong q4_1 block size/padding");
|
||||
|
||||
#define QK5_0 32
|
||||
#define QR5_0 2
|
||||
typedef struct {
|
||||
half d; // delta
|
||||
uint8_t qh[4]; // 5-th bit of quants
|
||||
uint8_t qs[QK5_0 / 2]; // nibbles / quants
|
||||
} block_q5_0;
|
||||
static_assert(sizeof(block_q5_0) == sizeof(ggml_fp16_t) + sizeof(uint32_t) + QK5_0 / 2, "wrong q5_0 block size/padding");
|
||||
|
||||
#define QK5_1 32
|
||||
#define QR5_1 2
|
||||
typedef struct {
|
||||
half d; // delta
|
||||
half m; // min
|
||||
uint8_t qh[4]; // 5-th bit of quants
|
||||
uint8_t qs[QK5_1 / 2]; // nibbles / quants
|
||||
} block_q5_1;
|
||||
static_assert(sizeof(block_q5_1) == 2 * sizeof(ggml_fp16_t) + sizeof(uint32_t) + QK5_1 / 2, "wrong q5_1 block size/padding");
|
||||
|
||||
#define QK8_0 32
|
||||
#define QR8_0 1
|
||||
typedef struct {
|
||||
half d; // delta
|
||||
int8_t qs[QK8_0]; // quants
|
||||
} block_q8_0;
|
||||
static_assert(sizeof(block_q8_0) == sizeof(ggml_fp16_t) + QK8_0, "wrong q8_0 block size/padding");
|
||||
|
||||
#define CUDA_MUL_BLOCK_SIZE 256
|
||||
#define CUDA_DEQUANTIZE_BLOCK_SIZE 256
|
||||
#define CUDA_DMMV_BLOCK_SIZE 32 // dmmv = dequantize_mul_mat_vec
|
||||
|
||||
static __global__ void mul_f32(const float * x, const float * y, float * dst, const int kx, const int ky) {
|
||||
const int i = blockDim.x*blockIdx.x + threadIdx.x;
|
||||
|
||||
if (i >= kx) {
|
||||
return;
|
||||
}
|
||||
dst[i] = x[i] * y[i%ky];
|
||||
}
|
||||
|
||||
static __device__ void dequantize_q4_0(const void * vx, const int ib, const int iqs, float & v0, float & v1){
|
||||
const block_q4_0 * x = (const block_q4_0 *) vx;
|
||||
|
||||
const float d = x[ib].d;
|
||||
|
||||
const uint8_t vui = x[ib].qs[iqs];
|
||||
|
||||
const int8_t vi0 = vui & 0xF;
|
||||
const int8_t vi1 = vui >> 4;
|
||||
|
||||
v0 = (vi0 - 8)*d;
|
||||
v1 = (vi1 - 8)*d;
|
||||
}
|
||||
|
||||
static __device__ void dequantize_q4_1(const void * vx, const int ib, const int iqs, float & v0, float & v1){
|
||||
const block_q4_1 * x = (const block_q4_1 *) vx;
|
||||
|
||||
const float d = x[ib].d;
|
||||
const float m = x[ib].m;
|
||||
|
||||
const uint8_t vui = x[ib].qs[iqs];
|
||||
|
||||
const int8_t vi0 = vui & 0xF;
|
||||
const int8_t vi1 = vui >> 4;
|
||||
|
||||
v0 = vi0*d + m;
|
||||
v1 = vi1*d + m;
|
||||
}
|
||||
|
||||
static __device__ void dequantize_q5_0(const void * vx, const int ib, const int iqs, float & v0, float & v1){
|
||||
const block_q5_0 * x = (const block_q5_0 *) vx;
|
||||
|
||||
const float d = x[ib].d;
|
||||
|
||||
uint32_t qh;
|
||||
memcpy(&qh, x[ib].qh, sizeof(qh));
|
||||
|
||||
const uint8_t xh_0 = ((qh >> (iqs + 0)) << 4) & 0x10;
|
||||
const uint8_t xh_1 = ((qh >> (iqs + 12)) ) & 0x10;
|
||||
|
||||
const int32_t x0 = ((x[ib].qs[iqs] & 0xf) | xh_0) - 16;
|
||||
const int32_t x1 = ((x[ib].qs[iqs] >> 4) | xh_1) - 16;
|
||||
|
||||
v0 = x0*d;
|
||||
v1 = x1*d;
|
||||
}
|
||||
|
||||
static __device__ void dequantize_q5_1(const void * vx, const int ib, const int iqs, float & v0, float & v1){
|
||||
const block_q5_1 * x = (const block_q5_1 *) vx;
|
||||
|
||||
const float d = x[ib].d;
|
||||
const float m = x[ib].m;
|
||||
|
||||
uint32_t qh;
|
||||
memcpy(&qh, x[ib].qh, sizeof(qh));
|
||||
|
||||
const uint8_t xh_0 = ((qh >> (iqs + 0)) << 4) & 0x10;
|
||||
const uint8_t xh_1 = ((qh >> (iqs + 12)) ) & 0x10;
|
||||
|
||||
const int32_t x0 = ((x[ib].qs[iqs] & 0xf) | xh_0);
|
||||
const int32_t x1 = ((x[ib].qs[iqs] >> 4) | xh_1);
|
||||
|
||||
v0 = x0*d + m;
|
||||
v1 = x1*d + m;
|
||||
}
|
||||
|
||||
static __device__ void dequantize_q8_0(const void * vx, const int ib, const int iqs, float & v0, float & v1){
|
||||
const block_q8_0 * x = (const block_q8_0 *) vx;
|
||||
|
||||
const float d = x[ib].d;
|
||||
|
||||
const int8_t vi0 = x[ib].qs[iqs + 0];
|
||||
const int8_t vi1 = x[ib].qs[iqs + 1];
|
||||
|
||||
v0 = vi0*d;
|
||||
v1 = vi1*d;
|
||||
}
|
||||
|
||||
static __device__ void convert_f16(const void * vx, const int ib, const int iqs, float & v0, float & v1){
|
||||
const half * x = (const half *) vx;
|
||||
|
||||
v0 = __half2float(x[ib + 0]);
|
||||
v1 = __half2float(x[ib + 1]);
|
||||
}
|
||||
|
||||
template <int qk, int qr, dequantize_kernel_t dequantize_kernel>
|
||||
static __global__ void dequantize_block(const void * vx, float * y, const int k) {
|
||||
const int i = blockDim.x*blockIdx.x + 2*threadIdx.x;
|
||||
|
||||
if (i >= k) {
|
||||
return;
|
||||
}
|
||||
|
||||
const int ib = i/qk; // block index
|
||||
const int iqs = (i%qk)/qr; // quant index
|
||||
const int iybs = i - i%qk; // y block start index
|
||||
const int y_offset = qr == 1 ? 1 : qk/2;
|
||||
|
||||
// dequantize
|
||||
float & v0 = y[iybs + iqs + 0];
|
||||
float & v1 = y[iybs + iqs + y_offset];
|
||||
dequantize_kernel(vx, ib, iqs, v0, v1);
|
||||
}
|
||||
|
||||
template <int block_size, int qk, int qr, dequantize_kernel_t dequantize_kernel>
|
||||
static __global__ void dequantize_mul_mat_vec(const void * vx, const float * y, float * dst, const int ncols) {
|
||||
const int row = blockIdx.x;
|
||||
const int tid = threadIdx.x;
|
||||
|
||||
const int y_offset = qr == 1 ? 1 : qk/2;
|
||||
|
||||
__shared__ float tmp[block_size]; // separate sum for each thread
|
||||
tmp[tid] = 0;
|
||||
|
||||
for (int i = 0; i < ncols/block_size; i += 2) {
|
||||
const int col = i*block_size + 2*tid;
|
||||
const int ib = (row*ncols + col)/qk; // block index
|
||||
const int iqs = (col%qk)/qr; // quant index
|
||||
const int iybs = col - col%qk; // y block start index
|
||||
|
||||
// dequantize
|
||||
float v0, v1;
|
||||
dequantize_kernel(vx, ib, iqs, v0, v1);
|
||||
|
||||
// matrix multiplication
|
||||
tmp[tid] += v0 * y[iybs + iqs + 0];
|
||||
tmp[tid] += v1 * y[iybs + iqs + y_offset];
|
||||
}
|
||||
|
||||
// sum up partial sums and write back result
|
||||
__syncthreads();
|
||||
for (int s=block_size/2; s>0; s>>=1) {
|
||||
if (tid < s) {
|
||||
tmp[tid] += tmp[tid + s];
|
||||
}
|
||||
__syncthreads();
|
||||
}
|
||||
if (tid == 0) {
|
||||
dst[row] = tmp[0];
|
||||
}
|
||||
}
|
||||
|
||||
static void mul_f32_cuda(const float * x, const float * y, float * dst, const int kx, const int ky, cudaStream_t stream) {
|
||||
const int num_blocks = (kx + CUDA_MUL_BLOCK_SIZE - 1) / CUDA_MUL_BLOCK_SIZE;
|
||||
mul_f32<<<num_blocks, CUDA_MUL_BLOCK_SIZE, 0, stream>>>(x, y, dst, kx, ky);
|
||||
}
|
||||
|
||||
static void dequantize_row_q4_0_cuda(const void * vx, float * y, const int k, cudaStream_t stream) {
|
||||
const int num_blocks = (k + CUDA_DEQUANTIZE_BLOCK_SIZE - 1) / CUDA_DEQUANTIZE_BLOCK_SIZE;
|
||||
dequantize_block<QK4_0, QR4_0, dequantize_q4_0><<<num_blocks, CUDA_DEQUANTIZE_BLOCK_SIZE, 0, stream>>>(vx, y, k);
|
||||
}
|
||||
|
||||
static void dequantize_row_q4_1_cuda(const void * vx, float * y, const int k, cudaStream_t stream) {
|
||||
const int num_blocks = (k + CUDA_DEQUANTIZE_BLOCK_SIZE - 1) / CUDA_DEQUANTIZE_BLOCK_SIZE;
|
||||
dequantize_block<QK4_1, QR4_1, dequantize_q4_1><<<num_blocks, CUDA_DEQUANTIZE_BLOCK_SIZE, 0, stream>>>(vx, y, k);
|
||||
}
|
||||
|
||||
static void dequantize_row_q5_0_cuda(const void * vx, float * y, const int k, cudaStream_t stream) {
|
||||
const int num_blocks = (k + CUDA_DEQUANTIZE_BLOCK_SIZE - 1) / CUDA_DEQUANTIZE_BLOCK_SIZE;
|
||||
dequantize_block<QK5_0, QR5_0, dequantize_q5_0><<<num_blocks, CUDA_DEQUANTIZE_BLOCK_SIZE, 0, stream>>>(vx, y, k);
|
||||
}
|
||||
|
||||
static void dequantize_row_q5_1_cuda(const void * vx, float * y, const int k, cudaStream_t stream) {
|
||||
const int num_blocks = (k + CUDA_DEQUANTIZE_BLOCK_SIZE - 1) / CUDA_DEQUANTIZE_BLOCK_SIZE;
|
||||
dequantize_block<QK5_1, QR5_1, dequantize_q5_1><<<num_blocks, CUDA_DEQUANTIZE_BLOCK_SIZE, 0, stream>>>(vx, y, k);
|
||||
}
|
||||
|
||||
static void dequantize_row_q8_0_cuda(const void * vx, float * y, const int k, cudaStream_t stream) {
|
||||
const int num_blocks = (k + CUDA_DEQUANTIZE_BLOCK_SIZE - 1) / CUDA_DEQUANTIZE_BLOCK_SIZE;
|
||||
dequantize_block<QK8_0, QR8_0, dequantize_q8_0><<<num_blocks, CUDA_DEQUANTIZE_BLOCK_SIZE, 0, stream>>>(vx, y, k);
|
||||
}
|
||||
|
||||
static void dequantize_mul_mat_vec_q4_0_cuda(const void * vx, const float * y, float * dst, const int ncols, const int nrows, cudaStream_t stream) {
|
||||
GGML_ASSERT(ncols % CUDA_DMMV_BLOCK_SIZE == 0);
|
||||
dequantize_mul_mat_vec<CUDA_DMMV_BLOCK_SIZE, QK4_0, QR4_0, dequantize_q4_0>
|
||||
<<<nrows, CUDA_DMMV_BLOCK_SIZE, 0, stream>>>(vx, y, dst, ncols);
|
||||
}
|
||||
|
||||
static void dequantize_mul_mat_vec_q4_1_cuda(const void * vx, const float * y, float * dst, const int ncols, const int nrows, cudaStream_t stream) {
|
||||
GGML_ASSERT(ncols % CUDA_DMMV_BLOCK_SIZE == 0);
|
||||
dequantize_mul_mat_vec<CUDA_DMMV_BLOCK_SIZE, QK4_1, QR4_1, dequantize_q4_1>
|
||||
<<<nrows, CUDA_DMMV_BLOCK_SIZE, 0, stream>>>(vx, y, dst, ncols);
|
||||
}
|
||||
|
||||
static void dequantize_mul_mat_vec_q5_0_cuda(const void * vx, const float * y, float * dst, const int ncols, const int nrows, cudaStream_t stream) {
|
||||
GGML_ASSERT(ncols % CUDA_DMMV_BLOCK_SIZE == 0);
|
||||
dequantize_mul_mat_vec<CUDA_DMMV_BLOCK_SIZE, QK5_0, QR5_0, dequantize_q5_0>
|
||||
<<<nrows, CUDA_DMMV_BLOCK_SIZE, 0, stream>>>(vx, y, dst, ncols);
|
||||
}
|
||||
|
||||
static void dequantize_mul_mat_vec_q5_1_cuda(const void * vx, const float * y, float * dst, const int ncols, const int nrows, cudaStream_t stream) {
|
||||
GGML_ASSERT(ncols % CUDA_DMMV_BLOCK_SIZE == 0);
|
||||
dequantize_mul_mat_vec<CUDA_DMMV_BLOCK_SIZE, QK5_1, QR5_1, dequantize_q5_1>
|
||||
<<<nrows, CUDA_DMMV_BLOCK_SIZE, 0, stream>>>(vx, y, dst, ncols);
|
||||
}
|
||||
|
||||
static void dequantize_mul_mat_vec_q8_0_cuda(const void * vx, const float * y, float * dst, const int ncols, const int nrows, cudaStream_t stream) {
|
||||
GGML_ASSERT(ncols % CUDA_DMMV_BLOCK_SIZE == 0);
|
||||
dequantize_mul_mat_vec<CUDA_DMMV_BLOCK_SIZE, QK8_0, QR8_0, dequantize_q8_0>
|
||||
<<<nrows, CUDA_DMMV_BLOCK_SIZE, 0, stream>>>(vx, y, dst, ncols);
|
||||
}
|
||||
|
||||
static void convert_fp16_to_fp32_cuda(const void * vx, float * y, const int k, cudaStream_t stream) {
|
||||
const int num_blocks = (k + CUDA_DEQUANTIZE_BLOCK_SIZE - 1) / CUDA_DEQUANTIZE_BLOCK_SIZE;
|
||||
dequantize_block<32, 1, convert_f16><<<num_blocks, CUDA_DEQUANTIZE_BLOCK_SIZE, 0, stream>>>(vx, y, k);
|
||||
}
|
||||
|
||||
static void convert_mul_mat_vec_f16_cuda(const void * vx, const float * y, float * dst, const int ncols, const int nrows, cudaStream_t stream) {
|
||||
GGML_ASSERT(ncols % CUDA_DMMV_BLOCK_SIZE == 0);
|
||||
dequantize_mul_mat_vec<CUDA_DMMV_BLOCK_SIZE, 32, 1, convert_f16>
|
||||
<<<nrows, CUDA_DMMV_BLOCK_SIZE, 0, stream>>>(vx, y, dst, ncols);
|
||||
}
|
||||
|
||||
static to_fp32_cuda_t ggml_get_to_fp32_cuda(ggml_type type) {
|
||||
switch (type) {
|
||||
case GGML_TYPE_Q4_0:
|
||||
return dequantize_row_q4_0_cuda;
|
||||
case GGML_TYPE_Q4_1:
|
||||
return dequantize_row_q4_1_cuda;
|
||||
case GGML_TYPE_Q5_0:
|
||||
return dequantize_row_q5_0_cuda;
|
||||
case GGML_TYPE_Q5_1:
|
||||
return dequantize_row_q5_1_cuda;
|
||||
case GGML_TYPE_Q8_0:
|
||||
return dequantize_row_q8_0_cuda;
|
||||
case GGML_TYPE_F16:
|
||||
return convert_fp16_to_fp32_cuda;
|
||||
default:
|
||||
return nullptr;
|
||||
}
|
||||
}
|
||||
|
||||
static dequantize_mul_mat_vec_cuda_t ggml_get_dequantize_mul_mat_vec_cuda(ggml_type type) {
|
||||
switch (type) {
|
||||
case GGML_TYPE_Q4_0:
|
||||
return dequantize_mul_mat_vec_q4_0_cuda;
|
||||
case GGML_TYPE_Q4_1:
|
||||
return dequantize_mul_mat_vec_q4_1_cuda;
|
||||
case GGML_TYPE_Q5_0:
|
||||
return dequantize_mul_mat_vec_q5_0_cuda;
|
||||
case GGML_TYPE_Q5_1:
|
||||
return dequantize_mul_mat_vec_q5_1_cuda;
|
||||
case GGML_TYPE_Q8_0:
|
||||
return dequantize_mul_mat_vec_q8_0_cuda;
|
||||
case GGML_TYPE_F16:
|
||||
return convert_mul_mat_vec_f16_cuda;
|
||||
default:
|
||||
return nullptr;
|
||||
}
|
||||
}
|
||||
|
||||
// buffer pool for cuda
|
||||
#define MAX_CUDA_BUFFERS 256
|
||||
|
||||
struct scoped_spin_lock {
|
||||
std::atomic_flag& lock;
|
||||
scoped_spin_lock(std::atomic_flag& lock) : lock(lock) {
|
||||
while (lock.test_and_set(std::memory_order_acquire)) {
|
||||
; // spin
|
||||
}
|
||||
}
|
||||
~scoped_spin_lock() {
|
||||
lock.clear(std::memory_order_release);
|
||||
}
|
||||
scoped_spin_lock(const scoped_spin_lock&) = delete;
|
||||
scoped_spin_lock& operator=(const scoped_spin_lock&) = delete;
|
||||
};
|
||||
|
||||
struct cuda_buffer {
|
||||
void * ptr = nullptr;
|
||||
size_t size = 0;
|
||||
};
|
||||
|
||||
static cuda_buffer g_cuda_buffer_pool[MAX_CUDA_BUFFERS];
|
||||
static std::atomic_flag g_cuda_pool_lock = ATOMIC_FLAG_INIT;
|
||||
|
||||
static void * ggml_cuda_pool_malloc(size_t size, size_t * actual_size) {
|
||||
scoped_spin_lock lock(g_cuda_pool_lock);
|
||||
|
||||
for (int i = 0; i < MAX_CUDA_BUFFERS; ++i) {
|
||||
cuda_buffer& b = g_cuda_buffer_pool[i];
|
||||
if (b.size >= size && b.ptr != nullptr) {
|
||||
void * ptr = b.ptr;
|
||||
*actual_size = b.size;
|
||||
b.ptr = nullptr;
|
||||
b.size = 0;
|
||||
return ptr;
|
||||
}
|
||||
}
|
||||
void * ptr;
|
||||
CUDA_CHECK(cudaMalloc((void **) &ptr, size));
|
||||
*actual_size = size;
|
||||
return ptr;
|
||||
}
|
||||
|
||||
static void ggml_cuda_pool_free(void * ptr, size_t size) {
|
||||
scoped_spin_lock lock(g_cuda_pool_lock);
|
||||
|
||||
for (int i = 0; i < MAX_CUDA_BUFFERS; ++i) {
|
||||
cuda_buffer& b = g_cuda_buffer_pool[i];
|
||||
if (b.ptr == nullptr) {
|
||||
b.ptr = ptr;
|
||||
b.size = size;
|
||||
return;
|
||||
}
|
||||
}
|
||||
fprintf(stderr, "WARNING: cuda buffer pool full, increase MAX_CUDA_BUFFERS\n");
|
||||
CUDA_CHECK(cudaFree(ptr));
|
||||
}
|
||||
|
||||
#define GGML_CUDA_MAX_STREAMS 8 // Set this to 1 for reproducible matrix multiplication.
|
||||
#define GGML_CUDA_MAX_EVENTS 64
|
||||
static cublasHandle_t g_cublasH = nullptr;
|
||||
static cudaStream_t g_cudaStreams[GGML_CUDA_MAX_STREAMS] = { nullptr };
|
||||
static cudaStream_t g_cudaStreams2[GGML_CUDA_MAX_STREAMS] = { nullptr };
|
||||
static cudaEvent_t g_cudaEvents[GGML_CUDA_MAX_EVENTS] = { nullptr };
|
||||
|
||||
void ggml_init_cublas() {
|
||||
if (g_cublasH == nullptr) {
|
||||
// create streams
|
||||
for (int i = 0; i < GGML_CUDA_MAX_STREAMS; ++i) {
|
||||
CUDA_CHECK(cudaStreamCreateWithFlags(&g_cudaStreams[i], cudaStreamNonBlocking));
|
||||
CUDA_CHECK(cudaStreamCreateWithFlags(&g_cudaStreams2[i], cudaStreamNonBlocking));
|
||||
}
|
||||
// create events
|
||||
for (int i = 0; i < GGML_CUDA_MAX_EVENTS; ++i) {
|
||||
CUDA_CHECK(cudaEventCreateWithFlags(&g_cudaEvents[i], cudaEventDisableTiming));
|
||||
}
|
||||
|
||||
// create cublas handle
|
||||
CUBLAS_CHECK(cublasCreate(&g_cublasH));
|
||||
CUBLAS_CHECK(cublasSetMathMode(g_cublasH, CUBLAS_TF32_TENSOR_OP_MATH));
|
||||
|
||||
// configure logging to stdout
|
||||
// CUBLAS_CHECK(cublasLoggerConfigure(1, 1, 0, nullptr));
|
||||
}
|
||||
}
|
||||
|
||||
void * ggml_cuda_host_malloc(size_t size) {
|
||||
if (getenv("GGML_CUDA_NO_PINNED") != nullptr) {
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
void * ptr = nullptr;
|
||||
cudaError_t err = cudaMallocHost((void **) &ptr, size);
|
||||
if (err != cudaSuccess) {
|
||||
fprintf(stderr, "WARNING: failed to allocate %.2f MB of pinned memory: %s\n",
|
||||
size/1024.0/1024.0, cudaGetErrorString(err));
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
return ptr;
|
||||
}
|
||||
|
||||
void ggml_cuda_host_free(void * ptr) {
|
||||
CUDA_CHECK(cudaFreeHost(ptr));
|
||||
}
|
||||
|
||||
static cudaError_t ggml_cuda_h2d_tensor_2d(void * dst, const struct ggml_tensor * src, uint64_t i3, uint64_t i2, cudaStream_t stream) {
|
||||
const uint64_t ne0 = src->ne[0];
|
||||
const uint64_t ne1 = src->ne[1];
|
||||
const uint64_t nb0 = src->nb[0];
|
||||
const uint64_t nb1 = src->nb[1];
|
||||
const uint64_t nb2 = src->nb[2];
|
||||
const uint64_t nb3 = src->nb[3];
|
||||
const enum ggml_type type = src->type;
|
||||
const size_t ts = ggml_type_size(type);
|
||||
const size_t bs = ggml_blck_size(type);
|
||||
|
||||
const void * x = (const void *) ((const char *) src->data + i2*nb2 + i3*nb3);
|
||||
if (nb0 == ts && nb1 == ts*ne0/bs) {
|
||||
return cudaMemcpyAsync(dst, x, ne1*nb1, cudaMemcpyHostToDevice, stream);
|
||||
} else if (nb0 == ts) {
|
||||
return cudaMemcpy2DAsync(dst, ts*ne0/bs, x, nb1, ts*ne0/bs, ne1, cudaMemcpyHostToDevice, stream);
|
||||
} else {
|
||||
for (uint64_t i1 = 0; i1 < ne1; i1++) {
|
||||
const void * rx = (const void *) ((const char *) x + i1*nb1);
|
||||
void * rd = (void *) ((char *) dst + i1*ts*ne0/bs);
|
||||
// pretend the row is a matrix with cols=1
|
||||
cudaError_t r = cudaMemcpy2DAsync(rd, ts/bs, rx, nb0, ts/bs, ne0, cudaMemcpyHostToDevice, stream);
|
||||
if (r != cudaSuccess) return r;
|
||||
}
|
||||
return cudaSuccess;
|
||||
}
|
||||
}
|
||||
|
||||
static void ggml_cuda_mul_f32(const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
||||
GGML_ASSERT(src1->backend == GGML_BACKEND_CUDA);
|
||||
const int64_t ne00 = src0->ne[0];
|
||||
const int64_t ne01 = src0->ne[1];
|
||||
const int64_t ne02 = src0->ne[2];
|
||||
const int64_t ne03 = src0->ne[2];
|
||||
const int64_t ne0 = ne00 * ne01 * ne02 * ne03;
|
||||
const int64_t ne10 = src1->ne[0];
|
||||
const int64_t ne11 = src1->ne[1];
|
||||
const int64_t ne12 = src1->ne[2];
|
||||
const int64_t ne13 = src1->ne[3];
|
||||
const int nb2 = dst->nb[2];
|
||||
const int nb3 = dst->nb[3];
|
||||
size_t x_size, d_size;
|
||||
|
||||
float * d_X = (float *) ggml_cuda_pool_malloc(ne0 * sizeof(float), &x_size); // src0
|
||||
float * d_Y = (float *) src1->data; // src1 is already on device, broadcasted.
