vault backup: 2024-10-02 23:19:31
Affected files: .obsidian/workspace.json ComfyUI Fundamentals.md
This commit is contained in:
parent
5a81adf011
commit
18ebe1459f
|
|
@ -18,8 +18,21 @@
|
||||||
"source": false
|
"source": false
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"id": "21582480bbd67502",
|
||||||
|
"type": "leaf",
|
||||||
|
"state": {
|
||||||
|
"type": "markdown",
|
||||||
|
"state": {
|
||||||
|
"file": "ComfyUI Fundamentals.md",
|
||||||
|
"mode": "source",
|
||||||
|
"source": false
|
||||||
|
}
|
||||||
|
}
|
||||||
}
|
}
|
||||||
]
|
],
|
||||||
|
"currentTab": 1
|
||||||
}
|
}
|
||||||
],
|
],
|
||||||
"direction": "vertical"
|
"direction": "vertical"
|
||||||
|
|
@ -85,7 +98,7 @@
|
||||||
"state": {
|
"state": {
|
||||||
"type": "backlink",
|
"type": "backlink",
|
||||||
"state": {
|
"state": {
|
||||||
"file": "ComfyUI.md",
|
"file": "ComfyUI Fundamentals.md",
|
||||||
"collapseAll": false,
|
"collapseAll": false,
|
||||||
"extraContext": false,
|
"extraContext": false,
|
||||||
"sortOrder": "alphabetical",
|
"sortOrder": "alphabetical",
|
||||||
|
|
@ -102,7 +115,7 @@
|
||||||
"state": {
|
"state": {
|
||||||
"type": "outgoing-link",
|
"type": "outgoing-link",
|
||||||
"state": {
|
"state": {
|
||||||
"file": "ComfyUI.md",
|
"file": "ComfyUI Fundamentals.md",
|
||||||
"linksCollapsed": false,
|
"linksCollapsed": false,
|
||||||
"unlinkedCollapsed": true
|
"unlinkedCollapsed": true
|
||||||
}
|
}
|
||||||
|
|
@ -125,7 +138,7 @@
|
||||||
"state": {
|
"state": {
|
||||||
"type": "outline",
|
"type": "outline",
|
||||||
"state": {
|
"state": {
|
||||||
"file": "ComfyUI.md"
|
"file": "ComfyUI Fundamentals.md"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
|
@ -168,8 +181,9 @@
|
||||||
"copilot:Copilot Chat": false
|
"copilot:Copilot Chat": false
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"active": "ad5116a19015e36f",
|
"active": "21582480bbd67502",
|
||||||
"lastOpenFiles": [
|
"lastOpenFiles": [
|
||||||
|
"ComfyUI Fundamentals.md",
|
||||||
"ComfyUI.md",
|
"ComfyUI.md",
|
||||||
"nocoDB.md",
|
"nocoDB.md",
|
||||||
"Untitled 2.md",
|
"Untitled 2.md",
|
||||||
|
|
@ -195,7 +209,6 @@
|
||||||
"Install neo4j on Debian.md",
|
"Install neo4j on Debian.md",
|
||||||
"Debian.md",
|
"Debian.md",
|
||||||
"GNU-Linux.md",
|
"GNU-Linux.md",
|
||||||
"Linux.md",
|
|
||||||
"Untitled",
|
"Untitled",
|
||||||
"Taylor Swift",
|
"Taylor Swift",
|
||||||
"GNU"
|
"GNU"
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,232 @@
|
||||||
|
|
||||||
|
https://lemmy.world/post/6034170
|
||||||
|
|
||||||
|
Various “studies” (of various qualities) about samplers in Stable Diffusion has been done over the yeas. By now, we should all understand the weaknesses of such studies, including the subjectivity of quality assessment and the randomness of generation (only amplified by the fact that they don’t all converge to the same image for the same seed!)