|
||||
float * d_D = (float *) ggml_cuda_pool_malloc(ne0 * sizeof(float), &d_size); // dst
|
||||
|
||||
for (int64_t i03 = 0; i03 < ne03; i03++) {
|
||||
for (int64_t i02 = 0; i02 < ne02; i02++) {
|
||||
const int i0 = i03*ne02 + i02;
|
||||
float * c_X2 = d_X + i0*ne01*ne00;
|
||||
float * c_D2 = d_D + i0*ne01*ne00;
|
||||
|
||||
cudaStream_t cudaStream = g_cudaStreams[i0 % GGML_CUDA_MAX_STREAMS];
|
||||
cudaStream_t cudaStream2 = g_cudaStreams2[i0 % GGML_CUDA_MAX_STREAMS];
|
||||
cudaEvent_t cudaEvent = g_cudaEvents[i0 % GGML_CUDA_MAX_EVENTS];
|
||||
|
||||
// copy src0 to device
|
||||
CUDA_CHECK(ggml_cuda_h2d_tensor_2d(c_X2, src0, i03, i02, cudaStream2));
|
||||
CUDA_CHECK(cudaEventRecord(cudaEvent, cudaStream2));
|
||||
|
||||
// wait for data
|
||||
CUDA_CHECK(cudaStreamWaitEvent(cudaStream, cudaEvent, 0));
|
||||
|
||||
for (int64_t i01 = 0; i01 < ne01; i01++) {
|
||||
const int64_t i13 = i03%ne13;
|
||||
const int64_t i12 = i02%ne12;
|
||||
const int64_t i11 = i01%ne11;
|
||||
const int i1 = i13*ne12*ne11 + i12*ne11 + i11;
|
||||
|
||||
float * c_X1 = c_X2 + i01*ne00;
|
||||
float * c_Y = d_Y + i1*ne10;
|
||||
float * c_D1 = c_D2 + i01*ne00;
|
||||
|
||||
// compute
|
||||
mul_f32_cuda(c_X1, c_Y, c_D1, ne00, ne10, cudaStream);
|
||||
CUDA_CHECK(cudaGetLastError());
|
||||
}
|
||||
|
||||
// copy dst to host
|
||||
float * d = (float *) ((char *) dst->data + i02*nb2 + i03*nb3);
|
||||
CUDA_CHECK(cudaMemcpyAsync(d, c_D2, sizeof(float)*ne00*ne01, cudaMemcpyDeviceToHost, cudaStream));
|
||||
}
|
||||
}
|
||||
CUDA_CHECK(cudaDeviceSynchronize());
|
||||
ggml_cuda_pool_free(d_X, x_size);
|
||||
ggml_cuda_pool_free(d_D, d_size);
|
||||
}
|
||||
|
||||
static void ggml_cuda_mul_mat_f32(const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
||||
const int64_t ne00 = src0->ne[0];
|
||||
const int64_t ne01 = src0->ne[1];
|
||||
const int64_t ne02 = src0->ne[2];
|
||||
const int64_t ne03 = src0->ne[3];
|
||||
|
||||
const int64_t ne10 = src1->ne[0];
|
||||
const int64_t ne11 = src1->ne[1];
|
||||
|
||||
const int nb2 = dst->nb[2];
|
||||
const int nb3 = dst->nb[3];
|
||||
|
||||
const float alpha = 1.0f;
|
||||
const float beta = 0.0f;
|
||||
const int x_ne = ne01 * ne00;
|
||||
const int y_ne = ne11 * ne10;
|
||||
const int d_ne = ne11 * ne01;
|
||||
const int n_mm = ne03 * ne02;
|
||||
|
||||
size_t x_size, y_size, d_size;
|
||||
float * d_X = (float *) ggml_cuda_pool_malloc(n_mm * sizeof(float) * x_ne, &x_size);
|
||||
float * d_Y = (float *) ggml_cuda_pool_malloc(n_mm * sizeof(float) * y_ne, &y_size);
|
||||
float * d_D = (float *) ggml_cuda_pool_malloc(n_mm * sizeof(float) * d_ne, &d_size);
|
||||
|
||||
for (int64_t i03 = 0; i03 < ne03; i03++) {
|
||||
for (int64_t i02 = 0; i02 < ne02; i02++) {
|
||||
int i = i03*ne02 + i02;
|
||||
cudaStream_t cudaStream = g_cudaStreams[i % GGML_CUDA_MAX_STREAMS];
|
||||
|
||||
float * c_X = d_X + i * x_ne;
|
||||
float * c_Y = d_Y + i * y_ne;
|
||||
float * c_D = d_D + i * d_ne;
|
||||
|
||||
// copy data to device
|
||||
CUDA_CHECK(ggml_cuda_h2d_tensor_2d(c_X, src0, i03, i02, cudaStream));
|
||||
CUDA_CHECK(ggml_cuda_h2d_tensor_2d(c_Y, src1, i03, i02, cudaStream));
|
||||
|
||||
// compute
|
||||
CUBLAS_CHECK(cublasSetStream(g_cublasH, cudaStream));
|
||||
CUBLAS_CHECK(
|
||||
cublasSgemm(g_cublasH, CUBLAS_OP_T, CUBLAS_OP_N,
|
||||
ne01, ne11, ne10,
|
||||
&alpha, c_X, ne00,
|
||||
c_Y, ne10,
|
||||
&beta, c_D, ne01));
|
||||
|
||||
// copy dst to host
|
||||
float * d = (float *) ((char *) dst->data + i02*nb2 + i03*nb3);
|
||||
CUDA_CHECK(cudaMemcpyAsync(d, c_D, sizeof(float) * d_ne, cudaMemcpyDeviceToHost, cudaStream));
|
||||
}
|
||||
}
|
||||
|
||||
CUDA_CHECK(cudaDeviceSynchronize());
|
||||
ggml_cuda_pool_free(d_X, x_size);
|
||||
ggml_cuda_pool_free(d_Y, y_size);
|
||||
ggml_cuda_pool_free(d_D, d_size);
|
||||
}
|
||||
|
||||
static void ggml_cuda_mul_mat_f16(const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst, void * wdata, size_t /* wsize */) {
|
||||
const int64_t ne00 = src0->ne[0];
|
||||
const int64_t ne01 = src0->ne[1];
|
||||
const int64_t ne02 = src0->ne[2];
|
||||
const int64_t ne03 = src0->ne[3];
|
||||
|
||||
const int64_t ne10 = src1->ne[0];
|
||||
const int64_t ne11 = src1->ne[1];
|
||||
|
||||
const int nb10 = src1->nb[0];
|
||||
const int nb11 = src1->nb[1];
|
||||
const int nb12 = src1->nb[2];
|
||||
const int nb13 = src1->nb[3];
|
||||
|
||||
const int nb2 = dst->nb[2];
|
||||
const int nb3 = dst->nb[3];
|
||||
|
||||
const float alpha = 1.0f;
|
||||
const float beta = 0.0f;
|
||||
const int x_ne = ne01 * ne00;
|
||||
const int y_ne = ne11 * ne10;
|
||||
const int d_ne = ne11 * ne01;
|
||||
const int n_mm = ne03 * ne02;
|
||||
|
||||
size_t x_size, y_size, d_size;
|
||||
half * d_X = (half *) ggml_cuda_pool_malloc(n_mm * sizeof(half) * x_ne, &x_size);
|
||||
half * d_Y = (half *) ggml_cuda_pool_malloc(n_mm * sizeof(half) * y_ne, &y_size);
|
||||
float * d_D = (float *) ggml_cuda_pool_malloc(n_mm * sizeof(float) * d_ne, &d_size);
|
||||
|
||||
bool src1_cont_rows = nb10 == sizeof(float);
|
||||
bool src1_cont_cols = (size_t)nb11 == ne11*sizeof(float);
|
||||
|
||||
for (int64_t i03 = 0; i03 < ne03; i03++) {
|
||||
for (int64_t i02 = 0; i02 < ne02; i02++) {
|
||||
int i = i03*ne02 + i02;
|
||||
cudaStream_t cudaStream = g_cudaStreams[i % GGML_CUDA_MAX_STREAMS];
|
||||
|
||||
half * c_X = d_X + i * x_ne;
|
||||
half * c_Y = d_Y + i * y_ne;
|
||||
float * c_D = d_D + i * d_ne;
|
||||
|
||||
// copy src0 to device
|
||||
CUDA_CHECK(ggml_cuda_h2d_tensor_2d(c_X, src0, i03, i02, cudaStream));
|
||||
|
||||
// convert src1 to fp16
|
||||
// TODO: use multiple threads
|
||||
ggml_fp16_t * const tmp = (ggml_fp16_t *) wdata + (ne11 * ne10) * (i03 * ne02 + i02);
|
||||
char * src1i = (char *) src1->data + i03*nb13 + i02*nb12;
|
||||
if (src1_cont_rows) {
|
||||
if (src1_cont_cols) {
|
||||
ggml_fp32_to_fp16_row((float *) src1i, tmp, ne10*ne11);
|
||||
}
|
||||
else {
|
||||
for (int64_t i01 = 0; i01 < ne11; i01++) {
|
||||
ggml_fp32_to_fp16_row((float *) (src1i + i01*nb11), tmp + i01*ne10, ne10);
|
||||
}
|
||||
}
|
||||
}
|
||||
else {
|
||||
for (int64_t i01 = 0; i01 < ne11; i01++) {
|
||||
for (int64_t i00 = 0; i00 < ne10; i00++) {
|
||||
// very slow due to no inlining
|
||||
tmp[i01*ne10 + i00] = ggml_fp32_to_fp16(*(float *) (src1i + i01*nb11 + i00*nb10));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// copy src1 to device
|
||||
CUDA_CHECK(cudaMemcpyAsync(c_Y, tmp, sizeof(half) * y_ne, cudaMemcpyHostToDevice, cudaStream));
|
||||
|
||||
// compute
|
||||
CUBLAS_CHECK(cublasSetStream(g_cublasH, cudaStream));
|
||||
CUBLAS_CHECK(
|
||||
cublasGemmEx(g_cublasH, CUBLAS_OP_T, CUBLAS_OP_N,
|
||||
ne01, ne11, ne10,
|
||||
&alpha, c_X, CUDA_R_16F, ne00,
|
||||
c_Y, CUDA_R_16F, ne10,
|
||||
&beta, c_D, CUDA_R_32F, ne01,
|
||||
CUBLAS_COMPUTE_32F_FAST_16F,
|
||||
CUBLAS_GEMM_DEFAULT));
|
||||
|
||||
// copy dst to host
|
||||
float * d = (float *) ((char *) dst->data + i02*nb2 + i03*nb3);
|
||||
CUDA_CHECK(cudaMemcpyAsync(d, c_D, sizeof(float) * d_ne, cudaMemcpyDeviceToHost, cudaStream));
|
||||
}
|
||||
}
|
||||
|
||||
CUDA_CHECK(cudaDeviceSynchronize());
|
||||
ggml_cuda_pool_free(d_X, x_size);
|
||||
ggml_cuda_pool_free(d_Y, y_size);
|
||||
ggml_cuda_pool_free(d_D, d_size);
|
||||
}
|
||||
|
||||
static void ggml_cuda_mul_mat_q_f32(const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
||||
const int64_t ne00 = src0->ne[0];
|
||||
const int64_t ne01 = src0->ne[1];
|
||||
const int64_t ne02 = src0->ne[2];
|
||||
const int64_t ne03 = src0->ne[3];
|
||||
|
||||
const int64_t ne10 = src1->ne[0];
|
||||
const int64_t ne11 = src1->ne[1];
|
||||
|
||||
const int nb2 = dst->nb[2];
|
||||
const int nb3 = dst->nb[3];
|
||||
const ggml_type type = src0->type;
|
||||
const bool mul_mat_vec = ne11 == 1;
|
||||
|
||||
const float alpha = 1.0f;
|
||||
const float beta = 0.0f;
|
||||
const int x_ne = ne01 * ne00;
|
||||
const int y_ne = ne11 * ne10;
|
||||
const int d_ne = ne11 * ne01;
|
||||
const int n_mm = ne03 * ne02;
|
||||
const size_t q_sz = ggml_type_size(type) * x_ne / ggml_blck_size(type);
|
||||
|
||||
size_t x_size, y_size, d_size, q_size;
|
||||
float * d_X = nullptr;
|
||||
if (!mul_mat_vec) {
|
||||
d_X = (float *) ggml_cuda_pool_malloc(n_mm * sizeof(float) * x_ne, &x_size);
|
||||
}
|
||||
float * d_Y = (float *) ggml_cuda_pool_malloc(n_mm * sizeof(float) * y_ne, &y_size);
|
||||
float * d_D = (float *) ggml_cuda_pool_malloc(n_mm * sizeof(float) * d_ne, &d_size);
|
||||
char * d_Q = (char *) ggml_cuda_pool_malloc(n_mm * q_sz, &q_size);
|
||||
|
||||
const to_fp32_cuda_t to_fp32_cuda = ggml_get_to_fp32_cuda(type);
|
||||
dequantize_mul_mat_vec_cuda_t dmmv = ggml_get_dequantize_mul_mat_vec_cuda(type);
|
||||
GGML_ASSERT(to_fp32_cuda != nullptr);
|
||||
|
||||
for (int64_t i03 = 0; i03 < ne03; i03++) {
|
||||
for (int64_t i02 = 0; i02 < ne02; i02++) {
|
||||
int i = i03*ne02 + i02;
|
||||
cudaStream_t cudaStream = g_cudaStreams[i % GGML_CUDA_MAX_STREAMS];
|
||||
cudaStream_t cudaStream2 = g_cudaStreams2[i % GGML_CUDA_MAX_STREAMS];
|
||||
cudaEvent_t cudaEvent = g_cudaEvents[i % GGML_CUDA_MAX_EVENTS];
|
||||
|
||||
float * c_Y = d_Y + i * y_ne;
|
||||
float * c_D = d_D + i * d_ne;
|
||||
char * c_Q = d_Q + i * q_sz;
|
||||
|
||||
// copy src0 to device if necessary
|
||||
if (src0->backend == GGML_BACKEND_CPU) {
|
||||
CUDA_CHECK(ggml_cuda_h2d_tensor_2d(c_Q, src0, i03, i02, cudaStream2));
|
||||
} else if (src0->backend == GGML_BACKEND_CUDA) {
|
||||
c_Q = ((char *) src0->data) + i * q_sz;
|
||||
} else {
|
||||
GGML_ASSERT(false);
|
||||
}
|
||||
if (mul_mat_vec) { // specialized dequantize_mul_mat_vec kernel
|
||||
CUDA_CHECK(cudaEventRecord(cudaEvent, cudaStream2));
|
||||
|
||||
// copy src1 to device
|
||||
CUDA_CHECK(ggml_cuda_h2d_tensor_2d(c_Y, src1, i03, i02, cudaStream));
|
||||
|
||||
// wait for data
|
||||
CUDA_CHECK(cudaStreamWaitEvent(cudaStream, cudaEvent, 0));
|
||||
|
||||
// compute
|
||||
dmmv(c_Q, c_Y, c_D, ne00, ne01, cudaStream);
|
||||
CUDA_CHECK(cudaGetLastError());
|
||||
|
||||
} else { // general dequantization kernel + cuBLAS matrix matrix multiplication
|
||||
float * c_X = d_X + i * x_ne;
|
||||
|
||||
// convert src0 to fp32 on device
|
||||
to_fp32_cuda(c_Q, c_X, x_ne, cudaStream2);
|
||||
CUDA_CHECK(cudaGetLastError());
|
||||
CUDA_CHECK(cudaEventRecord(cudaEvent, cudaStream2));
|
||||
|
||||
// copy src1 to device
|
||||
CUDA_CHECK(ggml_cuda_h2d_tensor_2d(c_Y, src1, i03, i02, cudaStream));
|
||||
|
||||
// wait for conversion
|
||||
CUDA_CHECK(cudaStreamWaitEvent(cudaStream, cudaEvent, 0));
|
||||
|
||||
// compute
|
||||
CUBLAS_CHECK(cublasSetStream(g_cublasH, cudaStream));
|
||||
CUBLAS_CHECK(
|
||||
cublasSgemm(g_cublasH, CUBLAS_OP_T, CUBLAS_OP_N,
|
||||
ne01, ne11, ne10,
|
||||
&alpha, c_X, ne00,
|
||||
c_Y, ne10,
|
||||
&beta, c_D, ne01));
|
||||
}
|
||||
|
||||
// copy dst to host
|
||||
float * d = (float *) ((char *) dst->data + i02*nb2 + i03*nb3);
|
||||
CUDA_CHECK(cudaMemcpyAsync(d, c_D, sizeof(float) * d_ne, cudaMemcpyDeviceToHost, cudaStream));
|
||||
}
|
||||
}
|
||||
|
||||
CUDA_CHECK(cudaDeviceSynchronize());
|
||||
if (!mul_mat_vec) {
|
||||
ggml_cuda_pool_free(d_X, x_size);
|
||||
}
|
||||
ggml_cuda_pool_free(d_Y, y_size);
|
||||
ggml_cuda_pool_free(d_D, d_size);
|
||||
ggml_cuda_pool_free(d_Q, q_size);
|
||||
}
|
||||
|
||||
void ggml_cuda_mul(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst) {
|
||||
GGML_ASSERT(src0->type == GGML_TYPE_F32 && src1->type == GGML_TYPE_F32 && dst->type == GGML_TYPE_F32);
|
||||
ggml_cuda_mul_f32(src0, src1, dst);
|
||||
}
|
||||
|
||||
bool ggml_cuda_can_mul_mat(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst) {
|
||||
const int64_t ne10 = src1->ne[0];
|
||||
|
||||
const int64_t ne0 = dst->ne[0];
|
||||
const int64_t ne1 = dst->ne[1];
|
||||
|
||||
// TODO: find the optimal values for these
|
||||
if ((src0->type == GGML_TYPE_F32 || src0->type == GGML_TYPE_F16 || ggml_is_quantized(src0->type)) &&
|
||||
src1->type == GGML_TYPE_F32 &&
|
||||
dst->type == GGML_TYPE_F32 &&
|
||||
((ne0 >= 32 && ne1 >= 32 && ne10 >= 32) || src0->backend == GGML_BACKEND_CUDA)) {
|
||||
return true;
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
|
||||
bool ggml_cuda_mul_mat_use_f16(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * /* dst */) {
|
||||
size_t src0_sz = ggml_nbytes(src0);
|
||||
size_t src1_sz = ggml_nbytes(src1);
|
||||
|
||||
// mul_mat_q: src0 is converted to fp32 on device
|
||||
size_t mul_mat_q_transfer = src0_sz + src1_sz;
|
||||
|
||||
// mul_mat_f16: src1 is converted to fp16 on cpu
|
||||
size_t mul_mat_f16_transfer = src0_sz + sizeof(half) * ggml_nelements(src1);
|
||||
|
||||
// choose the smaller one to transfer to the device
|
||||
// TODO: this is not always the best choice due to the overhead of converting to fp16
|
||||
return mul_mat_f16_transfer < mul_mat_q_transfer;
|
||||
}
|
||||
|
||||
void ggml_cuda_mul_mat(const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst, void * wdata, size_t wsize) {
|
||||
GGML_ASSERT(ggml_cuda_can_mul_mat(src0, src1, dst));
|
||||
|
||||
if (src0->type == GGML_TYPE_F32) {
|
||||
ggml_cuda_mul_mat_f32(src0, src1, dst);
|
||||
}
|
||||
else if (src0->type == GGML_TYPE_F16) {
|
||||
if (ggml_cuda_mul_mat_use_f16(src0, src1, dst)) {
|
||||
ggml_cuda_mul_mat_f16(src0, src1, dst, wdata, wsize);
|
||||
}
|
||||
else {
|
||||
ggml_cuda_mul_mat_q_f32(src0, src1, dst);
|
||||
}
|
||||
}
|
||||
else if (ggml_is_quantized(src0->type)) {
|
||||
ggml_cuda_mul_mat_q_f32(src0, src1, dst);
|
||||
}
|
||||
else {
|
||||
GGML_ASSERT(false);
|
||||
}
|
||||
}
|
||||
|
||||
size_t ggml_cuda_mul_mat_get_wsize(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst) {
|
||||
if (ggml_cuda_mul_mat_use_f16(src0, src1, dst)) {
|
||||
return ggml_nelements(src1) * sizeof(ggml_fp16_t);
|
||||
}
|
||||
else {
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
|
||||
void ggml_cuda_transform_tensor(ggml_tensor * tensor) {
|
||||
const int64_t ne0 = tensor->ne[0];
|
||||
const int64_t ne1 = tensor->ne[1];
|
||||
const int64_t ne2 = tensor->ne[2];
|
||||
const int64_t ne3 = tensor->ne[3];
|
||||
|
||||
const ggml_type type = tensor->type;
|
||||
const size_t q_sz = ggml_type_size(type) * ne0 * ne1 * ne2 * ne3 / ggml_blck_size(type);
|
||||
|
||||
size_t q_size;
|
||||
char * dst = (char *) ggml_cuda_pool_malloc(q_sz, &q_size);
|
||||
|
||||
cudaStream_t cudaStream2 = g_cudaStreams2[0];
|
||||
|
||||
// copy tensor to device
|
||||
for (int64_t i3 = 0; i3 < ne3; i3++) {
|
||||
for (int64_t i2 = 0; i2 < ne2; i2++) {
|
||||
int i = i3*ne2 + i2;
|
||||
CUDA_CHECK(ggml_cuda_h2d_tensor_2d(dst + i*ne0*ne1, tensor, i3, i2, cudaStream2));
|
||||
}
|
||||
}
|
||||
|
||||
tensor->data = dst;
|
||||
tensor->backend = GGML_BACKEND_CUDA;
|
||||
}
|
||||
|
||||
void ggml_cuda_load_data(const char * fname, struct ggml_tensor * tensor, const size_t offset) {
|
||||
FILE * fp = fopen(fname, "rb");
|
||||
|
||||
const size_t size = ggml_nbytes(tensor);
|
||||
|
||||
void * buf;
|
||||
CUDA_CHECK(cudaMalloc(&buf, size));
|
||||
void * buf_host = malloc(size);
|
||||
|
||||
#ifdef _WIN32
|
||||
int ret = _fseeki64(fp, (__int64) offset, SEEK_SET);
|
||||
#else
|
||||
int ret = fseek(fp, (long) offset, SEEK_SET);
|
||||
#endif
|
||||
GGML_ASSERT(ret == 0); // same
|
||||
|
||||
size_t ret2 = fread(buf_host, size, 1, fp);
|
||||
if (ret2 != 1) {
|
||||
fprintf(stderr, "unexpectedly reached end of file");
|
||||
exit(1);
|
||||
}
|
||||
|
||||
cudaMemcpy(buf, buf_host, size, cudaMemcpyHostToDevice);
|
||||
cudaDeviceSynchronize();
|
||||
|
||||
tensor->data = buf;
|
||||
free(buf_host);
|
||||
fclose(fp);
|
||||
}
|
||||
|
|
@ -0,0 +1,23 @@
|
|||
#include "ggml.h"
|
||||
|
||||
#ifdef __cplusplus
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
void ggml_init_cublas(void);
|
||||
|
||||
void ggml_cuda_mul(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst);
|
||||
bool ggml_cuda_can_mul_mat(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst);
|
||||
size_t ggml_cuda_mul_mat_get_wsize(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst);
|
||||
void ggml_cuda_mul_mat(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst, void * wdata, size_t wsize);
|
||||
|
||||
// TODO: export these with GGML_API
|
||||
void * ggml_cuda_host_malloc(size_t size);
|
||||
void ggml_cuda_host_free(void * ptr);
|
||||
|
||||
void ggml_cuda_transform_tensor(struct ggml_tensor * tensor);
|
||||
void ggml_cuda_load_data(const char * fname, struct ggml_tensor * tensors, size_t offset);
|
||||
|
||||
#ifdef __cplusplus
|
||||
}
|
||||
#endif
|
||||
|
|
@ -0,0 +1,361 @@
|
|||
#include "ggml-opencl.h"
|
||||
|
||||
#define CL_TARGET_OPENCL_VERSION 110
|
||||
#include <clblast_c.h>
|
||||
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
|
||||
#include "ggml.h"
|
||||
|
||||
#define MULTILINE_QUOTE(...) #__VA_ARGS__
|
||||
const char * clblast_dequant = MULTILINE_QUOTE(
|
||||
|
||||
typedef uchar uint8_t;
|
||||
typedef int int32_t;
|
||||
typedef uint uint32_t;
|
||||
|
||||
constant uint QK4_0 = 32;
|
||||
struct block_q4_0
|
||||
{
|
||||
float d;
|
||||
uint8_t qs[QK4_0 / 2];
|
||||
};
|
||||
|
||||
constant uint QK4_1 = 32;
|
||||
struct block_q4_1
|
||||
{
|
||||
float d;
|
||||
float m;
|
||||
uint8_t qs[QK4_1 / 2];
|
||||
};
|
||||
|
||||
constant uint QK5_0 = 32;
|
||||
struct __attribute__ ((packed)) block_q5_0
|
||||
{
|
||||
half d;
|
||||
uint32_t qh;
|
||||
uint8_t qs[QK5_0 / 2];
|
||||
};
|
||||
|
||||
constant uint QK5_1 = 32;
|
||||
struct block_q5_1
|
||||
{
|
||||
half d;
|
||||
half m;
|
||||
uint32_t qh;
|
||||
uint8_t qs[QK5_1 / 2];
|
||||
};
|
||||
|
||||
constant uint QK8_0 = 32;
|
||||
struct block_q8_0
|
||||
{
|
||||
float d;
|
||||
uint8_t qs[QK8_0];
|
||||
};
|
||||
|
||||
|
||||
__kernel void dequantize_row_q4_0(__global struct block_q4_0* x, __global float* y) {
|
||||
constant uint qk = QK4_0;
|
||||
|
||||
const uint i = get_global_id(0) / qk;
|
||||
const uint j = get_local_id(0);
|
||||
|
||||
const float d = x[i].d;
|
||||
|
||||
const int x0 = (x[i].qs[j] & 0xf) - 8;
|
||||
const int x1 = (x[i].qs[j] >> 4) - 8;
|
||||
|
||||
y[i*qk + j + 0 ] = x0*d;
|
||||
y[i*qk + j + qk/2] = x1*d;
|
||||
}
|
||||
|
||||
__kernel void dequantize_row_q4_1(__global struct block_q4_1* x, __global float* y) {
|
||||
constant uint qk = QK4_1;
|
||||
|
||||
const uint i = get_global_id(0) / qk;
|
||||
const uint j = get_local_id(0);
|
||||
|
||||
const float d = x[i].d;
|
||||
const float m = x[i].m;
|
||||
|
||||
const int x0 = (x[i].qs[j] & 0xf);
|
||||
const int x1 = (x[i].qs[j] >> 4);
|
||||
|
||||
y[i*qk + j + 0 ] = x0*d + m;
|
||||
y[i*qk + j + qk/2] = x1*d + m;
|
||||
}
|
||||
|
||||
__kernel void dequantize_row_q5_0(__global struct block_q5_0* x, __global float* y) {
|
||||
constant uint qk = QK5_0;
|
||||
|
||||
const uint i = get_global_id(0) / qk;
|
||||
const uint j = get_local_id(0);
|
||||
|
||||
const float d = vload_half(0, (__global half*) &x[i].d);
|
||||
|
||||
uint32_t qh = x[i].qh;
|
||||
|
||||
const uint8_t xh_0 = ((qh >> (j + 0)) << 4) & 0x10;
|
||||
const uint8_t xh_1 = ((qh >> (j + 12)) ) & 0x10;
|
||||
|
||||
const int32_t x0 = ((x[i].qs[j] & 0xf) | xh_0) - 16;
|
||||
const int32_t x1 = ((x[i].qs[j] >> 4) | xh_1) - 16;
|
||||
|
||||
y[i*qk + j + 0 ] = x0*d;
|
||||
y[i*qk + j + qk/2] = x1*d;
|
||||
}
|
||||
|
||||
__kernel void dequantize_row_q5_1(__global struct block_q5_1* x, __global float* y) {
|
||||
constant uint qk = QK5_1;
|
||||
|
||||
const uint i = get_global_id(0) / qk;
|
||||
const uint j = get_local_id(0);
|
||||
|
||||
const float d = vload_half(0, (__global half*) &x[i].d);
|
||||
const float m = vload_half(0, (__global half*) &x[i].m);
|
||||
|
||||
uint32_t qh = x[i].qh;
|
||||
|
||||
const uint8_t xh_0 = ((qh >> (j + 0)) << 4) & 0x10;
|
||||
const uint8_t xh_1 = ((qh >> (j + 12)) ) & 0x10;
|
||||
|
||||
const int x0 = (x[i].qs[j] & 0xf) | xh_0;
|
||||
const int x1 = (x[i].qs[j] >> 4) | xh_1;
|
||||
|
||||
y[i*qk + j + 0 ] = x0*d + m;
|
||||
y[i*qk + j + qk/2] = x1*d + m;
|
||||
}
|
||||
|
||||
__kernel void dequantize_row_q8_0(__global struct block_q8_0* x, __global float* y) {
|
||||
constant uint qk = QK8_0;
|
||||
const uint i = get_global_id(0) / qk;
|
||||
const uint j = get_local_id(0);
|
||||
|
||||
const float d = x[i].d;
|
||||
y[i*qk + j] = x[i].qs[j]*d;
|
||||
}
|
||||
|
||||
);
|
||||
|
||||
#define CL_CHECK(err, name) \
|
||||
do { \
|
||||
cl_int err_ = (err); \
|
||||
if (err_ != CL_SUCCESS) { \
|
||||
fprintf(stderr, "OpenCL %s error %d at %s:%d\n", name, err_, __FILE__, __LINE__); \
|
||||
exit(1); \
|
||||
} \
|
||||
} while (0)
|
||||
|
||||
static cl_platform_id platform;
|
||||
static cl_device_id device;
|
||||
static cl_context context;
|
||||
static cl_command_queue queue;
|
||||
static cl_program program;
|
||||
static cl_kernel kernel_q4_0, kernel_q4_1, kernel_q5_0, kernel_q5_1, kernel_q8_0;
|
||||
static cl_mem cl_buffer_a, cl_buffer_qb, cl_buffer_b, cl_buffer_c;
|
||||
static size_t cl_size_a = 0, cl_size_qb = 0, cl_size_b = 0, cl_size_c = 0;
|
||||
|
||||
static cl_program build_program_from_source(cl_context ctx, cl_device_id dev, const char* program_buffer) {
|
||||
cl_program p;
|
||||
char *program_log;
|
||||
size_t program_size, log_size;
|
||||
int err;
|
||||
|
||||
program_size = strlen(program_buffer);
|
||||
|
||||
p = clCreateProgramWithSource(ctx, 1, (const char**)&program_buffer, &program_size, &err);
|
||||
if(err < 0) {
|
||||
fprintf(stderr, "OpenCL error creating program");
|
||||
exit(1);
|
||||
}
|
||||
|
||||
err = clBuildProgram(p, 0, NULL, NULL, NULL, NULL);
|
||||
if(err < 0) {
|
||||
|
||||
clGetProgramBuildInfo(p, dev, CL_PROGRAM_BUILD_LOG, 0, NULL, &log_size);
|
||||
program_log = (char*) malloc(log_size + 1);
|
||||
program_log[log_size] = '\0';
|
||||
clGetProgramBuildInfo(p, dev, CL_PROGRAM_BUILD_LOG, log_size + 1, program_log, NULL);
|
||||
printf("%s\n", program_log);
|
||||
free(program_log);
|
||||
exit(1);
|
||||
}
|
||||
|
||||
return p;
|
||||
}
|
||||
|
||||
void ggml_cl_init(void) {
|
||||
cl_int err = 0;
|
||||
char * GGML_CLBLAST_PLATFORM = getenv("GGML_CLBLAST_PLATFORM");
|
||||
char * GGML_CLBLAST_DEVICE = getenv("GGML_CLBLAST_DEVICE");
|
||||
int plat_num = (GGML_CLBLAST_PLATFORM == NULL ? 0 : atoi(GGML_CLBLAST_PLATFORM));
|
||||
int dev_num = (GGML_CLBLAST_DEVICE == NULL ? 0 : atoi(GGML_CLBLAST_DEVICE));
|
||||
printf("\nInitializing CLBlast (First Run)...");
|
||||
printf("\nAttempting to use: Platform=%d, Device=%d (If invalid, program will crash)\n",plat_num,dev_num);
|
||||
cl_uint num_platforms;
|
||||
clGetPlatformIDs(0, NULL, &num_platforms);
|
||||
cl_platform_id* platforms = (cl_platform_id*)malloc(num_platforms*sizeof(cl_platform_id));
|
||||
clGetPlatformIDs(num_platforms, platforms, NULL);
|
||||
platform = platforms[plat_num];
|
||||
char platform_buffer[1024];
|
||||
clGetPlatformInfo(platform, CL_PLATFORM_NAME, sizeof(platform_buffer), &platform_buffer, NULL);
|
||||
cl_uint num_devices;
|
||||
clGetDeviceIDs(platform, CL_DEVICE_TYPE_ALL, 0, NULL, &num_devices);
|
||||
cl_device_id* devices = (cl_device_id*)malloc(num_devices*sizeof(cl_device_id));
|
||||
clGetDeviceIDs(platform, CL_DEVICE_TYPE_ALL, num_devices, devices, NULL);
|
||||
device = devices[dev_num];
|
||||
char device_buffer[1024];
|
||||
clGetDeviceInfo(device, CL_DEVICE_NAME, sizeof(device_buffer), &device_buffer, NULL);
|
||||
printf("Using Platform: %s Device: %s\n", platform_buffer, device_buffer);
|
||||
context = clCreateContext(NULL, 1, &device, NULL, NULL, &err);
|
||||
CL_CHECK(err, "clCreateContext");
|
||||
queue = clCreateCommandQueue(context, device, CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE, &err);
|
||||
CL_CHECK(err, "clCreateCommandQueue");
|
||||
|
||||
free(platforms);
|
||||
free(devices);
|
||||
|
||||
program = build_program_from_source(context, device, clblast_dequant);
|
||||
|
||||
// Prepare dequantize kernels
|
||||
kernel_q4_0 = clCreateKernel(program, "dequantize_row_q4_0", &err);
|
||||
CL_CHECK(err, "clCreateKernel");
|
||||
kernel_q4_1 = clCreateKernel(program, "dequantize_row_q4_1", &err);
|
||||
CL_CHECK(err, "clCreateKernel");
|
||||
kernel_q5_0 = clCreateKernel(program, "dequantize_row_q5_0", &err);
|
||||
CL_CHECK(err, "clCreateKernel");
|
||||
kernel_q5_1 = clCreateKernel(program, "dequantize_row_q5_1", &err);
|
||||
CL_CHECK(err, "clCreateKernel");
|
||||
kernel_q8_0 = clCreateKernel(program, "dequantize_row_q8_0", &err);
|
||||
CL_CHECK(err, "clCreateKernel");
|
||||
}
|
||||
|
||||
static void ggml_cl_malloc(size_t req_size, size_t* cur_size, cl_mem_flags flags, cl_mem* buf) {
|
||||
if (req_size <= *cur_size) {
|
||||
return;
|
||||
}
|
||||
|
||||
// Reallocate buffer with enough space
|
||||
if (*cur_size > 0) {
|
||||
clReleaseMemObject(*buf);
|
||||
}
|
||||
cl_int err;
|
||||
*buf = clCreateBuffer(context, flags, req_size, NULL, &err);
|
||||
*cur_size = req_size;
|
||||
CL_CHECK(err, "clCreateBuffer");
|
||||
}
|
||||
|
||||
void ggml_cl_sgemm_wrapper(
|
||||
const enum ggml_blas_order order, const enum ggml_blas_op trans_a, const enum ggml_blas_op trans_b,
|
||||
const int m, const int n, const int k,
|
||||
const float alpha, const void *host_a, const int lda,
|
||||
const float *host_b, const int ldb, const float beta,
|
||||
float *host_c, const int ldc, const int btype) {
|
||||
cl_int err = 0;
|
||||
|
||||
cl_kernel kernel;
|
||||
size_t global = n * k, local, size_qb;
|
||||
bool dequant;
|
||||
|
||||
switch (btype) {
|
||||
case GGML_TYPE_F32:
|
||||
dequant = false;
|
||||
break;
|
||||
case GGML_TYPE_Q4_0:
|
||||
dequant = true;
|
||||
kernel = kernel_q4_0;
|
||||
local = 16;
|
||||
size_qb = global * (sizeof(float) + local) / 32;
|
||||
break;
|
||||
case GGML_TYPE_Q4_1:
|
||||
dequant = true;
|
||||
kernel = kernel_q4_1;
|
||||
local = 16;
|
||||
size_qb = global * (sizeof(float) * 2 + local) / 32;
|
||||
break;
|
||||
case GGML_TYPE_Q5_0:
|
||||
dequant = true;
|
||||
kernel = kernel_q5_0;
|
||||
local = 16;
|
||||
size_qb = global * (sizeof(ggml_fp16_t) + sizeof(uint32_t) + local) / 32;
|
||||
break;
|
||||
case GGML_TYPE_Q5_1:
|
||||
dequant = true;
|
||||
kernel = kernel_q5_1;
|
||||
local = 16;
|
||||
size_qb = global * (sizeof(ggml_fp16_t) * 2 + sizeof(uint32_t) + local) / 32;
|
||||
break;
|
||||
case GGML_TYPE_Q8_0:
|
||||
dequant = true;
|
||||
kernel = kernel_q8_0;
|
||||
local = 32;
|
||||
size_qb = global * (sizeof(float) + local) / 32;
|
||||
break;
|
||||
default:
|
||||
fprintf(stderr, "Error: Unsupported OpenCL btype %d\n", btype);
|
||||
abort();
|
||||
}
|
||||
|
||||
const size_t size_a = m * k * sizeof(float);
|
||||
const size_t size_b = n * k * sizeof(float);
|
||||
const size_t size_c = m * n * sizeof(float);
|
||||
|
||||
// Prepare buffers
|
||||
ggml_cl_malloc(size_a, &cl_size_a, CL_MEM_READ_ONLY, &cl_buffer_a);
|
||||
if (dequant) {
|
||||
ggml_cl_malloc(size_qb, &cl_size_qb, CL_MEM_READ_ONLY, &cl_buffer_qb);
|
||||
}
|
||||
ggml_cl_malloc(size_b, &cl_size_b, CL_MEM_READ_WRITE, &cl_buffer_b);
|
||||
ggml_cl_malloc(size_c, &cl_size_c, CL_MEM_WRITE_ONLY, &cl_buffer_c);
|
||||
|
||||
cl_event ev_a, ev_qb, ev_b;
|
||||
|
||||
if (dequant) {
|
||||
err = clSetKernelArg(kernel, 0, sizeof(cl_mem), &cl_buffer_qb);
|
||||
err |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &cl_buffer_b);
|
||||
CL_CHECK(err, "clSetKernelArg");
|
||||
err = clEnqueueWriteBuffer(queue, cl_buffer_qb, CL_FALSE, 0, size_qb, host_b, 0, NULL, &ev_qb);
|
||||
CL_CHECK(err, "clEnqueueWriteBuffer qb");
|
||||
} else {
|
||||
err = clEnqueueWriteBuffer(queue, cl_buffer_b, CL_FALSE, 0, size_b, host_b, 0, NULL, &ev_b);
|
||||
CL_CHECK(err, "clEnqueueWriteBuffer b");
|
||||
}
|
||||
|
||||
err = clEnqueueWriteBuffer(queue, cl_buffer_a, CL_FALSE, 0, size_a, host_a, 0, NULL, &ev_a);
|
||||
CL_CHECK(err, "clEnqueueWriteBuffer a");
|
||||
if (dequant) {
|
||||
err = clEnqueueNDRangeKernel(queue, kernel, 1, NULL, &global, &local, 1, &ev_qb, &ev_b);
|
||||
CL_CHECK(err, "clEnqueueNDRangeKernel");
|
||||
clReleaseEvent(ev_qb);
|
||||
}
|
||||
clWaitForEvents(1, &ev_a);
|
||||
clWaitForEvents(1, &ev_b);
|
||||
clReleaseEvent(ev_a);
|
||||
clReleaseEvent(ev_b);
|
||||
|
||||
cl_event ev_sgemm;
|
||||
CLBlastStatusCode status = CLBlastSgemm((CLBlastLayout)order,
|
||||
(CLBlastTranspose)trans_a, (CLBlastTranspose)trans_b,
|
||||
m, n, k,
|
||||
alpha,
|
||||
cl_buffer_a, 0, lda,
|
||||
cl_buffer_b, 0, ldb,
|
||||
beta,
|
||||
cl_buffer_c, 0, ldc,
|
||||
&queue, &ev_sgemm);
|
||||
|
||||
if (status != CLBlastSuccess) {
|
||||
fprintf(stderr, "Error: CLBlast SGEMM %d\n", status);
|
||||
abort();
|
||||
}
|
||||
|
||||
cl_event ev_c;
|
||||
clEnqueueReadBuffer(queue, cl_buffer_c, CL_TRUE, 0, size_c, host_c, 1, &ev_sgemm, &ev_c);
|
||||
|
||||
// Wait for completion
|
||||
clWaitForEvents(1, &ev_c);
|
||||
clReleaseEvent(ev_sgemm);
|
||||
clReleaseEvent(ev_c);
|
||||
}
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
#pragma once
|
||||
|
||||
#ifdef __cplusplus
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
void ggml_cl_init(void);
|
||||
|
||||
enum ggml_blas_order {
|
||||
GGML_BLAS_ORDER_ROW_MAJOR = 101,
|
||||
GGML_BLAS_ORDER_COLUMN_MAJOR = 102,
|
||||
};
|
||||
|
||||
enum ggml_blas_op {
|
||||
GGML_BLAS_OP_N = 111,
|
||||
GGML_BLAS_OP_T = 112,
|
||||
GGML_BLAS_OP_C = 113,
|
||||
};
|
||||
|
||||
void ggml_cl_sgemm_wrapper(const enum ggml_blas_order order, const enum ggml_blas_op trans_a, const enum ggml_blas_op trans_b, const int m, const int n, const int k, const float alpha, const void *host_a, const int lda, const float *host_b, const int ldb, const float beta, float *host_c, const int ldc, const int btype);
|
||||
|
||||
#ifdef __cplusplus
|
||||
}
|
||||
#endif
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,260 @@
|
|||
# check systems
|
||||
if (NOT UNAME_S)
|
||||
execute_process(COMMAND uname -s OUTPUT_VARIABLE UNAME_S)
|
||||
endif()
|
||||
if (NOT UNAME_P)
|
||||
execute_process(COMMAND uname -p OUTPUT_VARIABLE UNAME_P)
|
||||
endif()
|
||||
if (NOT UNAME_M)
|
||||
execute_process(COMMAND uname -m OUTPUT_VARIABLE UNAME_M)
|
||||
endif()
|
||||
#message(STATUS "UNAME_S: ${UNAME_S} UNAME_P: ${UNAME_P} UNAME_M: ${UNAME_M}")
|
||||
|
||||
# Mac OS + Arm can report x86_64
|
||||
# ref: https://github.com/ggerganov/whisper.cpp/issues/66#issuecomment-1282546789
|
||||
if (UNAME_S MATCHES "Darwin")
|
||||
if (NOT UNAME_P MATCHES "arm")
|
||||
execute_process(COMMAND sysctl -n hw.optional.arm64 OUTPUT_VARIABLE SYSCTL_M)
|
||||
if (SYSCTL_M MATCHES "1")
|
||||
#set(UNAME_P "arm")
|
||||
#set(UNAME_M "arm64")
|
||||
message(WARNING "Your arch is announced as x86_64, but it seems to actually be ARM64. Not fixing that can lea
|
||||
d to bad performance. For more info see: https://github.com/ggerganov/whisper.cpp/issues/66\#issuecomment-#1282546789")
|
||||
endif()
|
||||
endif()
|
||||
endif()
|
||||
|
||||
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "arm" OR ${CMAKE_SYSTEM_PROCESSOR} MATCHES "aarch64")
|
||||
message(STATUS "ARM detected")
|
||||
#set(GGML_C_FLAGS "${GGML_C_FLAGS} -mcpu=apple-m1")
|
||||
else()
|
||||
message(STATUS "x86 detected")
|
||||
#set(GGML_C_FLAGS "${GGML_C_FLAGS} -mavx -mavx2 -mfma -mf16c")
|
||||
if (UNAME_S MATCHES "Darwin")
|
||||
execute_process(COMMAND sysctl machdep.cpu.features OUTPUT_VARIABLE AVX1_M)
|
||||
if (AVX1_M MATCHES "AVX1.0")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mavx")
|
||||
endif()
|
||||
execute_process(COMMAND sysctl machdep.cpu.leaf7_features OUTPUT_VARIABLE AVX2_M)
|
||||
if (AVX2_M MATCHES "AVX2")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mavx2")
|
||||
endif()
|
||||
if (AVX1_M MATCHES "FMA")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mfma")
|
||||
endif()
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mf16c")
|
||||
elseif (UNAME_S MATCHES "Linux")
|
||||
message(STATUS "Linux detected")
|
||||
execute_process(COMMAND grep "avx " /proc/cpuinfo OUTPUT_VARIABLE AVX1_M)
|
||||
if (AVX1_M MATCHES "avx")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mavx")
|
||||
endif()
|
||||
execute_process(COMMAND grep "avx2 " /proc/cpuinfo OUTPUT_VARIABLE AVX2_M)
|
||||
if (AVX2_M MATCHES "avx2")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mavx2")
|
||||
endif()
|
||||
execute_process(COMMAND grep "fma " /proc/cpuinfo OUTPUT_VARIABLE FMA_M)
|
||||
if (FMA_M MATCHES "fma")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mfma")
|
||||
endif()
|
||||
execute_process(COMMAND grep "f16c " /proc/cpuinfo OUTPUT_VARIABLE F16C_M)
|
||||
if (F16C_M MATCHES "f16c")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mf16c")
|
||||
endif()
|
||||
execute_process(COMMAND grep "sse3 " /proc/cpuinfo OUTPUT_VARIABLE SSE3_M)
|
||||
if (SSE3_M MATCHES "sse3")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -msse3")
|
||||
endif()
|
||||
elseif (UNAME_S MATCHES "Haiku")
|
||||
message(STATUS "Haiku detected")
|
||||
execute_process(COMMAND sysinfo -cpu COMMAND grep "AVX " OUTPUT_VARIABLE AVX1_M)
|
||||
if (AVX1_M MATCHES "avx")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mavx")
|
||||
endif()
|
||||
execute_process(COMMAND sysinfo -cpu COMMAND grep "AVX2 " OUTPUT_VARIABLE AVX2_M)
|
||||
if (AVX2_M MATCHES "avx2")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mavx2")
|
||||
endif()
|
||||
execute_process(COMMAND sysinfo -cpu COMMAND grep "FMA " OUTPUT_VARIABLE FMA_M)
|
||||
if (FMA_M MATCHES "fma")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mfma")
|
||||
endif()
|
||||
execute_process(COMMAND sysinfo -cpu COMMAND grep "F16C " OUTPUT_VARIABLE F16C_M)
|
||||
if (F16C_M MATCHES "f16c")
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mf16c")
|
||||
endif()
|
||||
else()
|
||||
set(GGML_C_FLAGS "${GGML_C_FLAGS} -mfma -mf16c -mavx -mavx2")
|
||||
endif()
|
||||
endif()
|
||||
|
||||
# on APPLE - include Accelerate framework
|
||||
if (APPLE AND NOT GGML_NO_ACCELERATE)
|
||||
find_library(ACCELERATE_FRAMEWORK Accelerate)
|
||||
if (ACCELERATE_FRAMEWORK)
|
||||
message(STATUS "Accelerate framework found")
|
||||
|
||||
set(GGML_EXTRA_LIBS ${GGML_EXTRA_LIBS} ${ACCELERATE_FRAMEWORK})
|
||||
set(GGML_EXTRA_FLAGS ${GGML_EXTRA_FLAGS} -DGGML_USE_ACCELERATE)
|
||||
else()
|
||||
message(WARNING "Accelerate framework not found")
|
||||
endif()
|
||||
endif()
|
||||
|
||||
if (GGML_OPENBLAS)
|
||||
set(OPENBLAS_INCLUDE_SEARCH_PATHS
|
||||
/usr/include
|
||||
/usr/include/openblas
|
||||
/usr/include/openblas-base
|
||||
/usr/local/include
|
||||
/usr/local/include/openblas
|
||||
/usr/local/include/openblas-base
|
||||
/opt/OpenBLAS/include
|
||||
$ENV{OpenBLAS_HOME}
|
||||
$ENV{OpenBLAS_HOME}/include
|
||||
)
|
||||
find_path(OPENBLAS_INC NAMES cblas.h PATHS ${OPENBLAS_INCLUDE_SEARCH_PATHS})
|
||||
find_library(OPENBLAS_LIB NAMES openblas libopenblas)
|
||||
if (OPENBLAS_LIB)
|
||||
message(STATUS "OpenBLAS found")
|
||||
|
||||
set(GGML_EXTRA_LIBS ${GGML_EXTRA_LIBS} ${OPENBLAS_LIB})
|
||||
set(GGML_EXTRA_INCS ${GGML_EXTRA_INCS} ${OPENBLAS_INC})
|
||||
set(GGML_EXTRA_FLAGS ${GGML_EXTRA_FLAGS} -DGGML_USE_OPENBLAS)
|
||||
else()
|
||||
message(WARNING "OpenBLAS not found")
|
||||
endif()
|
||||
endif()
|
||||
|
||||
#
|
||||
# test-vec0
|
||||
|
||||
set(TEST_TARGET test-vec0)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml)
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
|
||||
#
|
||||
# test-vec1 (x86)
|
||||
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "x86")
|
||||
set(TEST_TARGET test-vec1)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml)
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
#set_target_properties(${TEST_TARGET} PROPERTIES COMPILE_FLAGS "-mavx -mavx2 -mfma -mf16c")
|
||||
set_target_properties(${TEST_TARGET} PROPERTIES COMPILE_FLAGS ${GGML_C_FLAGS})
|
||||
endif()
|
||||
|
||||
#
|
||||
# test-vec2 (arm)
|
||||
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "arm")
|
||||
set(TEST_TARGET test-vec2)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml)
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
endif()
|
||||
|
||||
#
|
||||
# test-grad0
|
||||
|
||||
set(TEST_TARGET test-grad0)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml)
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
|
||||
#
|
||||
# test-opt
|
||||
|
||||
set(TEST_TARGET test-opt)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml)
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
|
||||
#
|
||||
# test-mul-mat0
|
||||
|
||||
set(TEST_TARGET test-mul-mat0)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml ${GGML_EXTRA_LIBS})
|
||||
target_compile_options(${TEST_TARGET} PRIVATE ${GGML_EXTRA_FLAGS})