|
||||||
|
|
||||||
|
I felt it was time for an updated, large, well-controlled study:
|
||||||
|
|
||||||
|
[https://docs.google.com/spreadsheets/d/1SOF9adj1CT9bX0x5h45J8p4PakbJXqFB0kPxAOm_3qw/edit?usp=sharing](https://docs.google.com/spreadsheets/d/1SOF9adj1CT9bX0x5h45J8p4PakbJXqFB0kPxAOm_3qw/edit?usp=sharing)
|
||||||
|
|
||||||
|
Twelve separate prompts were run on SDXL 1.0 (cfg_scale==7) at the following step counts: 6, 8, 10, 12, 16, 20, 24, 32, 48, 100, for every sampler except DPM Adaptive++ - a total of **3480 images rated**. To further increase the weighted number of images and reduce random noise, ratings for a given prompt were partially smoothed by partially averaging with their neighboring number of steps.
|
||||||
|
|
||||||
|
++ - DPM Adaptive ignores the step count and runs to convergence, and thus cannot be rated at a fixed number of steps.
|
||||||
|
|
||||||
|
Also complicating factors is the fact that some samplers run at half the speed of others:
|
||||||
|
|
||||||
|
- DPM++ SDE
|
||||||
|
- DPM++ SDE Karras
|
||||||
|
- Heun
|
||||||
|
- DPM2
|
||||||
|
- DPM2 a
|
||||||
|
- DPM++ 2S a
|
||||||
|
- DPM++ 2S a Karras
|
||||||
|
- Restart
|
||||||
|
|
||||||
|
Hence, two sets of graphs were made: one set rating them purely by number of steps; and the other rating by the number of steps divided by their speed factor (e.g. the slower samplers are rated at half as many steps as the faster samplers).
|
||||||
|
|
||||||
|
Ratings are a subjective combination of two factors, on a scale of 0 to 1: accuracy (how accurately does it represent the prompt?) and aesthetics (how much would I be willing to have this on my wall, without further rework?). This allowed for the phenomenon where “not all poorly converged models are equal” - some poorly-converged models are generally ugly, while others can have weird but sometimes pretty abstract aspects to their poor convergence.
|
||||||
|
|
||||||
|
A word of caution: though a good number of images are used, there’s still going to be alot of noise in these ratings. In particular, at e.g. 48 and esp. 100 steps, most of the ordering you’re seeing in sampler quality (except for the lousy ones) is just going to be random noise. If two samplers have similar ratings, they should be considered as equivalent, even if one came out slightly better than the other.
|
||||||
|
|
||||||
|
On the graphs, a variety of colour and pattern codings are used, for visual convenience:
|
||||||
|
|
||||||
|
- Maroon: DPM2 group
|
||||||
|
- Red: DPM++ SDE group
|
||||||
|
- Orange: DPM++ 2M group
|
||||||
|
- Yellow: DPM++ 3M group
|
||||||
|
- Green: Euler group
|
||||||
|
- Blue: LMS group
|
||||||
|
- Purple (dark): DPM++ 2S group
|
||||||
|
- Purple(medium): DDIM
|
||||||
|
- Slate: DPM Fast
|
||||||
|
- Brown: PLMS
|
||||||
|
- Pink: Restart
|
||||||
|
- Navy: UniPC
|
||||||
|
- Light grey: Heun
|
||||||
|
- Light orange: DPM++ 2M Heun group
|
||||||
|
- Dark maroon: DPM2 a group
|
||||||
|
- Dark green: Euler a
|
||||||
|
- Black border: fast sampler
|
||||||
|
- Grey border: slow sampler
|
||||||
|
- Dotted border: SDE
|
||||||
|
- Dashed border: Karras
|
||||||
|
- Dot-dash border: SDE Karras
|
||||||
|
- Dot-longdash border: SDE Exponential
|
||||||
|
|
||||||
|
All of this get stated, let’s get started!