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
|
||||
#
|
||||
# test-mul-mat1 (arm)
|
||||
|
||||
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "arm" AND NOT GGML_NO_ACCELERATE)
|
||||
set(TEST_TARGET test-mul-mat1)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml ${GGML_EXTRA_LIBS})
|
||||
target_compile_options(${TEST_TARGET} PRIVATE ${GGML_EXTRA_FLAGS})
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
endif()
|
||||
|
||||
#
|
||||
# test-blas0 (arm)
|
||||
|
||||
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "arm" AND NOT GGML_NO_ACCELERATE)
|
||||
set(TEST_TARGET test-blas0)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml ${GGML_EXTRA_LIBS})
|
||||
target_compile_options(${TEST_TARGET} PRIVATE ${GGML_EXTRA_FLAGS})
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}> 128 128 128)
|
||||
endif()
|
||||
|
||||
#
|
||||
# test-mul-mat2
|
||||
|
||||
set(TEST_TARGET test-mul-mat2)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml)
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
|
||||
#
|
||||
# test0
|
||||
|
||||
set(TEST_TARGET test0)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml)
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
|
||||
#
|
||||
# test1
|
||||
|
||||
set(TEST_TARGET test1)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml)
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
|
||||
#
|
||||
# test2
|
||||
|
||||
set(TEST_TARGET test2)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml)
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
|
||||
#
|
||||
# test3
|
||||
|
||||
set(TEST_TARGET test3)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml)
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
|
||||
#
|
||||
# test-svd0 (arm/x86)
|
||||
|
||||
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "arm" AND NOT GGML_NO_ACCELERATE)
|
||||
set(TEST_TARGET test-svd0)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml ${GGML_EXTRA_LIBS})
|
||||
target_compile_options(${TEST_TARGET} PRIVATE ${GGML_EXTRA_FLAGS})
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
elseif (${CMAKE_SYSTEM_PROCESSOR} MATCHES "x86" AND GGML_OPENBLAS)
|
||||
set(TEST_TARGET test-svd0)
|
||||
add_executable(${TEST_TARGET} ${TEST_TARGET}.c)
|
||||
target_link_libraries(${TEST_TARGET} PRIVATE ggml ${GGML_EXTRA_LIBS})
|
||||
target_compile_options(${TEST_TARGET} PRIVATE ${GGML_EXTRA_FLAGS})
|
||||
add_test(NAME ${TEST_TARGET} COMMAND $<TARGET_FILE:${TEST_TARGET}>)
|
||||
endif()
|
||||
|
||||
|
|
@ -0,0 +1,265 @@
|
|||
#include "ggml.h"
|
||||
|
||||
#include <stdint.h>
|
||||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include <stdlib.h>
|
||||
#include <string.h>
|
||||
#include <time.h>
|
||||
#include <math.h>
|
||||
|
||||
#include <sys/time.h>
|
||||
|
||||
#include <arm_neon.h>
|
||||
|
||||
#include <Accelerate/Accelerate.h>
|
||||
|
||||
uint64_t get_time_us() {
|
||||
struct timeval tv;
|
||||
gettimeofday(&tv, NULL);
|
||||
return tv.tv_sec * 1000000 + tv.tv_usec;
|
||||
}
|
||||
|
||||
//
|
||||
// naive implementation
|
||||
//
|
||||
|
||||
void mul_mat_f32_0(
|
||||
const float * restrict src0, // M x K
|
||||
const float * restrict src1, // N x K (transposed)
|
||||
float * dst,
|
||||
int m, int n, int k) {
|
||||
for (int i = 0; i < m; i++) {
|
||||
for (int j = 0; j < n; j++) {
|
||||
float sum = 0;
|
||||
for (int l = 0; l < k; l++) {
|
||||
sum += src0[i*k + l] * src1[j*k + l];
|
||||
}
|
||||
dst[j*m + i] = sum;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
if (argc < 4) {
|
||||
printf("Usage: %s M N K\n", argv[0]);
|
||||
return 1;
|
||||
}
|
||||
|
||||
int M = atoi(argv[1]);
|
||||
int N = atoi(argv[2]);
|
||||
int K = atoi(argv[3]);
|
||||
|
||||
srand(time(NULL));
|
||||
|
||||
if (M == 0) M = rand() % 1000 + 1;
|
||||
if (N == 0) N = rand() % 1000 + 1;
|
||||
if (K == 0) K = rand() % 1000 + 1;
|
||||
|
||||
printf("M = %d, N = %d, K = %d\n", M, N, K);
|
||||
|
||||
float * src0 = malloc(sizeof(float)*M*K);
|
||||
float * src1 = malloc(sizeof(float)*N*K);
|
||||
float * dst0 = malloc(sizeof(float)*M*N); // naive
|
||||
float * dst1 = malloc(sizeof(float)*M*N); // blas
|
||||
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = 2048ul*1024*1024,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
|
||||
struct ggml_tensor * s0_f32 = ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, K, M);
|
||||
struct ggml_tensor * s1_f32 = ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, K, N);
|
||||
|
||||
struct ggml_tensor * s0_f16 = ggml_new_tensor_2d(ctx0, GGML_TYPE_F16, K, M);
|
||||
struct ggml_tensor * s1_f16 = ggml_new_tensor_2d(ctx0, GGML_TYPE_F16, K, N);
|
||||
|
||||
for (int j = 0; j < M; j++) {
|
||||
for (int i = 0; i < K; i++) {
|
||||
//src0[j*K + i] = j;
|
||||
src0[j*K + i] = 1e-3*(rand() % 1000);
|
||||
}
|
||||
}
|
||||
|
||||
for (int j = 0; j < N; j++) {
|
||||
for (int i = 0; i < K; i++) {
|
||||
//src1[j*K + i] = j + 1;
|
||||
src1[j*K + i] = 1e-3*(rand() % 1000);
|
||||
}
|
||||
}
|
||||
|
||||
// copy src0 to s0_f32
|
||||
{
|
||||
float * p_f32 = s0_f32->data;
|
||||
ggml_fp16_t * p_f16 = s0_f16->data;
|
||||
for (int i = 0; i < M; i++) {
|
||||
for (int j = 0; j < K; j++) {
|
||||
p_f32[i*K + j] = src0[i*K + j];
|
||||
p_f16[i*K + j] = ggml_fp32_to_fp16(src0[i*K + j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// copy src1 to s1_f32
|
||||
{
|
||||
float * p_f32 = s1_f32->data;
|
||||
ggml_fp16_t * p_f16 = s1_f16->data;
|
||||
for (int i = 0; i < N; i++) {
|
||||
for (int j = 0; j < K; j++) {
|
||||
p_f32[i*K + j] = src1[i*K + j];
|
||||
p_f16[i*K + j] = ggml_fp32_to_fp16(src1[i*K + j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const clock_t start = clock();
|
||||
const uint64_t start_us = get_time_us();
|
||||
|
||||
double iM = 1.0/M;
|
||||
mul_mat_f32_0(src0, src1, dst0, M, N, K);
|
||||
|
||||
// Use BLAS sgemm from Accelerate framework
|
||||
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasTrans, N, M, K, 1.0f, src1, K, src0, K, 0.0f, dst1, M);
|
||||
|
||||
struct ggml_tensor * dst2 = NULL;
|
||||
struct ggml_tensor * dst3 = NULL;
|
||||
|
||||
{
|
||||
dst2 = ggml_mul_mat(ctx0, s0_f32, s1_f32);
|
||||
|
||||
struct ggml_cgraph gf = ggml_build_forward(dst2);
|
||||
ggml_graph_compute(ctx0, &gf);
|
||||
}
|
||||
|
||||
{
|
||||
dst3 = ggml_mul_mat(ctx0, s0_f16, s1_f32);
|
||||
|
||||
struct ggml_cgraph gf = ggml_build_forward(dst3);
|
||||
ggml_graph_compute(ctx0, &gf);
|
||||
}
|
||||
|
||||
bool ok_blas = true;
|
||||
bool ok_ggml_f32 = true;
|
||||
bool ok_ggml_f16 = true;
|
||||
|
||||
// check BLAS
|
||||
for (int i = 0; i < M*N; i++) {
|
||||
if (fabs(dst0[i] - dst1[i])/fabs(dst0[i]) > 0.0001) {
|
||||
printf("dst0[%d] = %f, dst1[%d] = %f\n", i, dst0[i], i, dst1[i]);
|
||||
ok_blas = false;
|
||||
}
|
||||
}
|
||||
|
||||
// check ggml (f32)
|
||||
{
|
||||
float * p = dst2->data;
|
||||
for (int i = 0; i < M*N; i++) {
|
||||
if (fabs(dst0[i] - p[i])/fabs(dst0[i]) > 0.0001) {
|
||||
printf("dst0[%d] = %f, dst2[%d] = %f\n", i, dst0[i], i, p[i]);
|
||||
ok_ggml_f32 = false;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// check ggml (f16)
|
||||
{
|
||||
float * p = dst3->data;
|
||||
for (int i = 0; i < M*N; i++) {
|
||||
if (fabs(dst0[i] - p[i])/fabs(dst0[i]) > 0.01) {
|
||||
printf("dst0[%d] = %f, dst3[%d] = %f\n", i, dst0[i], i, p[i]);
|
||||
ok_ggml_f16 = false;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
{
|
||||
const clock_t end = clock();
|
||||
const uint64_t end_us = get_time_us();
|
||||
printf("%s: elapsed ticks: %ld\n", __func__, end - start);
|
||||
}
|
||||
|
||||
#if 0
|
||||
// print src0
|
||||
printf("src0:\n");
|
||||
for (int i = 0; i < M; i++) {
|
||||
for (int j = 0; j < K; j++) {
|
||||
printf("%4.1f ", src0[i*K+j]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
// print src1
|
||||
printf("src1:\n");
|
||||
for (int i = 0; i < N; i++) {
|
||||
for (int j = 0; j < K; j++) {
|
||||
printf("%4.1f ", src1[i*K+j]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
printf("\n");
|
||||
printf("dst0 (naive):\n");
|
||||
for (int j = 0; j < N; j++) {
|
||||
for (int i = 0; i < M; i++) {
|
||||
printf("%4.1f ", dst0[j*M+i]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
printf("\n");
|
||||
printf("dst1 (BLAS):\n");
|
||||
for (int j = 0; j < N; j++) {
|
||||
for (int i = 0; i < M; i++) {
|
||||
printf("%4.1f ", dst1[j*M+i]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
printf("\n");
|
||||
printf("dst2 (ggml f32):\n");
|
||||
for (int j = 0; j < N; j++) {
|
||||
for (int i = 0; i < M; i++) {
|
||||
printf("%4.1f ", ((float *)dst2->data)[j*M+i]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
printf("\n");
|
||||
printf("dst3 (ggml f16):\n");
|
||||
for (int j = 0; j < N; j++) {
|
||||
for (int i = 0; i < M; i++) {
|
||||
printf("%4.1f ", ((float *)dst3->data)[j*M+i]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
printf("\n");
|
||||
#endif
|
||||
|
||||
free(src0);
|
||||
free(src1);
|
||||
free(dst0);
|
||||
free(dst1);
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
printf("ok_blas = %d\n", ok_blas);
|
||||
if (!ok_blas) {
|
||||
printf("ERROR: BLAS failed\n");
|
||||
}
|
||||
|
||||
printf("ok_ggml_f32 = %d\n", ok_ggml_f32);
|
||||
if (!ok_ggml_f32) {
|
||||
printf("ERROR: ggml failed\n");
|
||||
}
|
||||
|
||||
printf("ok_ggml_f16 = %d\n", ok_ggml_f16);
|
||||
if (!ok_ggml_f16) {
|
||||
printf("ERROR: ggml failed\n");
|
||||
}
|
||||
|
||||
return (ok_blas && ok_ggml_f32 && ok_ggml_f16) ? 0 : 1;
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,327 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include <math.h>
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <assert.h>
|
||||
#include <inttypes.h>
|
||||
|
||||
#define MAX_NARGS 2
|
||||
|
||||
float frand() {
|
||||
return (float)rand()/(float)RAND_MAX;
|
||||
}
|
||||
|
||||
int irand(int n) {
|
||||
return rand()%n;
|
||||
}
|
||||
|
||||
void get_random_dims(int64_t * dims, int ndims) {
|
||||
dims[0] = dims[1] = dims[2] = dims[3] = 1;
|
||||
|
||||
for (int i = 0; i < ndims; i++) {
|
||||
dims[i] = 1 + irand(4);
|
||||
}
|
||||
}
|
||||
|
||||
struct ggml_tensor * get_random_tensor(
|
||||
struct ggml_context * ctx0,
|
||||
int ndims,
|
||||
int64_t ne[],
|
||||
float fmin,
|
||||
float fmax) {
|
||||
struct ggml_tensor * result = ggml_new_tensor(ctx0, GGML_TYPE_F32, ndims, ne);
|
||||
|
||||
switch (ndims) {
|
||||
case 1:
|
||||
for (int i0 = 0; i0 < ne[0]; i0++) {
|
||||
((float *)result->data)[i0] = frand()*(fmax - fmin) + fmin;
|
||||
}
|
||||
break;
|
||||
case 2:
|
||||
for (int i1 = 0; i1 < ne[1]; i1++) {
|
||||
for (int i0 = 0; i0 < ne[0]; i0++) {
|
||||
((float *)result->data)[i1*ne[0] + i0] = frand()*(fmax - fmin) + fmin;
|
||||
}
|
||||
}
|
||||
break;
|
||||
case 3:
|
||||
for (int i2 = 0; i2 < ne[2]; i2++) {
|
||||
for (int i1 = 0; i1 < ne[1]; i1++) {
|
||||
for (int i0 = 0; i0 < ne[0]; i0++) {
|
||||
((float *)result->data)[i2*ne[1]*ne[0] + i1*ne[0] + i0] = frand()*(fmax - fmin) + fmin;
|
||||
}
|
||||
}
|
||||
}
|
||||
break;
|
||||
case 4:
|
||||
for (int i3 = 0; i3 < ne[3]; i3++) {
|
||||
for (int i2 = 0; i2 < ne[2]; i2++) {
|
||||
for (int i1 = 0; i1 < ne[1]; i1++) {
|
||||
for (int i0 = 0; i0 < ne[0]; i0++) {
|
||||
((float *)result->data)[i3*ne[2]*ne[1]*ne[0] + i2*ne[1]*ne[0] + i1*ne[0] + i0] = frand()*(fmax - fmin) + fmin;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
break;
|
||||
default:
|
||||
assert(false);
|
||||
};
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
float get_element(const struct ggml_tensor * t, int idx) {
|
||||
return ((float *)t->data)[idx];
|
||||
}
|
||||
|
||||
void set_element(struct ggml_tensor * t, int idx, float value) {
|
||||
((float *)t->data)[idx] = value;
|
||||
}
|
||||
|
||||
bool check_gradient(
|
||||
const char * op_name,
|
||||
struct ggml_context * ctx0,
|
||||
struct ggml_tensor * x[],
|
||||
struct ggml_tensor * f,
|
||||
int ndims,
|
||||
int nargs,
|
||||
float eps,
|
||||
float max_error_abs,
|
||||
float max_error_rel) {
|
||||
|
||||
struct ggml_cgraph gf = ggml_build_forward (f);
|
||||
struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);
|
||||
|
||||
ggml_graph_compute(ctx0, &gf);
|
||||
ggml_graph_reset (&gf);
|
||||
ggml_set_f32 (f->grad, 1.0f);
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
ggml_graph_dump_dot(&gf, NULL, "test-grad0-forward.dot");
|
||||
ggml_graph_dump_dot(&gb, &gf, "test-grad0-backward.dot");
|
||||
|
||||
for (int i = 0; i < nargs; ++i) {
|
||||
const int64_t nelements = ggml_nelements(x[i]);
|
||||
for (int64_t k = 0; k < nelements; ++k) {
|
||||
// compute gradient using finite differences
|
||||
const float x0 = get_element(x[i], k);
|
||||
|
||||
set_element(x[i], k, x0 + eps);
|
||||
ggml_graph_compute(ctx0, &gf);
|
||||
|
||||
const float f0 = ggml_get_f32_1d(f, 0);
|
||||
|
||||
set_element(x[i], k, x0 - eps);
|
||||
ggml_graph_compute(ctx0, &gf);
|
||||
|
||||
const float f1 = ggml_get_f32_1d(f, 0);
|
||||
|
||||
const float g0 = (f0 - f1)/(2.0f*eps);
|
||||
|
||||
set_element(x[i], k, x0);
|
||||
|
||||
// compute gradient using backward graph
|
||||
ggml_graph_reset (&gf);
|
||||
ggml_set_f32 (f->grad, 1.0f);
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
const float g1 = get_element(x[i]->grad, k);
|
||||
|
||||
const float error_abs = fabsf(g0 - g1);
|
||||
const float error_rel = g0 != 0 ? fabsf(g0 - g1)/fabs(g0) : 0;
|
||||
|
||||
if (error_abs > max_error_abs || error_rel > max_error_rel) {
|
||||
printf("%s: ndims=%d, i=%d, k=%" PRId64 ", g0=%f, g1=%f, error_abs=%f, error_rel=%f\n", op_name, ndims, i, k, g0, g1, error_abs, error_rel);
|
||||
assert(false);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
|
||||
float mat_get(const struct ggml_tensor * t, int i0, int i1, int i2, int i3) {
|
||||
const size_t nb0 = t->nb[0];
|
||||
const size_t nb1 = t->nb[1];
|
||||
const size_t nb2 = t->nb[2];
|
||||
const size_t nb3 = t->nb[3];
|
||||
|
||||
return
|
||||
*((float*) ((char*)t->data + i0*nb0 + i1*nb1 + i2*nb2 + i3*nb3));
|
||||
}
|
||||
|
||||
bool check_mat_mul(
|
||||
const struct ggml_tensor * y,
|
||||
const struct ggml_tensor * x0,
|
||||
const struct ggml_tensor * x1) {
|
||||
float * dst = (float *) y->data;
|
||||
float * src0 = (float *) x0->data;
|
||||
float * src1 = (float *) x1->data;
|
||||
|
||||
const int64_t n00 = x0->ne[0];
|
||||
const int64_t n10 = x0->ne[1];
|
||||
const int64_t n20 = x0->ne[2];
|
||||
const int64_t n30 = x0->ne[3];
|
||||
|
||||
const int64_t n01 = x1->ne[0];
|
||||
const int64_t n11 = x1->ne[1];
|
||||
const int64_t n21 = x1->ne[2];
|
||||
const int64_t n31 = x1->ne[3];
|
||||
|
||||
const int64_t n02 = y->ne[0];
|
||||
const int64_t n12 = y->ne[1];
|
||||
const int64_t n22 = y->ne[2];
|
||||
const int64_t n32 = y->ne[3];
|
||||
|
||||
printf("x0: [%" PRId64 ", %" PRId64 ", %" PRId64 ", %" PRId64 "]\n", n00, n10, n20, n30);
|
||||
for (int j = 0; j < n10; ++j) {
|
||||
for (int i = 0; i < n00; ++i) {
|
||||
printf("%6.3f ", mat_get(x0, i, j, 0, 0));
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
printf("x1: [%" PRId64 ", %" PRId64 ", %" PRId64 ", %" PRId64 "]\n", n01, n11, n21, n31);
|
||||
for (int j = 0; j < n11; ++j) {
|
||||
for (int i = 0; i < n01; ++i) {
|
||||
printf("%6.3f ", mat_get(x1, i, j, 0, 0));
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
printf("y: [%" PRId64 ", %" PRId64 ", %" PRId64 ", %" PRId64 "]\n", n02, n12, n22, n32);
|
||||
for (int j = 0; j < n12; ++j) {
|
||||
for (int i = 0; i < n02; ++i) {
|
||||
printf("%6.3f ", mat_get(y, i, j, 0, 0));
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
for (int i3 = 0; i3 < n32; ++i3) {
|
||||
for (int i2 = 0; i2 < n22; ++i2) {
|
||||
for (int i1 = 0; i1 < n12; ++i1) {
|
||||
for (int i0 = 0; i0 < n02; ++i0) {
|
||||
float sum = 0.0f;
|
||||
for (int k = 0; k < n00; ++k) {
|
||||
sum += mat_get(x0, k, i0, i2, i3) * mat_get(x1, k, i1, i2, i3);
|
||||
}
|
||||
if (fabsf(sum - mat_get(y, i0, i1, i2, i3)) > 1e-5) {
|
||||
printf("error: i0=%d, i1=%d, i2=%d, i3=%d, sum=%f, y=%f\n",
|
||||
i0, i1, i2, i3, sum, mat_get(y, i0, i1, i2, i3));
|
||||
assert(false);
|
||||
return false;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = 128*1024*1024,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
int64_t ne[4];
|
||||
|
||||
// original loop: 500
|
||||
int niter = 500;
|
||||
const char *env = getenv("GGML_NLOOP");
|
||||
if (env != NULL) {
|
||||
niter = atoi(env);
|
||||
}
|
||||
if (argc > 1) {
|
||||
niter = atoi(argv[1]);
|
||||
}
|
||||
for (int iter = 0; iter < niter; ++iter) {
|
||||
printf("test-mul-mat0: iter:%d/%d\n", iter, niter);
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
|
||||
get_random_dims(ne, 4);
|
||||
|
||||
struct ggml_tensor * x[MAX_NARGS];
|
||||
|
||||
// mul_mat
|
||||
{
|
||||
const int nargs = 1;
|
||||
|
||||
for (int ndims = 2; ndims <= 4; ++ndims) {
|
||||
x[0] = get_random_tensor(ctx0, ndims, ne, -1.0f, 1.0f);
|
||||
ne[1] = rand()%4 + 1;
|
||||
x[1] = get_random_tensor(ctx0, ndims, ne, -1.0f, 1.0f);
|
||||
|
||||
ggml_set_param(ctx0, x[0]);
|
||||
|
||||
struct ggml_tensor * m = ggml_mul_mat(ctx0, x[1], x[0]);
|
||||
struct ggml_tensor * f = ggml_sum(ctx0, m);
|
||||
|
||||
printf("testing: mul_mat, [%" PRId64 ", %" PRId64 ", %" PRId64 ", %" PRId64 "] = [%" PRId64 ", %" PRId64 ", %" PRId64 ", %" PRId64 "] * [%" PRId64 ", %" PRId64 ", %" PRId64 ", %" PRId64 "]\n",
|
||||
m->ne[0], m->ne[1], m->ne[2], m->ne[3],
|
||||
x[1]->ne[0], x[1]->ne[1], x[1]->ne[2], x[1]->ne[3],
|
||||
x[0]->ne[0], x[0]->ne[1], x[0]->ne[2], x[0]->ne[3]);
|
||||
|
||||
assert(m->ne[0] == x[1]->ne[1]);
|
||||
assert(m->ne[1] == x[0]->ne[1]);
|
||||
assert(m->ne[2] == x[0]->ne[2]);
|
||||
assert(m->ne[3] == x[0]->ne[3]);
|
||||
|
||||
if (ndims <= 2) {
|
||||
check_gradient("mul_mat", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
|
||||
} else {
|
||||
struct ggml_cgraph gf = ggml_build_forward(m);
|
||||
ggml_graph_compute(ctx0, &gf);
|
||||
}
|
||||
|
||||
check_mat_mul(m, x[1], x[0]);
|
||||
}
|
||||
}
|
||||
|
||||
// mul_mat (transposed)
|
||||
{
|
||||
const int nargs = 1;
|
||||
|
||||
for (int ndims = 2; ndims <= 4; ++ndims) {
|
||||
x[0] = get_random_tensor(ctx0, ndims, ne, -1.0f, 1.0f);
|
||||
ne[1] = ne[0];
|
||||
ne[0] = rand()%4 + 1;
|
||||
x[1] = ggml_cont(ctx0, ggml_transpose(ctx0, get_random_tensor(ctx0, ndims, ne, -1.0f, 1.0f)));
|
||||
|
||||
ggml_set_param(ctx0, x[0]);
|
||||
|
||||
struct ggml_tensor * m = ggml_mul_mat(ctx0, x[1], x[0]);
|
||||
struct ggml_tensor * f = ggml_sum(ctx0, m);
|
||||
|
||||
printf("testing: mul_mat, [%" PRId64 ", %" PRId64 ", %" PRId64 ", %" PRId64 "] = [%" PRId64 ", %" PRId64 ", %" PRId64 ", %" PRId64 "] * [%" PRId64 ", %" PRId64 ", %" PRId64 ", %" PRId64 "]\n",
|
||||
m->ne[0], m->ne[1], m->ne[2], m->ne[3],
|
||||
x[1]->ne[0], x[1]->ne[1], x[1]->ne[2], x[1]->ne[3],
|
||||
x[0]->ne[0], x[0]->ne[1], x[0]->ne[2], x[0]->ne[3]);
|
||||
|
||||
assert(m->ne[0] == x[1]->ne[1]);
|
||||
assert(m->ne[1] == x[0]->ne[1]);
|
||||
assert(m->ne[2] == x[0]->ne[2]);
|
||||
assert(m->ne[3] == x[0]->ne[3]);
|
||||
|
||||
if (ndims <= 2) {
|
||||
check_gradient("mul_mat", ctx0, x, f, ndims, nargs, 1e-3f, 1e-3f, INFINITY);
|
||||
} else {
|
||||
struct ggml_cgraph gf = ggml_build_forward(m);
|
||||
ggml_graph_compute(ctx0, &gf);
|
||||
}
|
||||
|
||||
check_mat_mul(m, x[1], x[0]);
|
||||
}
|
||||
}
|
||||
ggml_free(ctx0);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,312 @@
|
|||
#include <stdint.h>
|
||||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include <stdlib.h>
|
||||
#include <string.h>
|
||||
#include <time.h>
|
||||
#include <math.h>
|
||||
|
||||
#include <sys/time.h>
|
||||
|
||||
#include <arm_neon.h>
|
||||
|
||||
#include <Accelerate/Accelerate.h>
|
||||
|
||||
const int M = 1280;
|
||||
const int N = 1536;
|
||||
const int K = 1280;
|
||||
|
||||
uint64_t get_time_us() {
|
||||
struct timeval tv;
|
||||
gettimeofday(&tv, NULL);
|
||||
return tv.tv_sec * 1000000 + tv.tv_usec;
|
||||
}
|
||||
|
||||
//
|
||||
// naive implementation
|
||||
//
|
||||
|
||||
void mul_mat_f32_0(
|
||||
const float * restrict src0, // M x K
|
||||
const float * restrict src1, // N x K (transposed)
|
||||
float * dst,
|
||||
int m, int n, int k) {
|
||||
for (int i = 0; i < m; i++) {
|
||||
for (int j = 0; j < n; j++) {
|
||||
float sum = 0;
|
||||
for (int l = 0; l < k; l++) {
|
||||
sum += src0[i*k + l] * src1[j*k + l];
|
||||
}
|
||||
dst[i*n + j] = sum;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void mul_mat_f16_0(
|
||||
const __fp16 * src0,
|
||||
const __fp16 * src1,
|
||||
float * dst,
|
||||
int m, int n, int k) {
|
||||
const int k32 = k & ~31;
|
||||
|
||||
for (int i = 0; i < m; i++) {
|
||||
for (int j = 0; j < n; j++) {
|
||||
float sumf = 0.0;
|
||||
|
||||
float16x8_t sum0 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum1 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum2 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum3 = vdupq_n_f16(0.0f);
|
||||
|
||||
float16x8_t x0, x1, x2, x3;
|
||||
float16x8_t y0, y1, y2, y3;
|
||||
|
||||
const __fp16 * restrict p0 = src0 + i*k;
|
||||
const __fp16 * restrict p1 = src1 + j*k;
|
||||
|
||||
for (int l = 0; l < k32; l += 32) {
|
||||
x0 = vld1q_f16(p0 + l + 0 );
|
||||
x1 = vld1q_f16(p0 + l + 8 );
|
||||
x2 = vld1q_f16(p0 + l + 16);
|
||||
x3 = vld1q_f16(p0 + l + 24);
|
||||
|
||||
y0 = vld1q_f16(p1 + l + 0 );
|
||||
y1 = vld1q_f16(p1 + l + 8 );
|
||||
y2 = vld1q_f16(p1 + l + 16);
|
||||
y3 = vld1q_f16(p1 + l + 24);
|
||||
|
||||
sum0 = vfmaq_f16(sum0, x0, y0);
|
||||
sum1 = vfmaq_f16(sum1, x1, y1);
|
||||
sum2 = vfmaq_f16(sum2, x2, y2);
|
||||
sum3 = vfmaq_f16(sum3, x3, y3);
|
||||
}
|
||||
|
||||
// reduce sum0..sum3 to sum0
|
||||
sum0 = vaddq_f16(sum0, sum1);
|
||||
sum2 = vaddq_f16(sum2, sum3);
|
||||
sum0 = vaddq_f16(sum0, sum2);
|
||||
|
||||
// load sum0 into 2 float32x4_t
|
||||
float32x4_t sum0f32 = vcvt_f32_f16(vget_low_f16(sum0));
|
||||
float32x4_t sum1f32 = vcvt_f32_f16(vget_high_f16(sum0));
|
||||
|
||||
// reduce sum0f32 and sum1f32 to sumf
|
||||
sum0f32 = vaddq_f32(sum0f32, sum1f32);
|
||||
|
||||
float32x2_t sumf32 = vadd_f32(vget_low_f32(sum0f32), vget_high_f32(sum0f32));
|
||||
sumf = vget_lane_f32(sumf32, 0) + vget_lane_f32(sumf32, 1);
|
||||
|
||||
//sumf = sum0[0] + sum0[1] + sum0[2] + sum0[3] + sum0[4] + sum0[5] + sum0[6] + sum0[7];
|
||||
|
||||
for (int l = k32; l < k32; l++) {
|
||||
sumf += p0[l]*p1[l];
|
||||
}
|
||||
|
||||
dst[i*n + j] = sumf;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// blocking with block size 32
|
||||
void mul_mat_f16_1(
|
||||
const __fp16 * src0,
|
||||
const __fp16 * src1,
|
||||
float * dst,
|
||||
int m, int n, int k) {
|
||||
|
||||
const int k32 = k & ~31;
|
||||
const int bs = 32;
|
||||
|
||||
memset(dst, 0, m*n*sizeof(float));
|
||||
|
||||
for (int i = 0; i < m; i += bs) {
|
||||
for (int j = 0; j < n; j += bs) {
|
||||
for (int l = 0; l < k; l += bs) {
|
||||
for (int ii = i; ii < i + bs; ii++) {
|
||||
const __fp16 * restrict p0 = src0 + ii*k;
|
||||
|
||||
float16x8_t x0, x1, x2, x3;
|
||||
|
||||
x0 = vld1q_f16(p0 + l + 0 );
|
||||
x1 = vld1q_f16(p0 + l + 8 );
|
||||
x2 = vld1q_f16(p0 + l + 16);
|
||||
x3 = vld1q_f16(p0 + l + 24);
|
||||
|
||||
for (int jj = j; jj < j + bs; jj++) {
|
||||
float sumf = 0.0;
|
||||
|
||||
float16x8_t sum0 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum1 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum2 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum3 = vdupq_n_f16(0.0f);
|
||||
|
||||
float16x8_t y0, y1, y2, y3;
|
||||
|
||||
const __fp16 * restrict p1 = src1 + jj*k;
|
||||
|
||||
y0 = vld1q_f16(p1 + l + 0 );
|
||||
y1 = vld1q_f16(p1 + l + 8 );
|
||||
y2 = vld1q_f16(p1 + l + 16);
|
||||
y3 = vld1q_f16(p1 + l + 24);
|
||||
|
||||
sum0 = vfmaq_f16(sum0, x0, y0);
|
||||
sum1 = vfmaq_f16(sum1, x1, y1);
|
||||
sum2 = vfmaq_f16(sum2, x2, y2);
|
||||
sum3 = vfmaq_f16(sum3, x3, y3);
|
||||
|
||||
// reduce sum0..sum3 to sum0
|
||||
sum0 = vaddq_f16(sum0, sum1);
|
||||
sum2 = vaddq_f16(sum2, sum3);
|
||||
sum0 = vaddq_f16(sum0, sum2);
|
||||
|
||||
// load sum0 into 2 float32x4_t
|
||||
float32x4_t sum0f32 = vcvt_f32_f16(vget_low_f16(sum0));
|
||||
float32x4_t sum1f32 = vcvt_f32_f16(vget_high_f16(sum0));
|
||||
|
||||
// reduce sum0f32 and sum1f32 to sumf
|
||||
sum0f32 = vaddq_f32(sum0f32, sum1f32);
|
||||
|
||||
float32x2_t sumf32 = vadd_f32(vget_low_f32(sum0f32), vget_high_f32(sum0f32));
|
||||
sumf = vget_lane_f32(sumf32, 0) + vget_lane_f32(sumf32, 1);
|
||||
|
||||
//sumf = sum0[0] + sum0[1] + sum0[2] + sum0[3] + sum0[4] + sum0[5] + sum0[6] + sum0[7];
|
||||
|
||||
dst[ii*n + jj] += sumf;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
void mul_mat_f8_0(
|
||||
const uint8_t * src0,
|
||||
const uint8_t * src1,
|
||||
float * dst,
|
||||
int m, int n, int k) {
|
||||
const int k32 = k & ~31;
|
||||
|
||||
for (int i = 0; i < m; i++) {
|
||||
for (int j = 0; j < n; j++) {
|
||||
float sumf = 0.0;
|
||||
|
||||
const uint8_t * restrict p0 = src0 + i*k;
|
||||
const uint8_t * restrict p1 = src1 + j*k;
|
||||
|
||||
for (int l = 0; l < k32; l += 32) {
|
||||
uint8x16_t x0 = vld1q_u8(p0 + l + 0 );
|
||||
uint8x16_t x1 = vld1q_u8(p0 + l + 16);
|
||||
|
||||
uint8x16_t y0 = vld1q_u8(p1 + l + 0 );
|
||||
uint8x16_t y1 = vld1q_u8(p1 + l + 16);
|
||||
|
||||
x0 = vmulq_u8(x0, y0);
|
||||
x1 = vmulq_u8(x1, y1);
|
||||
|
||||
sumf += vaddvq_u8(x0) + vaddvq_u8(x1);
|
||||
}
|
||||
|
||||
dst[i*n + j] = sumf;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
float * src0 = malloc(sizeof(float)*M*K);
|
||||
float * src1 = malloc(sizeof(float)*N*K);
|
||||
float * dst = malloc(sizeof(float)*M*N);
|
||||
|
||||
for (int i = 0; i < M*K; i++) {
|
||||
src0[i] = rand() / (float)RAND_MAX;
|
||||
}
|
||||
|
||||
for (int i = 0; i < N*K; i++) {
|
||||
src1[i] = rand() / (float)RAND_MAX;
|
||||
}
|
||||
|
||||
// convert src0 and src1 to __fp16
|
||||
__fp16 * src0_fp16 = (__fp16 *)(malloc(sizeof(__fp16)*M*K));
|
||||
__fp16 * src1_fp16 = (__fp16 *)(malloc(sizeof(__fp16)*N*K));
|
||||
|
||||
uint8_t * src0_fp8 = (uint8_t *)(malloc(sizeof(__fp16)*M*K));
|
||||
uint8_t * src1_fp8 = (uint8_t *)(malloc(sizeof(__fp16)*N*K));
|
||||
|
||||
{
|
||||
const uint64_t t_start = get_time_us();
|
||||
|
||||
for (int i = 0; i < M*K; i++) {
|
||||
src0_fp16[i] = src0[i];
|
||||
//printf("%f %f\n", src0[i], src0_fp16[i]);
|
||||
//assert(!isnan(src0_fp16[i]));
|
||||
}
|
||||
|
||||
for (int i = 0; i < N*K; i++) {
|
||||
src1_fp16[i] = src1[i];
|
||||
}
|
||||
|
||||
const uint64_t t_end = get_time_us();
|
||||
printf("convert time: %f ms\n", (t_end - t_start) / 1000.0);
|
||||
}
|
||||
|
||||
for (int i = 0; i < 16; ++i) {
|
||||
printf("%f %f\n", src0[i], src0_fp16[i]);
|
||||
}
|
||||
|
||||
int method = 0;
|
||||
if (argc > 1) {
|
||||
method = atoi(argv[1]);
|
||||
}
|
||||
|
||||
const int nIter = 1;
|
||||
|
||||
const clock_t start = clock();
|
||||
const uint64_t start_us = get_time_us();
|
||||
|
||||
double iM = 1.0/M;
|
||||
double sum = 0.0f;
|
||||
for (int i = 0; i < nIter; i++) {
|
||||
if (method == 0) {
|
||||
mul_mat_f32_0(src0, src1, dst, M, N, K);
|
||||
}
|
||||
|
||||
if (method == 1) {
|
||||
mul_mat_f16_0(src0_fp16, src1_fp16, dst, M, N, K);
|
||||
}
|
||||
|
||||
if (method == 2) {
|
||||
mul_mat_f16_1(src0_fp16, src1_fp16, dst, M, N, K);
|
||||
}
|
||||
|
||||
if (method == 3) {
|
||||
mul_mat_f8_0(src0_fp8, src1_fp8, dst, M, N, K);
|
||||
}
|
||||
|
||||
if (method == 4) {
|
||||
// Use BLAS sgemm from Accelerate framework
|
||||
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasTrans, M, N, K, 1.0f, src0, K, src1, K, 0.0f, dst, N);
|
||||
}
|
||||
}
|
||||
|
||||
for (int i = 0; i < N; i++) {
|
||||
sum += dst[i]*iM;
|
||||
}
|
||||
|
||||
{
|
||||
const clock_t end = clock();
|
||||
const uint64_t end_us = get_time_us();
|
||||
printf("%s: elapsed ticks: %ld\n", __func__, end - start);
|
||||
printf("%s: elapsed us: %llu / %f ms\n", __func__, end_us - start_us, (end_us - start_us) / 1000.0 / nIter);
|
||||
}
|
||||
|
||||
printf("%f\n", sum);
|
||||
|
||||
free(src0);
|
||||
free(src1);
|
||||
free(dst);
|
||||
|
||||
free(src0_fp16);
|
||||
free(src1_fp16);
|
||||
|
||||
return 0;
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,205 @@
|
|||
#include "ggml.h"
|
||||
|
||||
#include <math.h>
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <assert.h>
|
||||
|
||||
#define MAX_NARGS 2
|
||||
|
||||
|
||||
//
|
||||
// logging
|
||||
//
|
||||
#define GGML_DEBUG 0
|
||||
#if (GGML_DEBUG >= 1)
|
||||
#define GGML_PRINT_DEBUG(...) printf(__VA_ARGS__)
|
||||
#else
|
||||
#define GGML_PRINT_DEBUG(...)
|
||||
#endif
|
||||
|
||||
#if (GGML_DEBUG >= 5)
|
||||
#define GGML_PRINT_DEBUG_5(...) printf(__VA_ARGS__)
|
||||
#else
|
||||
#define GGML_PRINT_DEBUG_5(...)
|
||||
#endif
|
||||
|
||||
#if (GGML_DEBUG >= 10)
|
||||
#define GGML_PRINT_DEBUG_10(...) printf(__VA_ARGS__)
|
||||
#else
|
||||
#define GGML_PRINT_DEBUG_10(...)
|
||||
#endif
|
||||
|
||||
#define GGML_PRINT(...) printf(__VA_ARGS__)
|
||||
|
||||
|
||||
float frand() {
|
||||
return (float)rand()/(float)RAND_MAX;
|
||||
}
|
||||
|
||||
int irand(int n) {
|
||||
return rand()%n;
|
||||
}
|
||||
|
||||
void get_random_dims(int64_t * dims, int ndims) {
|
||||
dims[0] = dims[1] = dims[2] = dims[3] = 1;
|
||||
|
||||
for (int i = 0; i < ndims; i++) {
|
||||
dims[i] = 1 + irand(4);
|
||||
}
|
||||
}
|
||||
|
||||
void get_random_dims_minmax(int64_t * dims, int ndims, int min, int max) {
|
||||
dims[0] = dims[1] = dims[2] = dims[3] = 1;
|
||||
|
||||
for (int i = 0; i < ndims; i++) {
|
||||
dims[i] = min + irand(max-min);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
struct ggml_tensor * get_random_tensor(
|
||||
struct ggml_context * ctx0,
|
||||
int ndims,
|
||||
int64_t ne[],
|
||||
float fmin,
|
||||
float fmax) {
|
||||
struct ggml_tensor * result = ggml_new_tensor(ctx0, GGML_TYPE_F32, ndims, ne);
|
||||
|
||||
switch (ndims) {
|
||||
case 1:
|
||||
for (int i0 = 0; i0 < ne[0]; i0++) {
|
||||
((float *)result->data)[i0] = frand()*(fmax - fmin) + fmin;
|
||||
}
|
||||
break;
|
||||
case 2:
|
||||
for (int i1 = 0; i1 < ne[1]; i1++) {
|
||||
for (int i0 = 0; i0 < ne[0]; i0++) {
|
||||
((float *)result->data)[i1*ne[0] + i0] = frand()*(fmax - fmin) + fmin;
|
||||
}
|
||||
}
|
||||
break;
|
||||
case 3:
|
||||
for (int i2 = 0; i2 < ne[2]; i2++) {
|
||||
for (int i1 = 0; i1 < ne[1]; i1++) {
|
||||
for (int i0 = 0; i0 < ne[0]; i0++) {
|
||||
((float *)result->data)[i2*ne[1]*ne[0] + i1*ne[0] + i0] = frand()*(fmax - fmin) + fmin;
|
||||
}
|
||||
}
|
||||
}
|
||||
break;
|
||||
case 4:
|
||||
for (int i3 = 0; i3 < ne[3]; i3++) {
|
||||
for (int i2 = 0; i2 < ne[2]; i2++) {
|
||||
for (int i1 = 0; i1 < ne[1]; i1++) {
|
||||
for (int i0 = 0; i0 < ne[0]; i0++) {
|
||||
((float *)result->data)[i3*ne[2]*ne[1]*ne[0] + i2*ne[1]*ne[0] + i1*ne[0] + i0] = frand()*(fmax - fmin) + fmin;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
break;
|
||||
default:
|
||||
assert(false);
|
||||
};
|
||||
|
||||
return result;
|
||||
}
|
||||
|
||||
float get_element(const struct ggml_tensor * t, int idx) {
|
||||
return ((float *)t->data)[idx];
|
||||
}
|
||||
|
||||
void set_element(struct ggml_tensor * t, int idx, float value) {
|
||||
((float *)t->data)[idx] = value;
|
||||
}
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = 1024*1024*1024,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
struct ggml_context * ctx = ggml_init(params);
|
||||
|
||||
int64_t ne1[4] = {4, 1024, 1, 1};
|
||||
int64_t ne2[4] = {4, 2048, 1, 1};;
|
||||
int64_t ne3[4] = {1024, 2048, 1, 1};
|
||||
|
||||
struct ggml_tensor * a = get_random_tensor(ctx, 2, ne1, -1, +1);
|
||||
struct ggml_tensor * b = get_random_tensor(ctx, 2, ne2, -1, +1);
|
||||
ggml_set_param(ctx, a);
|
||||
ggml_set_param(ctx, b);
|
||||
|
||||
struct ggml_tensor * c = get_random_tensor(ctx, 2, ne3, -1, +1);
|
||||
|
||||
struct ggml_tensor * ab = ggml_mul_mat(ctx, a, b);
|
||||
struct ggml_tensor * d = ggml_sub(ctx, c, ab);
|
||||
struct ggml_tensor * e = ggml_sum(ctx, ggml_sqr(ctx, d));
|
||||
|
||||
|
||||
struct ggml_cgraph ge = ggml_build_forward(e);
|
||||
ggml_graph_reset (&ge);
|
||||
ggml_graph_compute(ctx, &ge);
|
||||
const float fe = ggml_get_f32_1d(e, 0);
|
||||
printf("%s: e = %.4f\n", __func__, fe);
|
||||
|
||||
struct ggml_opt_params opt_params = ggml_opt_default_params(GGML_OPT_ADAM);
|
||||
|
||||
ggml_opt(ctx, opt_params, e);
|
||||
|
||||
ggml_graph_reset (&ge);
|
||||
ggml_graph_compute(ctx, &ge);
|
||||
const float fe_opt = ggml_get_f32_1d(e, 0);
|
||||
printf("%s: original e = %.4f\n", __func__, fe);
|
||||
printf("%s: optimized e = %.4f\n", __func__, fe_opt);
|
||||
|
||||
const bool success = (fe_opt <= fe);
|
||||
assert(success);
|
||||
|
||||
ggml_free(ctx);
|
||||
return success ? 0 : -1;
|
||||
}
|
||||
// int64_t ne1[4] = {4, 128, 1, 1};
|
||||
// int64_t ne2[4] = {4, 256, 1, 1};;
|
||||
// int64_t ne3[4] = {128, 256, 1, 1};
|
||||
// main: original e = 25890.9375
|
||||
// main: optimized e = 10094.7031
|
||||
|
||||
// int64_t ne1[4] = {8, 128, 1, 1};
|
||||
// int64_t ne2[4] = {8, 256, 1, 1};;
|
||||
// int64_t ne3[4] = {128, 256, 1, 1};
|
||||
// main: original e = 39429.5078
|
||||
// main: optimized e = 9275.8936
|
||||
|
||||
// int64_t ne1[4] = {16, 128, 1, 1};
|
||||
// int64_t ne2[4] = {16, 256, 1, 1};;
|
||||
// int64_t ne3[4] = {128, 256, 1, 1};
|
||||
// main: original e = 68371.1328
|
||||
// main: optimized e = 7854.4502
|
||||
|
||||
|
||||
// int64_t ne1[4] = {32, 128, 1, 1};
|
||||
// int64_t ne2[4] = {32, 256, 1, 1};;
|
||||
// int64_t ne3[4] = {128, 256, 1, 1};
|
||||
// main: original e = 126061.1953
|
||||
// main: optimized e = 5451.0166
|
||||
|
||||
// int64_t ne1[4] = {4, 1024, 1, 1};
|
||||
// int64_t ne2[4] = {4, 2048, 1, 1};;
|
||||
// int64_t ne3[4] = {1024, 2048, 1, 1};
|
||||
// main: original e = 1620817.8750
|
||||
// main: optimized e = 698387.6875
|
||||
|
||||
// another run on M1
|
||||
// int64_t ne1[4] = {4, 1024, 1, 1};
|
||||
// int64_t ne2[4] = {4, 2048, 1, 1};;
|
||||
// int64_t ne3[4] = {1024, 2048, 1, 1};
|
||||
// main: original e = 1629595.6250
|
||||
// main: optimized e = 698169.1250
|
||||
|
||||
// int64_t ne1[4] = {32, 1024, 1, 1};
|
||||
// int64_t ne2[4] = {32, 2048, 1, 1};;
|
||||
// int64_t ne3[4] = {1024, 2048, 1, 1};
|
||||
// main: original e = 8146770.5000
|
||||
// main: optimized e = 651119.1250
|
||||
|
|
@ -0,0 +1,218 @@
|
|||
// SVD dimensionality reduction
|
||||
|
||||
#include <float.h>
|
||||
#include <stdint.h>
|
||||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include <stdlib.h>
|
||||
#include <string.h>
|
||||
#include <time.h>
|
||||
#include <math.h>
|
||||
|
||||
#include <sys/time.h>
|
||||
|
||||
#ifdef GGML_USE_ACCELERATE
|
||||
#include <Accelerate/Accelerate.h>
|
||||
#endif
|
||||
|
||||
float frand() {
|
||||
return (float) rand() / (float) RAND_MAX;
|
||||
}
|
||||
|
||||
//int sgesvd_(char *__jobu, char *__jobvt, __CLPK_integer *__m,
|
||||
// __CLPK_integer *__n, __CLPK_real *__a, __CLPK_integer *__lda,
|
||||
// __CLPK_real *__s, __CLPK_real *__u, __CLPK_integer *__ldu,
|
||||
// __CLPK_real *__vt, __CLPK_integer *__ldvt, __CLPK_real *__work,
|
||||
// __CLPK_integer *__lwork,
|
||||
// __CLPK_integer *__info)
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
int m = 10;
|
||||
int n = 5;
|
||||
|
||||
float * A = malloc(n * m * sizeof(float));
|
||||
float * A0 = malloc(n * m * sizeof(float));
|
||||
|
||||
for (int i = 0; i < n; ++i) {
|
||||
for (int j = 0; j < m; ++j) {
|
||||
A[i * m + j] = (float) (10.0f*(i + 1) + 1.0f * frand());
|
||||
//A[i * m + j] = (float) (10.0f*(i%2 + 1) + 0.1f * frand());
|
||||
//if (i == 2) {
|
||||
// A[i * m + j] += 20*frand();
|
||||
//}
|
||||
if ((i == 1 || i == 3) && j > m/2) {
|
||||
A[i * m + j] = -A[i * m + j];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// average vector
|
||||
//float * M = malloc(m * sizeof(float));
|
||||
|
||||
//{
|
||||
// for (int j = 0; j < m; ++j) {
|
||||
// M[j] = 0.0f;
|
||||
// }
|
||||
// for (int i = 0; i < n; ++i) {
|
||||
// for (int j = 0; j < m; ++j) {
|
||||
// M[j] += A[i * m + j];
|
||||
// }
|
||||
// }
|
||||
// for (int j = 0; j < m; ++j) {
|
||||
// M[j] /= (float) n;
|
||||
// }
|
||||
//}
|
||||
|
||||
//// subtract average vector
|
||||
//for (int i = 0; i < n; ++i) {
|
||||
// for (int j = 0; j < m; ++j) {
|
||||
// A[i * m + j] -= M[j];
|
||||
// }
|
||||
//}
|
||||
|
||||
memcpy(A0, A, n * m * sizeof(float));
|
||||
|
||||
// print A
|
||||
printf("A:\n");
|
||||
for (int i = 0; i < n; ++i) {