|
||||||
|
|
||||||
|
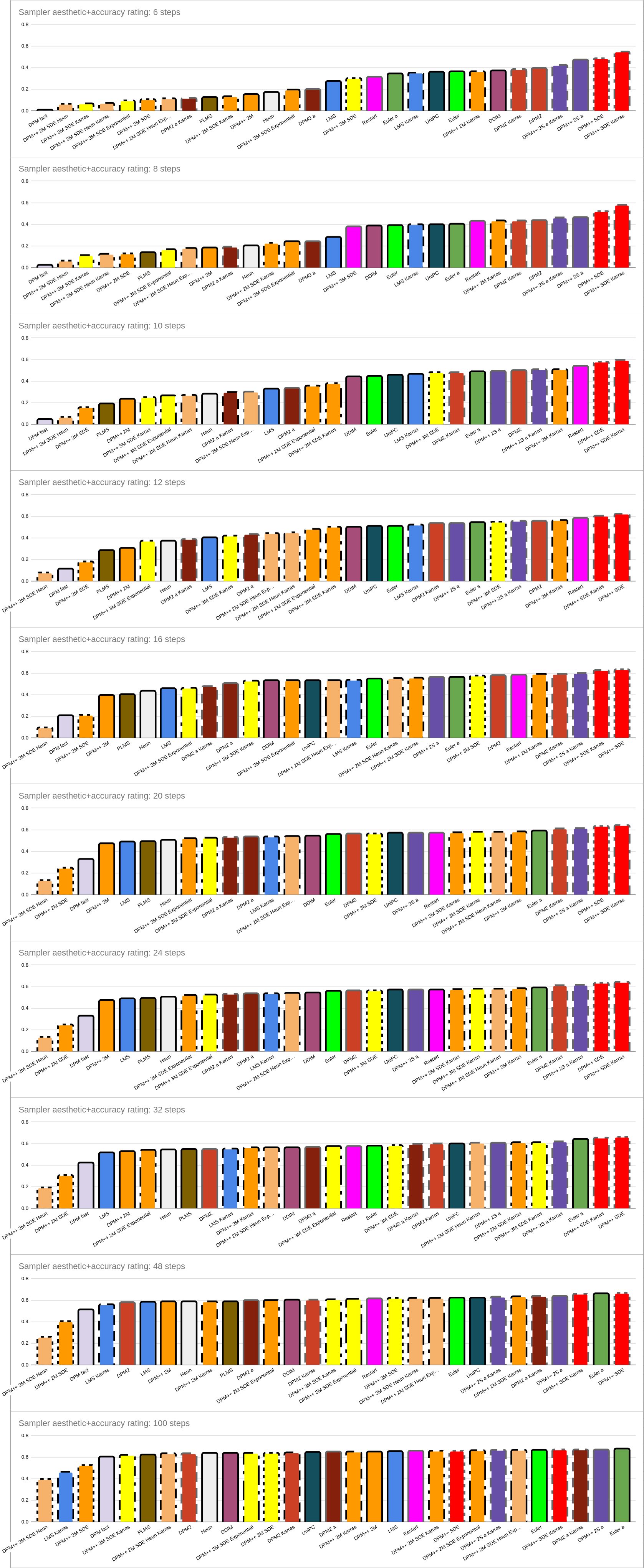
**1) Steps-Only** _(Left-hand graphs)_
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
- DPM++ SDE, and esp. DPM++ SDE Karras (red), rock this comparison. At high step counts there’s not much of a difference between the two, but at low step counts, DPM++ SDE Karras is much better. It’s so good that at 6 steps it gets results that most samplers don’t beat until around 20 steps.
|
||||||
|
|
||||||
|
If you care only about step counts, end this right here: chose DPM++ SDE Karras
|
||||||
|
|
||||||
|
- DPM-based Karras samplers in general (dashed outlines) - with the exception of those samplers that are lousy in general) - perform very well at low steps, but the advantages are lost at higher steps.
|
||||||
|
|
||||||
|
- Slow samplers (grey outlines) in general perform well - though this shouldn’t be surprising, as they’re doing more work per step.