|
||||
printf("col %d : ", i);
|
||||
for (int j = 0; j < m; ++j) {
|
||||
printf("%9.5f ", A[i * m + j]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
// SVD
|
||||
// A = U * S * V^T
|
||||
|
||||
float * U = malloc(n * m * sizeof(float));
|
||||
float * S = malloc(n * sizeof(float));
|
||||
float * V = malloc(n * n * sizeof(float));
|
||||
|
||||
int lda = m;
|
||||
int ldu = m;
|
||||
int ldvt = n;
|
||||
|
||||
float work_size;
|
||||
int lwork = -1;
|
||||
int info = 0;
|
||||
|
||||
sgesvd_("S", "S", &m, &n, A, &lda, S, U, &ldu, V, &ldvt, &work_size, &lwork, &info);
|
||||
|
||||
lwork = (int) work_size;
|
||||
|
||||
printf("work_size = %f, info = %d, lwork = %d\n", work_size, info, lwork);
|
||||
|
||||
float * work = malloc(lwork * sizeof(float));
|
||||
|
||||
sgesvd_("S", "S", &m, &n, A, &lda, S, U, &ldu, V, &ldvt, work, &lwork, &info);
|
||||
|
||||
// print U
|
||||
printf("U:\n");
|
||||
for (int i = 0; i < n; ++i) {
|
||||
printf("col %d : ", i);
|
||||
for (int j = 0; j < m; ++j) {
|
||||
printf("%9.5f ", U[i * m + j]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
// normalize S
|
||||
{
|
||||
double sum = 0.0;
|
||||
for (int i = 0; i < n; ++i) {
|
||||
sum += S[i];
|
||||
}
|
||||
sum *= sqrt((double) m);
|
||||
for (int i = 0; i < n; ++i) {
|
||||
S[i] /= sum;
|
||||
}
|
||||
}
|
||||
|
||||
// print S
|
||||
printf("S:\n");
|
||||
for (int i = 0; i < n; ++i) {
|
||||
printf("- %d = %9.5f\n", i, S[i]);
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
// print V
|
||||
printf("V:\n");
|
||||
for (int i = 0; i < n; ++i) {
|
||||
printf("col %d : ", i);
|
||||
for (int j = 0; j < n; ++j) {
|
||||
printf("%9.5f ", V[i * n + j]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
// print A
|
||||
printf("A:\n");
|
||||
for (int i = 0; i < n; ++i) {
|
||||
printf("col %d : ", i);
|
||||
for (int j = 0; j < m; ++j) {
|
||||
printf("%9.5f ", A[i * m + j]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
// compute singular vectors in U
|
||||
for (int i = 0; i < n; ++i) {
|
||||
for (int j = 0; j < m; ++j) {
|
||||
U[i * m + j] *= S[i];
|
||||
}
|
||||
}
|
||||
|
||||
// normalize U
|
||||
for (int i = 0; i < n; ++i) {
|
||||
double sum = 0.0;
|
||||
for (int j = 0; j < m; ++j) {
|
||||
sum += U[i * m + j] * U[i * m + j];
|
||||
}
|
||||
sum = sqrt(sum);
|
||||
for (int j = 0; j < m; ++j) {
|
||||
U[i * m + j] /= sum*sqrt((double) m);
|
||||
}
|
||||
}
|
||||
|
||||
// print U
|
||||
printf("U:\n");
|
||||
for (int i = 0; i < n; ++i) {
|
||||
printf("col %d : ", i);
|
||||
for (int j = 0; j < m; ++j) {
|
||||
printf("%9.5f ", U[i * m + j]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
|
||||
// project A0 onto U
|
||||
float * A1 = malloc(n * n * sizeof(float));
|
||||
|
||||
for (int i = 0; i < n; ++i) {
|
||||
for (int j = 0; j < n; ++j) {
|
||||
A1[i * n + j] = 0.0f;
|
||||
for (int k = 0; k < m; ++k) {
|
||||
A1[i * n + j] += A0[i * m + k] * U[j * m + k];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// print A1
|
||||
printf("A1:\n");
|
||||
for (int i = 0; i < n; ++i) {
|
||||
printf("col %d : ", i);
|
||||
for (int j = 0; j < n; ++j) {
|
||||
printf("%9.5f ", A1[i * n + j]);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,124 @@
|
|||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include <stdlib.h>
|
||||
#include <time.h>
|
||||
|
||||
const int N = 1 << 14;
|
||||
const int M = 1 << 14;
|
||||
|
||||
void mul_mat_vec_f32_0(
|
||||
const float * src0,
|
||||
const float * src1,
|
||||
float * dst,
|
||||
unsigned nrows,
|
||||
unsigned ncols) {
|
||||
for (unsigned i = 0; i < nrows; i++) {
|
||||
float sum = 0.0f;
|
||||
for (unsigned j = 0; j < ncols; j++) {
|
||||
sum += src0[i*ncols + j]*src1[j];
|
||||
}
|
||||
dst[i] = sum;
|
||||
}
|
||||
}
|
||||
|
||||
typedef float afloat __attribute__ ((__aligned__(32)));
|
||||
void mul_mat_vec_f32_1(
|
||||
const afloat *restrict src0,
|
||||
const afloat *restrict src1,
|
||||
afloat *restrict dst,
|
||||
unsigned nrows,
|
||||
unsigned ncols) {
|
||||
for (unsigned i = 0; i < nrows; i++) {
|
||||
const afloat * restrict row = src0 + i*ncols;
|
||||
const afloat * restrict col = src1;
|
||||
|
||||
float sum = 0.0f;
|
||||
|
||||
for (unsigned j = 0; j < ncols; j++) {
|
||||
sum += *row++ * *col++;
|
||||
}
|
||||
|
||||
dst[i] = sum;
|
||||
|
||||
//float sum[8] = {0.0f, 0.0f, 0.0f, 0.0f, 0.0f, 0.0f, 0.0f, 0.0f};
|
||||
|
||||
//for (unsigned j = 0; j < ncols; j += 8) {
|
||||
// sum[0] += row[0]*col[0];
|
||||
// sum[1] += row[1]*col[1];
|
||||
// sum[2] += row[2]*col[2];
|
||||
// sum[3] += row[3]*col[3];
|
||||
// sum[4] += row[4]*col[4];
|
||||
// sum[5] += row[5]*col[5];
|
||||
// sum[6] += row[6]*col[6];
|
||||
// sum[7] += row[7]*col[7];
|
||||
|
||||
// row += 8;
|
||||
// col += 8;
|
||||
//}
|
||||
|
||||
//dst[i] = sum[0] + sum[1] + sum[2] + sum[3] + sum[4] + sum[5] + sum[6] + sum[7];
|
||||
}
|
||||
}
|
||||
|
||||
void mul_mat_vec_f32_2(
|
||||
const void * src0,
|
||||
const void * src1,
|
||||
void * dst,
|
||||
unsigned nrows,
|
||||
unsigned ncols) {
|
||||
void * d = dst;
|
||||
for (unsigned i = 0; i < nrows; i++) {
|
||||
float sum = 0.0f;
|
||||
|
||||
const void * row = src0 + i*ncols*sizeof(float);
|
||||
const void * col = src1;
|
||||
for (unsigned j = 0; j < ncols; j++) {
|
||||
sum += (*(float *)row) * (*(float *)col);
|
||||
row += sizeof(float);
|
||||
col += sizeof(float);
|
||||
}
|
||||
*(float *)d = sum;
|
||||
d += sizeof(float);
|
||||
}
|
||||
}
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
//float * src0 = malloc(sizeof(float)*N*M);
|
||||
//float * src1 = malloc(sizeof(float)*M);
|
||||
//float * dst = malloc(sizeof(float)*N);
|
||||
|
||||
afloat * src0 = (float *)(aligned_alloc(32, sizeof(float)*N*M));
|
||||
afloat * src1 = (float *)(aligned_alloc(32, sizeof(float)*M));
|
||||
afloat * dst = (float *)(aligned_alloc(32, sizeof(float)*N));
|
||||
|
||||
for (unsigned i = 0; i < N*M; i++) {
|
||||
src0[i] = i;
|
||||
}
|
||||
|
||||
for (unsigned i = 0; i < M; i++) {
|
||||
src1[i] = i;
|
||||
}
|
||||
|
||||
const int nIter = 10;
|
||||
|
||||
const clock_t start = clock();
|
||||
|
||||
double sum = 0.0f;
|
||||
for (int i = 0; i < nIter; i++) {
|
||||
//mul_mat_vec_f32_0(src0, src1, dst, N, M);
|
||||
mul_mat_vec_f32_1(src0, src1, dst, N, M);
|
||||
//mul_mat_vec_f32_2(src0, src1, dst, N, M);
|
||||
for (unsigned i = 0; i < N; i++) {
|
||||
sum += dst[i];
|
||||
}
|
||||
}
|
||||
|
||||
{
|
||||
const clock_t end = clock();
|
||||
printf("%s: elapsed ticks: %ld\n", __func__, end - start);
|
||||
}
|
||||
|
||||
printf("%f\n", sum);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,576 @@
|
|||
#include <stdint.h>
|
||||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include <stdlib.h>
|
||||
#include <time.h>
|
||||
#include <math.h>
|
||||
|
||||
#include <sys/time.h>
|
||||
|
||||
#include <immintrin.h>
|
||||
|
||||
const int N = 1 << 14;
|
||||
const int M = 768;
|
||||
|
||||
//
|
||||
// naive implementation
|
||||
//
|
||||
|
||||
void mul_mat_vec_f32_0(
|
||||
const float * restrict src0,
|
||||
const float * restrict src1,
|
||||
float * dst,
|
||||
int nrows,
|
||||
int ncols) {
|
||||
for (int i = 0; i < nrows; i++) {
|
||||
float sum = 0.0f;
|
||||
for (int j = 0; j < ncols; j++) {
|
||||
sum += src0[i*ncols + j]*src1[j];
|
||||
}
|
||||
dst[i] = sum;
|
||||
}
|
||||
}
|
||||
|
||||
//
|
||||
// SIMD with 8 32-bit floats
|
||||
//
|
||||
|
||||
float reduce_vector8_0(__m256 v) {
|
||||
__m128 v1 = _mm256_extractf128_ps(v, 0);
|
||||
__m128 v2 = _mm256_extractf128_ps(v, 1);
|
||||
__m128 v3 = _mm_add_ps(v1, v2);
|
||||
__m128 v4 = _mm_shuffle_ps(v3, v3, 0x4e);
|
||||
__m128 v5 = _mm_add_ps(v3, v4);
|
||||
__m128 v6 = _mm_shuffle_ps(v5, v5, 0x11);
|
||||
__m128 v7 = _mm_add_ps(v5, v6);
|
||||
return _mm_cvtss_f32(v7);
|
||||
}
|
||||
|
||||
// vectorized implementation using AVX
|
||||
void mul_mat_vec_f32_1(
|
||||
const float * restrict src0,
|
||||
const float * restrict src1,
|
||||
float * dst,
|
||||
int nrows,
|
||||
int ncols) {
|
||||
|
||||
const int ncols8 = ncols & ~7;
|
||||
|
||||
for (int i = 0; i < nrows; i++) {
|
||||
__m256 sum = _mm256_setzero_ps();
|
||||
for (int j = 0; j < ncols8; j += 8) {
|
||||
__m256 a = _mm256_loadu_ps(src0 + i*ncols + j);
|
||||
__m256 b = _mm256_loadu_ps(src1 + j);
|
||||
__m256 c = _mm256_mul_ps(a, b);
|
||||
sum = _mm256_add_ps(sum, c);
|
||||
}
|
||||
dst[i] = reduce_vector8_0(sum);
|
||||
|
||||
for (int j = ncols8; j < ncols; j++) {
|
||||
dst[i] += src0[i*ncols + j]*src1[j];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void mul_mat_vec_f32_2(
|
||||
const float * restrict src0,
|
||||
const float * restrict src1,
|
||||
float * dst,
|
||||
int nrows,
|
||||
int ncols) {
|
||||
|
||||
const int ncols32 = ncols & ~31;
|
||||
|
||||
for (int i = 0; i < nrows; i++) {
|
||||
__m256 sum0 = _mm256_setzero_ps();
|
||||
__m256 sum1 = _mm256_setzero_ps();
|
||||
__m256 sum2 = _mm256_setzero_ps();
|
||||
__m256 sum3 = _mm256_setzero_ps();
|
||||
|
||||
const float * restrict src0_row = src0 + i*ncols;
|
||||
for (int j = 0; j < ncols32; j += 32) {
|
||||
__m256 a0 = _mm256_loadu_ps(src0_row + j + 0);
|
||||
__m256 a1 = _mm256_loadu_ps(src0_row + j + 8);
|
||||
__m256 a2 = _mm256_loadu_ps(src0_row + j + 16);
|
||||
__m256 a3 = _mm256_loadu_ps(src0_row + j + 24);
|
||||
__m256 b0 = _mm256_loadu_ps(src1 + j + 0);
|
||||
__m256 b1 = _mm256_loadu_ps(src1 + j + 8);
|
||||
__m256 b2 = _mm256_loadu_ps(src1 + j + 16);
|
||||
__m256 b3 = _mm256_loadu_ps(src1 + j + 24);
|
||||
#if defined(__FMA__)
|
||||
sum0 = _mm256_fmadd_ps(a0, b0, sum0);
|
||||
sum1 = _mm256_fmadd_ps(a1, b1, sum1);
|
||||
sum2 = _mm256_fmadd_ps(a2, b2, sum2);
|
||||
sum3 = _mm256_fmadd_ps(a3, b3, sum3);
|
||||
#else
|
||||
sum0 = _mm256_add_ps(_mm256_mul_ps(a0, b0), sum0);
|
||||
sum1 = _mm256_add_ps(_mm256_mul_ps(a1, b1), sum1);
|
||||
sum2 = _mm256_add_ps(_mm256_mul_ps(a2, b2), sum2);
|
||||
sum3 = _mm256_add_ps(_mm256_mul_ps(a3, b3), sum3);
|
||||
#endif
|
||||
}
|
||||
dst[i] = reduce_vector8_0(_mm256_add_ps(_mm256_add_ps(sum0, sum1), _mm256_add_ps(sum2, sum3)));
|
||||
|
||||
for (int j = ncols32; j < ncols; j++) {
|
||||
dst[i] += src0[i*ncols + j]*src1[j];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
//
|
||||
// SIMD with 8 16-bit floats
|
||||
//
|
||||
|
||||
static inline float fp32_from_bits(uint32_t w) {
|
||||
#if defined(__OPENCL_VERSION__)
|
||||
return as_float(w);
|
||||
#elif defined(__CUDA_ARCH__)
|
||||
return __uint_as_float((unsigned int) w);
|
||||
#elif defined(__INTEL_COMPILER)
|
||||
return _castu32_f32(w);
|
||||
#elif defined(_MSC_VER) && (defined(_M_ARM) || defined(_M_ARM64))
|
||||
return _CopyFloatFromInt32((__int32) w);
|
||||
#else
|
||||
union {
|
||||
uint32_t as_bits;
|
||||
float as_value;
|
||||
} fp32 = { w };
|
||||
return fp32.as_value;
|
||||
#endif
|
||||
}
|
||||
|
||||
static inline uint32_t fp32_to_bits(float f) {
|
||||
#if defined(__OPENCL_VERSION__)
|
||||
return as_uint(f);
|
||||
#elif defined(__CUDA_ARCH__)
|
||||
return (uint32_t) __float_as_uint(f);
|
||||
#elif defined(__INTEL_COMPILER)
|
||||
return _castf32_u32(f);
|
||||
#elif defined(_MSC_VER) && (defined(_M_ARM) || defined(_M_ARM64))
|
||||
return (uint32_t) _CopyInt32FromFloat(f);
|
||||
#else
|
||||
union {
|
||||
float as_value;
|
||||
uint32_t as_bits;
|
||||
} fp32 = { f };
|
||||
return fp32.as_bits;
|
||||
#endif
|
||||
}
|
||||
|
||||
/*
|
||||
* Convert a 16-bit floating-point number in IEEE half-precision format, in bit representation, to
|
||||
* a 32-bit floating-point number in IEEE single-precision format.
|
||||
*
|
||||
* @note The implementation relies on IEEE-like (no assumption about rounding mode and no operations on denormals)
|
||||
* floating-point operations and bitcasts between integer and floating-point variables.
|
||||
*/
|
||||
static inline float fp16_ieee_to_fp32_value(uint16_t h) {
|
||||
/*
|
||||
* Extend the half-precision floating-point number to 32 bits and shift to the upper part of the 32-bit word:
|
||||
* +---+-----+------------+-------------------+
|
||||
* | S |EEEEE|MM MMMM MMMM|0000 0000 0000 0000|
|
||||
* +---+-----+------------+-------------------+
|
||||
* Bits 31 26-30 16-25 0-15
|
||||
*
|
||||
* S - sign bit, E - bits of the biased exponent, M - bits of the mantissa, 0 - zero bits.
|
||||
*/
|
||||
const uint32_t w = (uint32_t) h << 16;
|
||||
/*
|
||||
* Extract the sign of the input number into the high bit of the 32-bit word:
|
||||
*
|
||||
* +---+----------------------------------+
|
||||
* | S |0000000 00000000 00000000 00000000|
|
||||
* +---+----------------------------------+
|
||||
* Bits 31 0-31
|
||||
*/
|
||||
const uint32_t sign = w & UINT32_C(0x80000000);
|
||||
/*
|
||||
* Extract mantissa and biased exponent of the input number into the high bits of the 32-bit word:
|
||||
*
|
||||
* +-----+------------+---------------------+
|
||||
* |EEEEE|MM MMMM MMMM|0 0000 0000 0000 0000|
|
||||
* +-----+------------+---------------------+
|
||||
* Bits 27-31 17-26 0-16
|
||||
*/
|
||||
const uint32_t two_w = w + w;
|
||||
|
||||
/*
|
||||
* Shift mantissa and exponent into bits 23-28 and bits 13-22 so they become mantissa and exponent
|
||||
* of a single-precision floating-point number:
|
||||
*
|
||||
* S|Exponent | Mantissa
|
||||
* +-+---+-----+------------+----------------+
|
||||
* |0|000|EEEEE|MM MMMM MMMM|0 0000 0000 0000|
|
||||
* +-+---+-----+------------+----------------+
|
||||
* Bits | 23-31 | 0-22
|
||||
*
|
||||
* Next, there are some adjustments to the exponent:
|
||||
* - The exponent needs to be corrected by the difference in exponent bias between single-precision and half-precision
|
||||
* formats (0x7F - 0xF = 0x70)
|
||||
* - Inf and NaN values in the inputs should become Inf and NaN values after conversion to the single-precision number.
|
||||
* Therefore, if the biased exponent of the half-precision input was 0x1F (max possible value), the biased exponent
|
||||
* of the single-precision output must be 0xFF (max possible value). We do this correction in two steps:
|
||||
* - First, we adjust the exponent by (0xFF - 0x1F) = 0xE0 (see exp_offset below) rather than by 0x70 suggested
|
||||
* by the difference in the exponent bias (see above).
|
||||
* - Then we multiply the single-precision result of exponent adjustment by 2**(-112) to reverse the effect of
|
||||
* exponent adjustment by 0xE0 less the necessary exponent adjustment by 0x70 due to difference in exponent bias.
|
||||
* The floating-point multiplication hardware would ensure than Inf and NaN would retain their value on at least
|
||||
* partially IEEE754-compliant implementations.
|
||||
*
|
||||
* Note that the above operations do not handle denormal inputs (where biased exponent == 0). However, they also do not
|
||||
* operate on denormal inputs, and do not produce denormal results.
|
||||
*/
|
||||
const uint32_t exp_offset = UINT32_C(0xE0) << 23;
|
||||
#if defined(__STDC_VERSION__) && (__STDC_VERSION__ >= 199901L) || defined(__GNUC__) && !defined(__STRICT_ANSI__)
|
||||
const float exp_scale = 0x1.0p-112f;
|
||||
#else
|
||||
const float exp_scale = fp32_from_bits(UINT32_C(0x7800000));
|
||||
#endif
|
||||
const float normalized_value = fp32_from_bits((two_w >> 4) + exp_offset) * exp_scale;
|
||||
|
||||
/*
|
||||
* Convert denormalized half-precision inputs into single-precision results (always normalized).
|
||||
* Zero inputs are also handled here.
|
||||
*
|
||||
* In a denormalized number the biased exponent is zero, and mantissa has on-zero bits.
|
||||
* First, we shift mantissa into bits 0-9 of the 32-bit word.
|
||||
*
|
||||
* zeros | mantissa
|
||||
* +---------------------------+------------+
|
||||
* |0000 0000 0000 0000 0000 00|MM MMMM MMMM|
|
||||
* +---------------------------+------------+
|
||||
* Bits 10-31 0-9
|
||||
*
|
||||
* Now, remember that denormalized half-precision numbers are represented as:
|
||||
* FP16 = mantissa * 2**(-24).
|
||||
* The trick is to construct a normalized single-precision number with the same mantissa and thehalf-precision input
|
||||
* and with an exponent which would scale the corresponding mantissa bits to 2**(-24).
|
||||
* A normalized single-precision floating-point number is represented as:
|
||||
* FP32 = (1 + mantissa * 2**(-23)) * 2**(exponent - 127)
|
||||
* Therefore, when the biased exponent is 126, a unit change in the mantissa of the input denormalized half-precision
|
||||
* number causes a change of the constructud single-precision number by 2**(-24), i.e. the same ammount.
|
||||
*
|
||||
* The last step is to adjust the bias of the constructed single-precision number. When the input half-precision number
|
||||
* is zero, the constructed single-precision number has the value of
|
||||
* FP32 = 1 * 2**(126 - 127) = 2**(-1) = 0.5
|
||||
* Therefore, we need to subtract 0.5 from the constructed single-precision number to get the numerical equivalent of
|
||||
* the input half-precision number.
|
||||
*/
|
||||
const uint32_t magic_mask = UINT32_C(126) << 23;
|
||||
const float magic_bias = 0.5f;
|
||||
const float denormalized_value = fp32_from_bits((two_w >> 17) | magic_mask) - magic_bias;
|
||||
|
||||
/*
|
||||
* - Choose either results of conversion of input as a normalized number, or as a denormalized number, depending on the
|
||||
* input exponent. The variable two_w contains input exponent in bits 27-31, therefore if its smaller than 2**27, the
|
||||
* input is either a denormal number, or zero.
|
||||
* - Combine the result of conversion of exponent and mantissa with the sign of the input number.
|
||||
*/
|
||||
const uint32_t denormalized_cutoff = UINT32_C(1) << 27;
|
||||
const uint32_t result = sign |
|
||||
(two_w < denormalized_cutoff ? fp32_to_bits(denormalized_value) : fp32_to_bits(normalized_value));
|
||||
return fp32_from_bits(result);
|
||||
}
|
||||
|
||||
/*
|
||||
* Convert a 32-bit floating-point number in IEEE single-precision format to a 16-bit floating-point number in
|
||||
* IEEE half-precision format, in bit representation.
|
||||
*
|
||||
* @note The implementation relies on IEEE-like (no assumption about rounding mode and no operations on denormals)
|
||||
* floating-point operations and bitcasts between integer and floating-point variables.