|
||||||
|
|
||||||
|
- Other contenders for good samplers are the DPM++ 2S group (esp. at lower step counts), DPM2 group (esp. at lower step counts), Restart (esp. at higher step counts), and to a lesser extent, DPM++ 2M Karras (esp. at higher step counts) and Euler group (at higher step counts - esp. ancestral).
|
||||||
|
|
||||||
|
- Don’t even dream of touching DPM fast, DPM++2 2M SDE or DPM++ 2M SDE Heun. Also avoid: DPM++ 2M, LMS, PLMS, Heun. Exponential samplers aren’t great either. The only DPM++ 2M group samplers which should be considered are Karras and SDE Karras.
|
||||||
|
|
||||||
|
- Again, at high step counts, don’t pay much attention to the order, as most samplers are fully converged, and you’re just viewing noise.
|
||||||
|
|
||||||
|
|
||||||
|
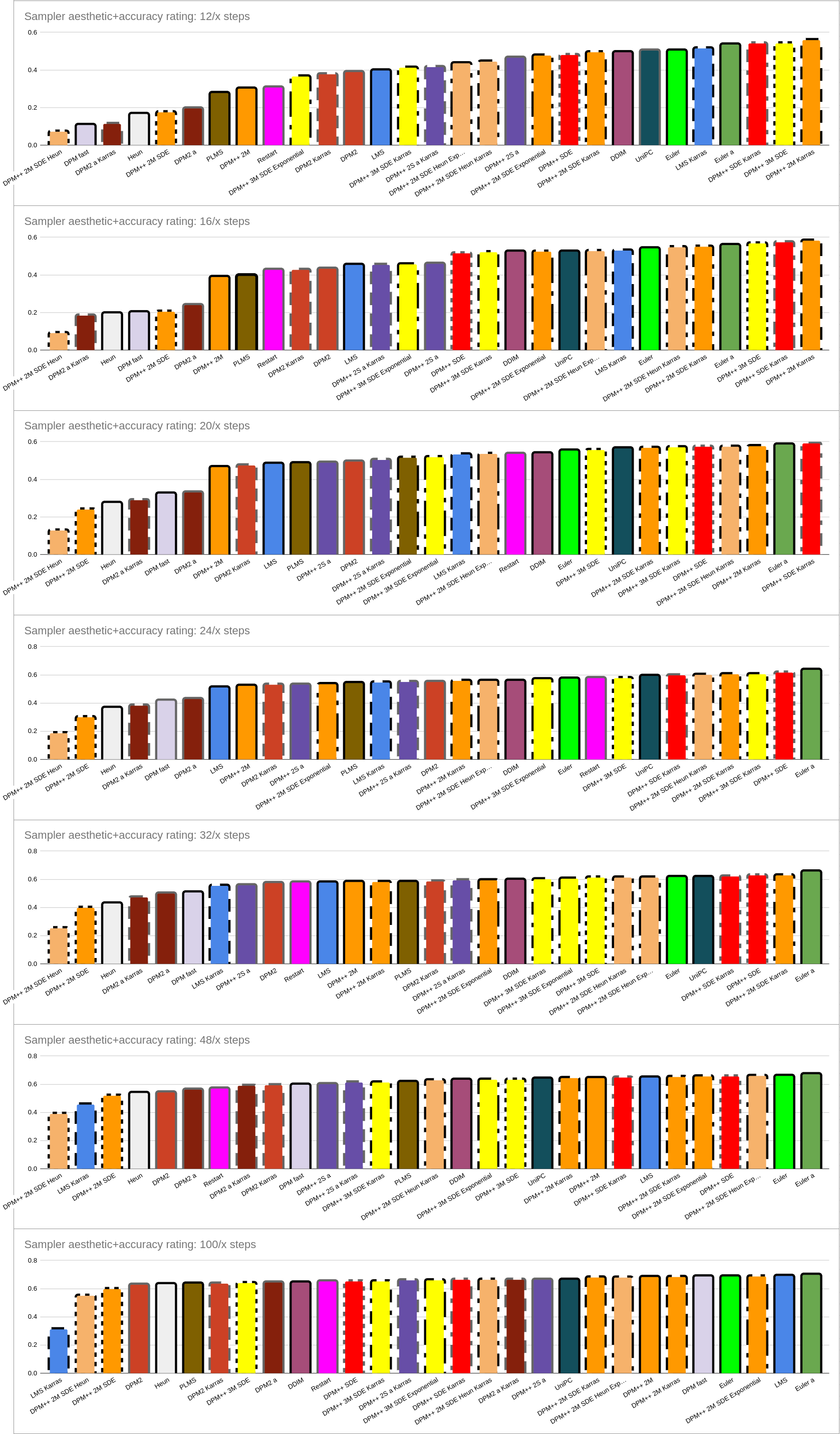
**2) Accounting For Sampler Speed** _(Right-hand graphs)_
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
There’s a little more complexity here
|
||||||
|
|
||||||
|
- At low steps, DPM++ 2M Karras wins (and makes a strong showing throughout).