|
||||
*/
|
||||
static inline uint16_t fp16_ieee_from_fp32_value(float f) {
|
||||
#if defined(__STDC_VERSION__) && (__STDC_VERSION__ >= 199901L) || defined(__GNUC__) && !defined(__STRICT_ANSI__)
|
||||
const float scale_to_inf = 0x1.0p+112f;
|
||||
const float scale_to_zero = 0x1.0p-110f;
|
||||
#else
|
||||
const float scale_to_inf = fp32_from_bits(UINT32_C(0x77800000));
|
||||
const float scale_to_zero = fp32_from_bits(UINT32_C(0x08800000));
|
||||
#endif
|
||||
float base = (fabsf(f) * scale_to_inf) * scale_to_zero;
|
||||
|
||||
const uint32_t w = fp32_to_bits(f);
|
||||
const uint32_t shl1_w = w + w;
|
||||
const uint32_t sign = w & UINT32_C(0x80000000);
|
||||
uint32_t bias = shl1_w & UINT32_C(0xFF000000);
|
||||
if (bias < UINT32_C(0x71000000)) {
|
||||
bias = UINT32_C(0x71000000);
|
||||
}
|
||||
|
||||
base = fp32_from_bits((bias >> 1) + UINT32_C(0x07800000)) + base;
|
||||
const uint32_t bits = fp32_to_bits(base);
|
||||
const uint32_t exp_bits = (bits >> 13) & UINT32_C(0x00007C00);
|
||||
const uint32_t mantissa_bits = bits & UINT32_C(0x00000FFF);
|
||||
const uint32_t nonsign = exp_bits + mantissa_bits;
|
||||
return (sign >> 16) | (shl1_w > UINT32_C(0xFF000000) ? UINT16_C(0x7E00) : nonsign);
|
||||
}
|
||||
|
||||
void mul_mat_vec_f16_0(
|
||||
const uint16_t * src0,
|
||||
const uint16_t * src1,
|
||||
float * dst,
|
||||
int nrows,
|
||||
int ncols) {
|
||||
|
||||
const int ncols8 = ncols & ~7;
|
||||
|
||||
for (int i = 0; i < nrows; i++) {
|
||||
__m256 sum = _mm256_setzero_ps();
|
||||
|
||||
const uint16_t * src0_row = src0 + i * ncols;
|
||||
for (int j = 0; j < ncols8; j += 8) {
|
||||
__m256 a = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src0_row + j)));
|
||||
__m256 b = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src1 + j)));
|
||||
#if defined(__FMA__)
|
||||
sum = _mm256_fmadd_ps(a, b, sum);
|
||||
#else
|
||||
sum = _mm256_add_ps(_mm256_mul_ps(a, b), sum);
|
||||
#endif
|
||||
}
|
||||
dst[i] = reduce_vector8_0(sum);
|
||||
|
||||
for (int j = ncols8; j < ncols; j++) {
|
||||
dst[i] += fp16_ieee_to_fp32_value(src0_row[j]) * fp16_ieee_to_fp32_value(src1[j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void mul_mat_vec_f16_1(
|
||||
const uint16_t * src0,
|
||||
const uint16_t * src1,
|
||||
float * dst,
|
||||
int nrows,
|
||||
int ncols) {
|
||||
|
||||
const int ncols16 = ncols & ~15;
|
||||
|
||||
for (int i = 0; i < nrows; i++) {
|
||||
__m256 sum0 = _mm256_setzero_ps();
|
||||
__m256 sum1 = _mm256_setzero_ps();
|
||||
|
||||
const uint16_t * src0_row = src0 + i * ncols;
|
||||
for (int j = 0; j < ncols16; j += 16) {
|
||||
__m256 a0 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src0_row + j + 0)));
|
||||
__m256 a1 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src0_row + j + 8)));
|
||||
__m256 b0 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src1 + j)));
|
||||
__m256 b1 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src1 + j + 8)));
|
||||
#if defined(__FMA__)
|
||||
sum0 = _mm256_fmadd_ps(a0, b0, sum0);
|
||||
sum1 = _mm256_fmadd_ps(a1, b1, sum1);
|
||||
#else
|
||||
sum0 = _mm256_add_ps(_mm256_mul_ps(a0, b0), sum0);
|
||||
sum1 = _mm256_add_ps(_mm256_mul_ps(a1, b1), sum1);
|
||||
#endif
|
||||
}
|
||||
dst[i] = reduce_vector8_0(sum0) + reduce_vector8_0(sum1);
|
||||
|
||||
for (int j = ncols16; j < ncols; j++) {
|
||||
dst[i] += fp16_ieee_to_fp32_value(src0_row[j]) * fp16_ieee_to_fp32_value(src1[j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void mul_mat_vec_f16_2(
|
||||
const uint16_t * src0,
|
||||
const uint16_t * src1,
|
||||
float * dst,
|
||||
int nrows,
|
||||
int ncols) {
|
||||
|
||||
const int ncols32 = ncols & ~31;
|
||||
|
||||
for (int i = 0; i < nrows; i++) {
|
||||
__m256 sum0 = _mm256_setzero_ps();
|
||||
__m256 sum1 = _mm256_setzero_ps();
|
||||
__m256 sum2 = _mm256_setzero_ps();
|
||||
__m256 sum3 = _mm256_setzero_ps();
|
||||
|
||||
const uint16_t * src0_row = src0 + i * ncols;
|
||||
for (int j = 0; j < ncols32; j += 32) {
|
||||
__m256 a0 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src0_row + j + 0)));
|
||||
__m256 a1 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src0_row + j + 8)));
|
||||
__m256 a2 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src0_row + j + 16)));
|
||||
__m256 a3 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src0_row + j + 24)));
|
||||
__m256 b0 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src1 + j)));
|
||||
__m256 b1 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src1 + j + 8)));
|
||||
__m256 b2 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src1 + j + 16)));
|
||||
__m256 b3 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src1 + j + 24)));
|
||||
#if defined(__FMA__)
|
||||
sum0 = _mm256_fmadd_ps(a0, b0, sum0);
|
||||
sum1 = _mm256_fmadd_ps(a1, b1, sum1);
|
||||
sum2 = _mm256_fmadd_ps(a2, b2, sum2);
|
||||
sum3 = _mm256_fmadd_ps(a3, b3, sum3);
|
||||
#else
|
||||
sum0 = _mm256_add_ps(_mm256_mul_ps(a0, b0), sum0);
|
||||
sum1 = _mm256_add_ps(_mm256_mul_ps(a1, b1), sum1);
|
||||
sum2 = _mm256_add_ps(_mm256_mul_ps(a2, b2), sum2);
|
||||
sum3 = _mm256_add_ps(_mm256_mul_ps(a3, b3), sum3);
|
||||
#endif
|
||||
}
|
||||
dst[i] = reduce_vector8_0(sum0) + reduce_vector8_0(sum1) + reduce_vector8_0(sum2) + reduce_vector8_0(sum3);
|
||||
|
||||
for (int j = ncols32; j < ncols; j++) {
|
||||
dst[i] += fp16_ieee_to_fp32_value(src0_row[j]) * fp16_ieee_to_fp32_value(src1[j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void mul_mat_vec_f16_3(
|
||||
const uint16_t * src0,
|
||||
const float * src1,
|
||||
float * dst,
|
||||
int nrows,
|
||||
int ncols) {
|
||||
|
||||
const int ncols32 = ncols & ~31;
|
||||
|
||||
for (int i = 0; i < nrows; i++) {
|
||||
__m256 sum0 = _mm256_setzero_ps();
|
||||
__m256 sum1 = _mm256_setzero_ps();
|
||||
__m256 sum2 = _mm256_setzero_ps();
|
||||
__m256 sum3 = _mm256_setzero_ps();
|
||||
|
||||
const uint16_t * src0_row = src0 + i * ncols;
|
||||
for (int j = 0; j < ncols32; j += 32) {
|
||||
__m256 a0 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src0_row + j + 0)));
|
||||
__m256 a1 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src0_row + j + 8)));
|
||||
__m256 a2 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src0_row + j + 16)));
|
||||
__m256 a3 = _mm256_cvtph_ps(_mm_loadu_si128((__m128i*)(src0_row + j + 24)));
|
||||
__m256 b0 = _mm256_loadu_ps(src1 + j);
|
||||
__m256 b1 = _mm256_loadu_ps(src1 + j + 8);
|
||||
__m256 b2 = _mm256_loadu_ps(src1 + j + 16);
|
||||
__m256 b3 = _mm256_loadu_ps(src1 + j + 24);
|
||||
#if defined(__FMA__)
|
||||
sum0 = _mm256_fmadd_ps(a0, b0, sum0);
|
||||
sum1 = _mm256_fmadd_ps(a1, b1, sum1);
|
||||
sum2 = _mm256_fmadd_ps(a2, b2, sum2);
|
||||
sum3 = _mm256_fmadd_ps(a3, b3, sum3);
|
||||
#else
|
||||
sum0 = _mm256_add_ps(_mm256_mul_ps(a0, b0), sum0);
|
||||
sum1 = _mm256_add_ps(_mm256_mul_ps(a1, b1), sum1);
|
||||
sum2 = _mm256_add_ps(_mm256_mul_ps(a2, b2), sum2);
|
||||
sum3 = _mm256_add_ps(_mm256_mul_ps(a3, b3), sum3);
|
||||
#endif
|
||||
}
|
||||
dst[i] = reduce_vector8_0(sum0) + reduce_vector8_0(sum1) + reduce_vector8_0(sum2) + reduce_vector8_0(sum3);
|
||||
|
||||
for (int j = ncols32; j < ncols; j++) {
|
||||
dst[i] += fp16_ieee_to_fp32_value(src0_row[j]) * fp16_ieee_to_fp32_value(src1[j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
uint64_t get_time_us() {
|
||||
struct timeval tv;
|
||||
gettimeofday(&tv, NULL);
|
||||
return tv.tv_sec * 1000000 + tv.tv_usec;
|
||||
}
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
float * src0 = malloc(sizeof(float)*N*M);
|
||||
float * src1 = malloc(sizeof(float)*M);
|
||||
float * dst = malloc(sizeof(float)*N);
|
||||
|
||||
//float * src0 = (float *)(aligned_alloc(64, sizeof(float)*N*M));
|
||||
//float * src1 = (float *)(aligned_alloc(64, sizeof(float)*M));
|
||||
//float * dst = (float *)(aligned_alloc(64, sizeof(float)*N));
|
||||
|
||||
for (int i = 0; i < N*M; i++) {
|
||||
src0[i] = rand() / (float)RAND_MAX;
|
||||
}
|
||||
|
||||
for (int i = 0; i < M; i++) {
|
||||
src1[i] = rand() / (float)RAND_MAX;
|
||||
}
|
||||
|
||||
// convert src0 and src1 to __fp16
|
||||
uint16_t * src0_fp16 = (uint16_t *)(malloc(sizeof(uint16_t)*N*M));
|
||||
uint16_t * src1_fp16 = (uint16_t *)(malloc(sizeof(uint16_t)*M));
|
||||
//uint16_t * src0_fp16 = (uint16_t *)(aligned_alloc(64, sizeof(uint16_t)*N*M));
|
||||
//uint16_t * src1_fp16 = (uint16_t *)(aligned_alloc(64, sizeof(uint16_t)*M));
|
||||
|
||||
{
|
||||
const uint64_t t_start = get_time_us();
|
||||
|
||||
for (int i = 0; i < N*M; i++) {
|
||||
src0_fp16[i] = fp16_ieee_from_fp32_value(src0[i]);
|
||||
//printf("%f %f\n", src0[i], fp16_ieee_to_fp32_value(src0_fp16[i]));
|
||||
//assert(!isnan(fp16_ieee_to_fp32_value(src0_fp16[i])));
|
||||
}
|
||||
|
||||
for (int i = 0; i < M; i++) {
|
||||
src1_fp16[i] = fp16_ieee_from_fp32_value(src1[i]);
|
||||
}
|
||||
|
||||
const uint64_t t_end = get_time_us();
|
||||
printf("convert time: %f ms\n", (t_end - t_start) / 1000.0);
|
||||
}
|
||||
|
||||
for (int i = 0; i < 16; ++i) {
|
||||
printf("%f %f\n", src0[i], fp16_ieee_to_fp32_value(src0_fp16[i]));
|
||||
}
|
||||
|
||||
int method = 0;
|
||||
if (argc > 1) {
|
||||
method = atoi(argv[1]);
|
||||
}
|
||||
|
||||
const int nIter = 1000;
|
||||
|
||||
const clock_t start = clock();
|
||||
const uint64_t start_us = get_time_us();
|
||||
|
||||
double iM = 1.0/M;
|
||||
double sum = 0.0f;
|
||||
for (int i = 0; i < nIter; i++) {
|
||||
if (method == 0) {
|
||||
mul_mat_vec_f32_0(src0, src1, dst, N, M);
|
||||
}
|
||||
|
||||
if (method == 1) {
|
||||
mul_mat_vec_f32_1(src0, src1, dst, N, M);
|
||||
}
|
||||
|
||||
if (method == 2) {
|
||||
mul_mat_vec_f32_2(src0, src1, dst, N, M);
|
||||
}
|
||||
|
||||
if (method == 3) {
|
||||
mul_mat_vec_f16_0(src0_fp16, src1_fp16, dst, N, M);
|
||||
}
|
||||
|
||||
if (method == 4) {
|
||||
mul_mat_vec_f16_1(src0_fp16, src1_fp16, dst, N, M);
|
||||
}
|
||||
|
||||
if (method == 5) {
|
||||
mul_mat_vec_f16_2(src0_fp16, src1_fp16, dst, N, M);
|
||||
}
|
||||
|
||||
if (method == 6) {
|
||||
mul_mat_vec_f16_3(src0_fp16, src1, dst, N, M);
|
||||
}
|
||||
}
|
||||
|
||||
for (int i = 0; i < N; i++) {
|
||||
sum += dst[i]*iM;
|
||||
}
|
||||
|
||||
{
|
||||
const clock_t end = clock();
|
||||
const uint64_t end_us = get_time_us();
|
||||
printf("%s: elapsed ticks: %ld\n", __func__, end - start);
|
||||
printf("%s: elapsed us: %ld\n", __func__, end_us - start_us);
|
||||
}
|
||||
|
||||
printf("%f\n", sum);
|
||||
|
||||
free(src0);
|
||||
free(src1);
|
||||
free(dst);
|
||||
|
||||
free(src0_fp16);
|
||||
free(src1_fp16);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,268 @@
|
|||
#include <stdint.h>
|
||||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include <stdlib.h>
|
||||
#include <time.h>
|
||||
#include <math.h>
|
||||
|
||||
#include <sys/time.h>
|
||||
|
||||
#include <arm_neon.h>
|
||||
|
||||
const int N = 1 << 12;
|
||||
const int M = 1 << 12;
|
||||
|
||||
//
|
||||
// naive implementation
|
||||
//
|
||||
|
||||
void mul_mat_vec_f32_0(
|
||||
const float * restrict src0,
|
||||
const float * restrict src1,
|
||||
float * dst,
|
||||
int nrows,
|
||||
int ncols) {
|
||||
for (int i = 0; i < nrows; i++) {
|
||||
float sum = 0.0f;
|
||||
for (int j = 0; j < ncols; j++) {
|
||||
sum += src0[i*ncols + j]*src1[j];
|
||||
}
|
||||
dst[i] = sum;
|
||||
}
|
||||
}
|
||||
|
||||
void mul_mat_vec_f16_0(
|
||||
const __fp16 * src0,
|
||||
const __fp16 * src1,
|
||||
float * dst,
|
||||
int nrows,
|
||||
int ncols) {
|
||||
|
||||
const int n64 = ncols & ~63;
|
||||
|
||||
for (int r = 0; r < nrows; r++) {
|
||||
float sumf = 0.0;
|
||||
|
||||
float16x8_t sum0 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum1 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum2 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum3 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum4 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum5 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum6 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum7 = vdupq_n_f16(0.0f);
|
||||
|
||||
float16x8_t x0, x1, x2, x3, x4, x5, x6, x7;
|
||||
float16x8_t y0, y1, y2, y3, y4, y5, y6, y7;
|
||||
|
||||
const __fp16 * restrict p0 = src0 + r*ncols;
|
||||
|
||||
for (int i = 0; i < n64; i += 64) {
|
||||
x0 = vld1q_f16(p0 + i + 0 );
|
||||
x1 = vld1q_f16(p0 + i + 8 );
|
||||
x2 = vld1q_f16(p0 + i + 16);
|
||||
x3 = vld1q_f16(p0 + i + 24);
|
||||
x4 = vld1q_f16(p0 + i + 32);
|
||||
x5 = vld1q_f16(p0 + i + 40);
|
||||
x6 = vld1q_f16(p0 + i + 48);
|
||||
x7 = vld1q_f16(p0 + i + 56);
|
||||
|
||||
y0 = vld1q_f16(src1 + i + 0 );
|
||||
y1 = vld1q_f16(src1 + i + 8 );
|
||||
y2 = vld1q_f16(src1 + i + 16);
|
||||
y3 = vld1q_f16(src1 + i + 24);
|
||||
y4 = vld1q_f16(src1 + i + 32);
|
||||
y5 = vld1q_f16(src1 + i + 40);
|
||||
y6 = vld1q_f16(src1 + i + 48);
|
||||
y7 = vld1q_f16(src1 + i + 56);
|
||||
|
||||
sum0 = vfmaq_f16(sum0, x0, y0);
|
||||
sum1 = vfmaq_f16(sum1, x1, y1);
|
||||
sum2 = vfmaq_f16(sum2, x2, y2);
|
||||
sum3 = vfmaq_f16(sum3, x3, y3);
|
||||
sum4 = vfmaq_f16(sum4, x4, y4);
|
||||
sum5 = vfmaq_f16(sum5, x5, y5);
|
||||
sum6 = vfmaq_f16(sum6, x6, y6);
|
||||
sum7 = vfmaq_f16(sum7, x7, y7);
|
||||
}
|
||||
|
||||
// TODO: F16 - better way to reduce this ?
|
||||
float16x8_t sum = vaddq_f16(sum0, sum1);
|
||||
|
||||
sum = vaddq_f16(sum, sum2);
|
||||
sum = vaddq_f16(sum, sum3);
|
||||
sum = vaddq_f16(sum, sum4);
|
||||
sum = vaddq_f16(sum, sum5);
|
||||
sum = vaddq_f16(sum, sum6);
|
||||
sum = vaddq_f16(sum, sum7);
|
||||
|
||||
sumf += sum[0] + sum[1] + sum[2] + sum[3] + sum[4] + sum[5] + sum[6] + sum[7];
|
||||
|
||||
for (int j = n64; j < n64; j++) {
|
||||
sumf += src0[r*ncols + j]*src1[j];
|
||||
}
|
||||
|
||||
dst[r] = sumf;
|
||||
}
|
||||
}
|
||||
|
||||
void mul_mat_vec_f16_1(
|
||||
const __fp16 * src0,
|
||||
const __fp16 * src1,
|
||||
float * dst,
|
||||
int nrows,
|
||||
int ncols) {
|
||||
|
||||
const int n32 = ncols & ~31;
|
||||
|
||||
for (int r = 0; r < nrows; r++) {
|
||||
float sumf = 0.0;
|
||||
|
||||
float16x8_t sum0 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum1 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum2 = vdupq_n_f16(0.0f);
|
||||
float16x8_t sum3 = vdupq_n_f16(0.0f);
|
||||
|
||||
float16x8_t x0, x1, x2, x3;
|
||||
float16x8_t y0, y1, y2, y3;
|
||||
|
||||
const __fp16 * restrict p0 = src0 + r*ncols;
|
||||
|
||||
for (int i = 0; i < n32; i += 32) {
|
||||
x0 = vld1q_f16(p0 + i + 0 );
|
||||
x1 = vld1q_f16(p0 + i + 8 );
|
||||
x2 = vld1q_f16(p0 + i + 16);
|
||||
x3 = vld1q_f16(p0 + i + 24);
|
||||
|
||||
y0 = vld1q_f16(src1 + i + 0 );
|
||||
y1 = vld1q_f16(src1 + i + 8 );
|
||||
y2 = vld1q_f16(src1 + i + 16);
|
||||
y3 = vld1q_f16(src1 + i + 24);
|
||||
|
||||
sum0 = vfmaq_f16(sum0, x0, y0);
|
||||
sum1 = vfmaq_f16(sum1, x1, y1);
|
||||
sum2 = vfmaq_f16(sum2, x2, y2);
|
||||
sum3 = vfmaq_f16(sum3, x3, y3);
|
||||
}
|
||||
|
||||
// reduce sum0..sum3 to sum0
|
||||
sum0 = vaddq_f16(sum0, sum1);
|
||||
sum2 = vaddq_f16(sum2, sum3);
|
||||
sum0 = vaddq_f16(sum0, sum2);
|
||||
|
||||
// load sum0 into 2 float32x4_t
|
||||
float32x4_t sum0f32 = vcvt_f32_f16(vget_low_f16(sum0));
|
||||
float32x4_t sum1f32 = vcvt_f32_f16(vget_high_f16(sum0));
|
||||
|
||||
// reduce sum0f32 and sum1f32 to sumf
|
||||
sum0f32 = vaddq_f32(sum0f32, sum1f32);
|
||||
|
||||
float32x2_t sumf32 = vadd_f32(vget_low_f32(sum0f32), vget_high_f32(sum0f32));
|
||||
sumf = vget_lane_f32(sumf32, 0) + vget_lane_f32(sumf32, 1);
|
||||
|
||||
//sumf = sum0[0] + sum0[1] + sum0[2] + sum0[3] + sum0[4] + sum0[5] + sum0[6] + sum0[7];
|
||||
|
||||
for (int j = n32; j < n32; j++) {
|
||||
sumf += src0[r*ncols + j]*src1[j];
|
||||
}
|
||||
|
||||
dst[r] = sumf;
|
||||
}
|
||||
}
|
||||
|
||||
uint64_t get_time_us() {
|
||||
struct timeval tv;
|
||||
gettimeofday(&tv, NULL);
|
||||
return tv.tv_sec * 1000000 + tv.tv_usec;
|
||||
}
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
float * src0 = malloc(sizeof(float)*N*M);
|
||||
float * src1 = malloc(sizeof(float)*M);
|
||||
float * dst = malloc(sizeof(float)*N);
|
||||
|
||||
//float * src0 = (float *)(aligned_alloc(64, sizeof(float)*N*M));
|
||||
//float * src1 = (float *)(aligned_alloc(64, sizeof(float)*M));
|
||||
//float * dst = (float *)(aligned_alloc(64, sizeof(float)*N));
|
||||
|
||||
for (int i = 0; i < N*M; i++) {
|
||||
src0[i] = rand() / (float)RAND_MAX;
|
||||
}
|
||||
|
||||
for (int i = 0; i < M; i++) {
|
||||
src1[i] = rand() / (float)RAND_MAX;
|
||||
}
|
||||
|
||||
// convert src0 and src1 to __fp16
|
||||
__fp16 * src0_fp16 = (__fp16 *)(malloc(sizeof(__fp16)*N*M));
|
||||
__fp16 * src1_fp16 = (__fp16 *)(malloc(sizeof(__fp16)*M));
|
||||
|
||||
{
|
||||
const uint64_t t_start = get_time_us();
|
||||
|
||||
for (int i = 0; i < N*M; i++) {
|
||||
src0_fp16[i] = src0[i];
|
||||
//printf("%f %f\n", src0[i], src0_fp16[i]);
|
||||
//assert(!isnan(src0_fp16[i]));
|
||||
}
|
||||
|
||||
for (int i = 0; i < M; i++) {
|
||||
src1_fp16[i] = src1[i];
|
||||
}
|
||||
|
||||
const uint64_t t_end = get_time_us();
|
||||
printf("convert time: %f ms\n", (t_end - t_start) / 1000.0);
|
||||
}
|
||||
|
||||
for (int i = 0; i < 16; ++i) {
|
||||
printf("%f %f\n", src0[i], src0_fp16[i]);
|
||||
}
|
||||
|
||||
int method = 0;
|
||||
if (argc > 1) {
|
||||
method = atoi(argv[1]);
|
||||
}
|
||||
|
||||
const int nIter = 1000;
|
||||
|
||||
const clock_t start = clock();
|
||||
const uint64_t start_us = get_time_us();
|
||||
|
||||
double iM = 1.0/M;
|
||||
double sum = 0.0f;
|
||||
for (int i = 0; i < nIter; i++) {
|
||||
if (method == 0) {
|
||||
mul_mat_vec_f32_0(src0, src1, dst, N, M);
|
||||
}
|
||||
|
||||
if (method == 1) {
|
||||
mul_mat_vec_f16_0(src0_fp16, src1_fp16, dst, N, M);
|
||||
}
|
||||
|
||||
if (method == 2) {
|
||||
mul_mat_vec_f16_1(src0_fp16, src1_fp16, dst, N, M);
|
||||
}
|
||||
}
|
||||
|
||||
for (int i = 0; i < N; i++) {
|
||||
sum += dst[i]*iM;
|
||||
}
|
||||
|
||||
{
|
||||
const clock_t end = clock();
|
||||
const uint64_t end_us = get_time_us();
|
||||
printf("%s: elapsed ticks: %ld\n", __func__, end - start);
|
||||
printf("%s: elapsed us: %llu / %f ms\n", __func__, end_us - start_us, (end_us - start_us) / 1000.0 / nIter);
|
||||
}
|
||||
|
||||
printf("%f\n", sum);
|
||||
|
||||
free(src0);
|
||||
free(src1);
|
||||
free(dst);
|
||||
|
||||
free(src0_fp16);
|
||||
free(src1_fp16);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,43 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <assert.h>
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = 128*1024*1024,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
|
||||
struct ggml_tensor * t1 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 10);
|
||||
struct ggml_tensor * t2 = ggml_new_tensor_2d(ctx0, GGML_TYPE_I16, 10, 20);
|
||||
struct ggml_tensor * t3 = ggml_new_tensor_3d(ctx0, GGML_TYPE_I32, 10, 20, 30);
|
||||
|
||||
assert(t1->n_dims == 1);
|
||||
assert(t1->ne[0] == 10);
|
||||
assert(t1->nb[1] == 10*sizeof(float));
|
||||
|
||||
assert(t2->n_dims == 2);
|
||||
assert(t2->ne[0] == 10);
|
||||
assert(t2->ne[1] == 20);
|
||||
assert(t2->nb[1] == 10*sizeof(int16_t));
|
||||
assert(t2->nb[2] == 10*20*sizeof(int16_t));
|
||||
|
||||
assert(t3->n_dims == 3);
|
||||
assert(t3->ne[0] == 10);
|
||||
assert(t3->ne[1] == 20);
|
||||
assert(t3->ne[2] == 30);
|
||||
assert(t3->nb[1] == 10*sizeof(int32_t));
|
||||
assert(t3->nb[2] == 10*20*sizeof(int32_t));
|
||||
assert(t3->nb[3] == 10*20*30*sizeof(int32_t));
|
||||
|
||||
ggml_print_objects(ctx0);
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,437 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <assert.h>
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = 128*1024*1024,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
|
||||
{
|
||||
struct ggml_tensor * x = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
||||
|
||||
ggml_set_param(ctx0, x);
|
||||
|
||||
struct ggml_tensor * a = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
||||
struct ggml_tensor * b = ggml_mul(ctx0, x, x);
|
||||
struct ggml_tensor * f = ggml_mul(ctx0, b, a);
|
||||
|
||||
// a*x^2
|
||||
// 2*a*x
|
||||
|
||||
ggml_print_objects(ctx0);
|
||||
|
||||
struct ggml_cgraph gf = ggml_build_forward(f);
|
||||
struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);
|
||||
|
||||
ggml_set_f32(x, 2.0f);
|
||||
ggml_set_f32(a, 3.0f);
|
||||
|
||||
ggml_graph_reset(&gf);
|
||||
ggml_set_f32(f->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
printf("f = %f\n", ggml_get_f32_1d(f, 0));
|
||||
printf("df/dx = %f\n", ggml_get_f32_1d(x->grad, 0));
|
||||
|
||||
assert(ggml_get_f32_1d(f, 0) == 12.0f);
|
||||
assert(ggml_get_f32_1d(x->grad, 0) == 12.0f);
|
||||
|
||||
ggml_set_f32(x, 3.0f);
|
||||
|
||||
ggml_graph_reset(&gf);
|
||||
ggml_set_f32(f->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
printf("f = %f\n", ggml_get_f32_1d(f, 0));
|
||||
printf("df/dx = %f\n", ggml_get_f32_1d(x->grad, 0));
|
||||
|
||||
assert(ggml_get_f32_1d(f, 0) == 27.0f);
|
||||
assert(ggml_get_f32_1d(x->grad, 0) == 18.0f);
|
||||
|
||||
ggml_graph_dump_dot(&gf, NULL, "test1-1-forward.dot");
|
||||
ggml_graph_dump_dot(&gb, &gf, "test1-1-backward.dot");
|
||||
}
|
||||
|
||||
///////////////////////////////////////////////////////////////
|
||||
|
||||
{
|
||||
struct ggml_tensor * x1 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
||||
struct ggml_tensor * x2 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
||||
struct ggml_tensor * x3 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
||||
|
||||
ggml_set_f32(x1, 3.0f);
|
||||
ggml_set_f32(x2, 1.0f);
|
||||
ggml_set_f32(x3, 0.0f);
|
||||
|
||||
ggml_set_param(ctx0, x1);
|
||||
ggml_set_param(ctx0, x2);
|
||||
|
||||
struct ggml_tensor * y = ggml_add(ctx0, ggml_mul(ctx0, x1, x1), ggml_mul(ctx0, x1, x2));
|
||||
|
||||
struct ggml_cgraph gf = ggml_build_forward(y);
|
||||
struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);
|
||||
|
||||
ggml_graph_reset(&gf);
|
||||
ggml_set_f32(y->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
printf("y = %f\n", ggml_get_f32_1d(y, 0));
|
||||
printf("df/dx1 = %f\n", ggml_get_f32_1d(x1->grad, 0));
|
||||
printf("df/dx2 = %f\n", ggml_get_f32_1d(x2->grad, 0));
|
||||
|
||||
assert(ggml_get_f32_1d(y, 0) == 12.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 0) == 7.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 0) == 3.0f);
|
||||
|
||||
struct ggml_tensor * g1 = x1->grad;
|
||||
struct ggml_tensor * g2 = x2->grad;
|
||||
|
||||
struct ggml_cgraph gbb = ggml_build_backward(ctx0, &gb, true);
|
||||
|
||||
ggml_graph_reset(&gb);
|
||||
ggml_set_f32(g1->grad, 1.0f);
|
||||
ggml_set_f32(g2->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gbb);
|
||||
|
||||
printf("H * [1, 1] = [ %f %f ]\n", ggml_get_f32_1d(x1->grad, 0), ggml_get_f32_1d(x2->grad, 0));
|
||||
|
||||
assert(ggml_get_f32_1d(x1->grad, 0) == 3.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 0) == 1.0f);
|
||||
|
||||
ggml_graph_dump_dot(&gf, NULL, "test1-2-forward.dot");
|
||||
ggml_graph_dump_dot(&gb, &gf, "test1-2-backward.dot");
|
||||
}
|
||||
|
||||
///////////////////////////////////////////////////////////////
|
||||
|
||||
{
|
||||
struct ggml_tensor * x1 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
||||
struct ggml_tensor * x2 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
||||
|
||||
ggml_set_param(ctx0, x1);
|
||||
ggml_set_param(ctx0, x2);
|
||||
|
||||
struct ggml_tensor * y = ggml_mul(ctx0, ggml_add(ctx0, ggml_mul(ctx0, x1, x1), ggml_mul(ctx0, x1, x2)), x1);
|
||||
|
||||
struct ggml_cgraph gf = ggml_build_forward(y);
|
||||
struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);
|
||||
|
||||
ggml_set_f32(x1, 3.0f);
|
||||
ggml_set_f32(x2, 4.0f);
|
||||
|
||||
ggml_graph_reset(&gf);
|
||||
ggml_set_f32(y->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
printf("y = %f\n", ggml_get_f32_1d(y, 0));
|
||||
printf("df/dx1 = %f\n", ggml_get_f32_1d(x1->grad, 0));
|
||||
printf("df/dx2 = %f\n", ggml_get_f32_1d(x2->grad, 0));
|
||||
|
||||
assert(ggml_get_f32_1d(y, 0) == 63.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 0) == 51.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 0) == 9.0f);
|
||||
|
||||
ggml_graph_dump_dot(&gf, NULL, "test1-3-forward.dot");
|
||||
ggml_graph_dump_dot(&gb, &gf, "test1-3-backward.dot");
|
||||
}
|
||||
|
||||
///////////////////////////////////////////////////////////////
|
||||
|
||||
{
|
||||
struct ggml_tensor * x1 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
||||
struct ggml_tensor * x2 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
||||
struct ggml_tensor * x3 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
||||
|
||||
ggml_set_param(ctx0, x1);
|
||||
ggml_set_param(ctx0, x2);
|
||||
ggml_set_param(ctx0, x3);
|
||||
|
||||
struct ggml_tensor * y = ggml_mul(ctx0, ggml_mul(ctx0, ggml_mul(ctx0, x1, x1), ggml_mul(ctx0, x2, x2)), x3);
|
||||
|
||||
struct ggml_cgraph gf = ggml_build_forward(y);
|
||||
struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);
|
||||
|
||||
ggml_set_f32(x1, 1.0f);
|
||||
ggml_set_f32(x2, 2.0f);
|
||||
ggml_set_f32(x3, 3.0f);
|
||||
|
||||
ggml_graph_reset(&gf);
|
||||
ggml_set_f32(y->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
printf("y = %f\n", ggml_get_f32_1d(y, 0));
|
||||
printf("df/dx1 = %f\n", ggml_get_f32_1d(x1->grad, 0));
|
||||
printf("df/dx2 = %f\n", ggml_get_f32_1d(x2->grad, 0));
|
||||
printf("df/dx3 = %f\n", ggml_get_f32_1d(x3->grad, 0));
|
||||
|
||||
assert(ggml_get_f32_1d(y, 0) == 12.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 0) == 24.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 0) == 12.0f);
|
||||
assert(ggml_get_f32_1d(x3->grad, 0) == 4.0f);
|
||||
|
||||
struct ggml_tensor * g1 = x1->grad;
|
||||
struct ggml_tensor * g2 = x2->grad;
|
||||
struct ggml_tensor * g3 = x3->grad;
|
||||
|
||||
struct ggml_cgraph gbb = ggml_build_backward(ctx0, &gb, true);
|
||||
|
||||
ggml_graph_reset(&gb);
|
||||
ggml_set_f32(g1->grad, 1.0f);
|
||||
ggml_set_f32(g2->grad, 1.0f);
|
||||
ggml_set_f32(g3->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gbb);
|
||||
|
||||
printf("H * [1, 1, 1] = [ %f %f %f ]\n",
|
||||
ggml_get_f32_1d(x1->grad, 0),
|
||||
ggml_get_f32_1d(x2->grad, 0),
|
||||
ggml_get_f32_1d(x3->grad, 0));
|
||||
|
||||
assert(ggml_get_f32_1d(x1->grad, 0) == 56.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 0) == 34.0f);
|
||||
assert(ggml_get_f32_1d(x3->grad, 0) == 12.0f);
|
||||
|
||||
ggml_graph_dump_dot(&gf, NULL, "test1-4-forward.dot");
|
||||
ggml_graph_dump_dot(&gb, &gf, "test1-4-backward.dot");
|
||||
}
|
||||
|
||||
///////////////////////////////////////////////////////////////
|
||||
|
||||
{
|
||||
struct ggml_tensor * x1 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 3);
|
||||
struct ggml_tensor * x2 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 3);
|
||||
|
||||
ggml_set_param(ctx0, x1);
|
||||
ggml_set_param(ctx0, x2);
|
||||
|
||||
struct ggml_tensor * y = ggml_sum(ctx0, ggml_mul(ctx0, x1, x2));
|
||||
|
||||
struct ggml_cgraph gf = ggml_build_forward(y);
|
||||
struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);
|
||||
|
||||
ggml_set_f32(x1, 3.0f);
|
||||
ggml_set_f32(x2, 5.0f);
|
||||
|
||||
ggml_graph_reset(&gf);
|
||||
ggml_set_f32(y->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
printf("y = %f\n", ggml_get_f32_1d(y, 0));
|
||||
printf("df/dx1 = %f %f %f\n",
|
||||
ggml_get_f32_1d(x1->grad, 0),
|
||||
ggml_get_f32_1d(x1->grad, 1),
|
||||
ggml_get_f32_1d(x1->grad, 2));
|
||||
printf("df/dx2 = %f %f %f\n",
|
||||
ggml_get_f32_1d(x2->grad, 0),
|
||||
ggml_get_f32_1d(x2->grad, 1),
|
||||
ggml_get_f32_1d(x2->grad, 2));
|
||||
|
||||
assert(ggml_get_f32_1d(y, 0) == 45.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 0) == 5.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 0) == 3.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 1) == 5.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 1) == 3.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 2) == 5.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 2) == 3.0f);
|
||||
|
||||
ggml_graph_dump_dot(&gf, NULL, "test1-5-forward.dot");
|
||||
ggml_graph_dump_dot(&gb, &gf, "test1-5-backward.dot");
|
||||
}
|
||||
|
||||
///////////////////////////////////////////////////////////////
|
||||
|
||||
{
|
||||
struct ggml_tensor * x1 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 3);
|
||||
struct ggml_tensor * x2 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 3);
|
||||
|
||||
ggml_set_param(ctx0, x1);
|
||||
ggml_set_param(ctx0, x2);
|
||||
|
||||
struct ggml_tensor * y =
|
||||
ggml_sum(ctx0,
|
||||
ggml_add(ctx0,
|
||||
ggml_mul(ctx0, x1, x2),
|
||||
ggml_mul(ctx0,
|
||||
ggml_repeat(ctx0, ggml_new_f32(ctx0, -2.0f), x1),
|
||||
ggml_mul(ctx0, x1, x1)
|
||||
)
|
||||
)
|
||||
);
|
||||
|
||||
struct ggml_cgraph gf = ggml_build_forward(y);
|
||||
struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);
|
||||
|
||||
ggml_set_f32(x1, 3.0f);
|
||||
ggml_set_f32(x2, 5.0f);
|
||||
|
||||
ggml_graph_reset(&gf);
|
||||
ggml_set_f32(y->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
printf("y = %f\n", ggml_get_f32_1d(y, 0));
|
||||
printf("df/dx1 = %f %f %f\n",
|
||||
ggml_get_f32_1d(x1->grad, 0),
|
||||
ggml_get_f32_1d(x1->grad, 1),
|
||||
ggml_get_f32_1d(x1->grad, 2));
|
||||
printf("df/dx2 = %f %f %f\n",
|
||||
ggml_get_f32_1d(x2->grad, 0),
|
||||
ggml_get_f32_1d(x2->grad, 1),
|
||||
ggml_get_f32_1d(x2->grad, 2));
|
||||
|
||||
assert(ggml_get_f32_1d(y, 0) == -9.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 0) == -7.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 1) == -7.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 2) == -7.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 0) == 3.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 1) == 3.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 2) == 3.0f);
|
||||
|
||||
ggml_graph_dump_dot(&gf, NULL, "test1-6-forward.dot");
|
||||
ggml_graph_dump_dot(&gb, &gf, "test1-6-backward.dot");
|
||||
}
|
||||
|
||||
///////////////////////////////////////////////////////////////
|
||||
|
||||
{
|
||||
struct ggml_tensor * x1 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 3);
|
||||
struct ggml_tensor * x2 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 3);
|
||||
|
||||
ggml_set_param(ctx0, x1);
|
||||
ggml_set_param(ctx0, x2);
|
||||
|
||||
struct ggml_tensor * y =
|
||||
ggml_sum(ctx0,
|
||||
ggml_sub(ctx0,
|
||||
ggml_mul(ctx0, x1, x2),
|
||||
ggml_mul(ctx0,
|
||||
ggml_mul(ctx0, x1, x1),
|
||||
ggml_repeat(ctx0, ggml_new_f32(ctx0, -2.0f), x1)
|
||||
)
|
||||
)
|
||||
);
|
||||
|
||||
struct ggml_cgraph gf = ggml_build_forward(y);
|
||||
struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);
|
||||
|
||||
ggml_set_f32(x1, 3.0f);
|
||||
ggml_set_f32(x2, 5.0f);
|
||||
|
||||
ggml_graph_reset(&gf);
|
||||
ggml_set_f32(y->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
printf("y = %f\n", ggml_get_f32_1d(y, 0));
|
||||
printf("df/dx1 = %f %f %f\n",
|
||||
ggml_get_f32_1d(x1->grad, 0),
|
||||
ggml_get_f32_1d(x1->grad, 1),
|
||||
ggml_get_f32_1d(x1->grad, 2));
|
||||
printf("df/dx2 = %f %f %f\n",
|
||||
ggml_get_f32_1d(x2->grad, 0),
|
||||
ggml_get_f32_1d(x2->grad, 1),
|
||||
ggml_get_f32_1d(x2->grad, 2));
|
||||
|
||||
assert(ggml_get_f32_1d(y, 0) == 99.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 0) == 17.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 1) == 17.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 2) == 17.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 0) == 3.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 1) == 3.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 2) == 3.0f);
|
||||
|
||||
ggml_graph_dump_dot(&gf, NULL, "test1-7-forward.dot");
|
||||
ggml_graph_dump_dot(&gb, &gf, "test1-7-backward.dot");
|
||||
}
|
||||
|
||||
///////////////////////////////////////////////////////////////
|
||||
|
||||
{
|
||||
struct ggml_tensor * x1 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 3);
|
||||
struct ggml_tensor * x2 = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 3);
|
||||
|
||||
ggml_set_param(ctx0, x1);
|
||||
ggml_set_param(ctx0, x2);
|
||||
|
||||
struct ggml_tensor * y =
|
||||
ggml_abs(ctx0,
|
||||
ggml_sub(ctx0, x1, x2)
|
||||
);
|
||||
|
||||
struct ggml_cgraph gf = ggml_build_forward(y);
|
||||
struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);
|
||||
|
||||
ggml_set_f32(x1, 3.0f);
|
||||
ggml_set_f32(x2, 5.0f);
|
||||
|
||||
ggml_graph_reset(&gf);
|
||||
ggml_set_f32(y->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
printf("y = %f\n", ggml_get_f32_1d(y, 0));
|
||||
printf("df/dx1 = %f %f %f\n",
|
||||
ggml_get_f32_1d(x1->grad, 0),
|
||||
ggml_get_f32_1d(x1->grad, 1),
|
||||
ggml_get_f32_1d(x1->grad, 2));
|
||||
printf("df/dx2 = %f %f %f\n",
|
||||
ggml_get_f32_1d(x2->grad, 0),
|
||||
ggml_get_f32_1d(x2->grad, 1),
|
||||
ggml_get_f32_1d(x2->grad, 2));
|
||||
|
||||
assert(ggml_get_f32_1d(y, 0) == 2.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 0) == -1.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 1) == -1.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 2) == -1.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 0) == 1.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 1) == 1.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 2) == 1.0f);
|
||||
|
||||
ggml_set_f32(x1, 7.0f);
|
||||
ggml_set_f32(x2, 5.0f);
|
||||
|
||||
ggml_graph_reset(&gf);
|
||||
ggml_set_f32(y->grad, 1.0f);
|
||||
|
||||
ggml_graph_compute(ctx0, &gb);
|
||||
|
||||
printf("y = %f\n", ggml_get_f32_1d(y, 0));
|
||||
printf("df/dx1 = %f %f %f\n",
|
||||
ggml_get_f32_1d(x1->grad, 0),
|
||||
ggml_get_f32_1d(x1->grad, 1),
|
||||
ggml_get_f32_1d(x1->grad, 2));
|
||||
printf("df/dx2 = %f %f %f\n",
|
||||
ggml_get_f32_1d(x2->grad, 0),
|
||||
ggml_get_f32_1d(x2->grad, 1),
|
||||
ggml_get_f32_1d(x2->grad, 2));
|
||||
|
||||
assert(ggml_get_f32_1d(y, 0) == 2.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 0) == 1.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 1) == 1.0f);
|
||||
assert(ggml_get_f32_1d(x1->grad, 2) == 1.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 0) == -1.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 1) == -1.0f);
|
||||
assert(ggml_get_f32_1d(x2->grad, 2) == -1.0f);
|
||||
|
||||
ggml_graph_dump_dot(&gf, NULL, "test1-8-forward.dot");
|
||||
ggml_graph_dump_dot(&gb, &gf, "test1-8-backward.dot");
|
||||
}
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,177 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include <math.h>
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <assert.h>
|
||||
|
||||
bool is_close(float a, float b, float epsilon) {
|
||||
return fabs(a - b) < epsilon;
|
||||
}
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = 128*1024*1024,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
//struct ggml_opt_params opt_params = ggml_opt_default_params(GGML_OPT_LBFGS);
|
||||
|
||||
struct ggml_opt_params opt_params = ggml_opt_default_params(GGML_OPT_ADAM);
|
||||
opt_params.adam.alpha = 0.01f;
|
||||
|
||||
// original threads: 8
|
||||
int nthreads = 8;
|
||||
const char *env = getenv("GGML_NTHREADS");
|
||||
if (env != NULL) {
|
||||
nthreads = atoi(env);
|
||||
}
|
||||
if (argc > 1) {
|
||||
nthreads = atoi(argv[1]);
|
||||
}
|
||||
opt_params.n_threads = nthreads;
|
||||
printf("test2: n_threads:%d\n", opt_params.n_threads);
|
||||
|
||||
const float xi[] = { 1.0f, 2.0f, 3.0f, 4.0f, 5.0f , 6.0f, 7.0f, 8.0f, 9.0f, 10.0f, };
|
||||
float yi[] = { 15.0f, 25.0f, 35.0f, 45.0f, 55.0f, 65.0f, 75.0f, 85.0f, 95.0f, 105.0f, };
|
||||
|
||||
const int n = sizeof(xi)/sizeof(xi[0]);
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
|
||||
struct ggml_tensor * x = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, n);
|
||||
struct ggml_tensor * y = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, n);
|
||||
|
||||
for (int i = 0; i < n; i++) {
|
||||
((float *) x->data)[i] = xi[i];
|
||||
((float *) y->data)[i] = yi[i];
|
||||
}
|
||||
|
||||
{
|
||||
struct ggml_tensor * t0 = ggml_new_f32(ctx0, 0.0f);
|
||||
struct ggml_tensor * t1 = ggml_new_f32(ctx0, 0.0f);
|
||||
|
||||
// initialize auto-diff parameters:
|
||||
ggml_set_param(ctx0, t0);
|
||||
ggml_set_param(ctx0, t1);
|
||||
|
||||
// f = sum_i[(t0 + t1*x_i - y_i)^2]/(2n)
|
||||
struct ggml_tensor * f =
|
||||
ggml_div(ctx0,
|
||||
ggml_sum(ctx0,
|
||||
ggml_sqr(ctx0,
|
||||
ggml_sub(ctx0,
|
||||
ggml_add(ctx0,
|
||||
ggml_mul(ctx0, x, ggml_repeat(ctx0, t1, x)),
|
||||
ggml_repeat(ctx0, t0, x)),
|
||||
y)
|
||||
)
|
||||
),
|
||||
ggml_new_f32(ctx0, 2.0f*n));
|
||||
|
||||
enum ggml_opt_result res = ggml_opt(NULL, opt_params, f);
|
||||
|
||||
assert(res == GGML_OPT_OK);
|
||||
|
||||
printf("t0 = %f\n", ggml_get_f32_1d(t0, 0));
|
||||
printf("t1 = %f\n", ggml_get_f32_1d(t1, 0));
|
||||
|
||||
assert(is_close(ggml_get_f32_1d(t0, 0), 5.0f, 1e-3f));
|
||||
assert(is_close(ggml_get_f32_1d(t1, 0), 10.0f, 1e-3f));
|
||||
}
|
||||
|
||||
{
|
||||
struct ggml_tensor * t0 = ggml_new_f32(ctx0, -1.0f);
|
||||
struct ggml_tensor * t1 = ggml_new_f32(ctx0, 9.0f);
|
||||
|
||||
ggml_set_param(ctx0, t0);
|
||||
ggml_set_param(ctx0, t1);
|
||||
|
||||
// f = 0.5*sum_i[abs(t0 + t1*x_i - y_i)]/n
|
||||
struct ggml_tensor * f =
|
||||
ggml_mul(ctx0,
|
||||
ggml_new_f32(ctx0, 1.0/(2*n)),
|
||||
ggml_sum(ctx0,
|
||||
ggml_abs(ctx0,
|
||||
ggml_sub(ctx0,
|
||||
ggml_add(ctx0,
|
||||
ggml_mul(ctx0, x, ggml_repeat(ctx0, t1, x)),
|
||||
ggml_repeat(ctx0, t0, x)),
|
||||
y)
|
||||
)
|
||||
)
|
||||
);
|
||||
|
||||
|
||||
enum ggml_opt_result res = ggml_opt(NULL, opt_params, f);
|
||||
|
||||
assert(res == GGML_OPT_OK);
|
||||
assert(is_close(ggml_get_f32_1d(t0, 0), 5.0f, 1e-2f));
|
||||
assert(is_close(ggml_get_f32_1d(t1, 0), 10.0f, 1e-2f));
|
||||
}
|
||||
|
||||
{
|
||||
struct ggml_tensor * t0 = ggml_new_f32(ctx0, 5.0f);
|
||||
struct ggml_tensor * t1 = ggml_new_f32(ctx0, -4.0f);
|
||||
|
||||
ggml_set_param(ctx0, t0);
|
||||
ggml_set_param(ctx0, t1);
|
||||
|
||||
// f = t0^2 + t1^2
|
||||
struct ggml_tensor * f =
|
||||
ggml_add(ctx0,
|
||||
ggml_sqr(ctx0, t0),
|
||||
ggml_sqr(ctx0, t1)
|
||||
);
|
||||
|
||||
enum ggml_opt_result res = ggml_opt(NULL, opt_params, f);
|
||||
|
||||
assert(res == GGML_OPT_OK);
|
||||
assert(is_close(ggml_get_f32_1d(f, 0), 0.0f, 1e-3f));
|
||||
assert(is_close(ggml_get_f32_1d(t0, 0), 0.0f, 1e-3f));
|
||||
assert(is_close(ggml_get_f32_1d(t1, 0), 0.0f, 1e-3f));
|
||||
}
|
||||
|
||||
/////////////////////////////////////////
|
||||
|
||||
{
|
||||
struct ggml_tensor * t0 = ggml_new_f32(ctx0, -7.0f);
|
||||
struct ggml_tensor * t1 = ggml_new_f32(ctx0, 8.0f);
|
||||
|
||||
ggml_set_param(ctx0, t0);
|
||||
ggml_set_param(ctx0, t1);
|
||||
|
||||
// f = (t0 + 2*t1 - 7)^2 + (2*t0 + t1 - 5)^2
|
||||
struct ggml_tensor * f =
|
||||
ggml_add(ctx0,
|
||||
ggml_sqr(ctx0,
|
||||
ggml_sub(ctx0,
|
||||
ggml_add(ctx0,
|
||||
t0,
|
||||
ggml_mul(ctx0, t1, ggml_new_f32(ctx0, 2.0f))),
|
||||
ggml_new_f32(ctx0, 7.0f)
|
||||
)
|
||||
),
|
||||
ggml_sqr(ctx0,
|
||||
ggml_sub(ctx0,
|
||||
ggml_add(ctx0,
|
||||
ggml_mul(ctx0, t0, ggml_new_f32(ctx0, 2.0f)),
|
||||
t1),
|
||||
ggml_new_f32(ctx0, 5.0f)
|
||||
)
|
||||
)
|
||||
);
|
||||
|
||||
enum ggml_opt_result res = ggml_opt(NULL, opt_params, f);
|
||||
|
||||
assert(res == GGML_OPT_OK);
|
||||
assert(is_close(ggml_get_f32_1d(f, 0), 0.0f, 1e-3f));
|
||||
assert(is_close(ggml_get_f32_1d(t0, 0), 1.0f, 1e-3f));
|
||||
assert(is_close(ggml_get_f32_1d(t1, 0), 3.0f, 1e-3f));
|
||||
}
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,96 @@
|
|||
#include "ggml/ggml.h"
|
||||
|
||||
#include <math.h>
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <assert.h>
|
||||
|
||||
bool is_close(float a, float b, float epsilon) {
|
||||
return fabs(a - b) < epsilon;
|
||||
}
|
||||
|
||||
int main(int argc, const char ** argv) {
|
||||
struct ggml_init_params params = {
|
||||
.mem_size = 1024*1024*1024,
|
||||
.mem_buffer = NULL,
|
||||
.no_alloc = false,
|
||||
};
|
||||
|
||||
struct ggml_opt_params opt_params = ggml_opt_default_params(GGML_OPT_LBFGS);
|
||||
//struct ggml_opt_params opt_params = ggml_opt_default_params(GGML_OPT_ADAM);
|
||||
|
||||
opt_params.n_threads = (argc > 1) ? atoi(argv[1]) : 8;
|
||||
|
||||
const int NP = 1 << 12;
|
||||
const int NF = 1 << 8;
|
||||
|
||||
struct ggml_context * ctx0 = ggml_init(params);
|
||||
|
||||
struct ggml_tensor * F = ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, NF, NP);
|
||||
struct ggml_tensor * l = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, NP);
|
||||
|
||||
// regularization weight
|
||||
struct ggml_tensor * lambda = ggml_new_f32(ctx0, 1e-5f);
|
||||
|
||||
srand(0);
|
||||
|
||||
for (int j = 0; j < NP; j++) {
|
||||
const float ll = j < NP/2 ? 1.0f : -1.0f;
|
||||
((float *)l->data)[j] = ll;
|
||||
|
||||
for (int i = 0; i < NF; i++) {
|
||||
((float *)F->data)[j*NF + i] = ((ll > 0 && i < NF/2 ? 1.0f : ll < 0 && i >= NF/2 ? 1.0f : 0.0f) + ((float)rand()/(float)RAND_MAX - 0.5f)*0.1f)/(0.5f*NF);
|
||||
}
|
||||
}
|
||||
|
||||
{
|
||||
// initial guess
|
||||
struct ggml_tensor * x = ggml_set_f32(ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, NF), 0.0f);
|
||||
|
||||
ggml_set_param(ctx0, x);
|
||||
|
||||
// f = sum[(fj*x - l)^2]/n + lambda*|x^2|
|
||||
struct ggml_tensor * f =
|
||||
ggml_add(ctx0,
|
||||
ggml_div(ctx0,
|
||||
ggml_sum(ctx0,
|
||||
ggml_sqr(ctx0,
|
||||
ggml_sub(ctx0,
|
||||
ggml_mul_mat(ctx0, F, x),
|
||||
l)
|
||||
)
|
||||
),
|
||||
ggml_new_f32(ctx0, NP)
|
||||
),
|
||||
ggml_mul(ctx0,
|
||||
ggml_sum(ctx0, ggml_sqr(ctx0, x)),
|
||||
lambda)
|
||||
);
|
||||
|
||||
enum ggml_opt_result res = ggml_opt(NULL, opt_params, f);
|
||||
|
||||
assert(res == GGML_OPT_OK);
|
||||
|
||||
// print results
|
||||
for (int i = 0; i < 16; i++) {
|
||||
printf("x[%3d] = %g\n", i, ((float *)x->data)[i]);
|
||||
}
|
||||
printf("...\n");
|
||||
for (int i = NF - 16; i < NF; i++) {
|
||||
printf("x[%3d] = %g\n", i, ((float *)x->data)[i]);
|
||||
}
|
||||
printf("\n");
|
||||
|
||||
for (int i = 0; i < NF; ++i) {
|
||||
if (i < NF/2) {
|
||||
assert(is_close(((float *)x->data)[i], 1.0f, 1e-2f));
|
||||
} else {
|
||||
assert(is_close(((float *)x->data)[i], -1.0f, 1e-2f));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
ggml_free(ctx0);
|
||||
|
||||
return 0;
|
||||
}
|
||||
Loading…
Reference in New Issue