|
||||||
|
|
||||||
|
- At high steps, Euler a wins (and Euler isn’t bad either). Like 2PM++ 2M Karras, Euler a also makes a strong showing throughout.
|
||||||
|
|
||||||
|
- Despite being slow and thus only getting half as many steps, the SDE samplers still make an impressive showing in this comparison.
|
||||||
|
|
||||||
|
- DPM+ 3M is very good at low steps but only pretty good at high steps.
|
||||||
|
|
||||||
|
- DPM-based Karras samplers continue to offer a boost at low steps without hurting at high steps.
|
||||||
|
|
||||||
|
- Don’t even think about DPM++ 2M SDE Heun. Also avoid: DPM++ 2M SDE, Heun, DPM2 group and DPM2 a group, PLMS, and honestly a lot of others aren’t great.
|
||||||
|
|
||||||
|
- LMS Karras is pretty good at low steps but actually the worst at high steps, for some reason - it’s quality _drops_ at high step counts.
|
||||||
|
|
||||||
|
- As usual, don’t pay too much attention to the ordering at 100/x steps (or to a lesser extent, 48/x steps), as images tend to be well converged regardless of sampler.
|
||||||
|
|
||||||
|
|
||||||
|
-= Overall conclusions =-
|
||||||
|
|
||||||
|
1. If you want an overall good sampler, regardless of metric
|
||||||
|
2. If you only care about quality for a given number of steps, go with DPM++ SDE Karras
|
||||||
|
3. If you care about speed for a given number of steps, and don’t want to break it down further, go with DPM++ 2M Karras or Euler a
|
||||||
|
4. If you want to break it down further, go with DPM++ 2M Karras at low step counts and Euler a at high step counts.
|
||||||
|
|
||||||
|
**-= Further work =-**
|
||||||
|
|
||||||
|
If anyone wants to further help improve this with more data (thus reducing random noise), feel free to add to the aforementioned project link spreadsheet:
|
||||||
|
|
||||||
|
[https://docs.google.com/spreadsheets/d/1SOF9adj1CT9bX0x5h45J8p4PakbJXqFB0kPxAOm_3qw/edit?usp=sharing](https://docs.google.com/spreadsheets/d/1SOF9adj1CT9bX0x5h45J8p4PakbJXqFB0kPxAOm_3qw/edit?usp=sharing)
|
||||||
|
|
||||||
|
Pick a prompt, go to the next unused ratings block, write down the positive and negative prompts in column P (please, nothing NSFW, offensive, suggestive or objectifying), render all combinations of steps and samplers with that prompt (using SDXL 1.0, CFG scale=7, 1024x1024, no other plugins or features), and rate them all. Choose a different seed for each step count to avoid e.g. ancestrals getting a better or worse image than non-ancestrals getting boosted or penalized on every single step. Remember that you’re balancing out (A) how accurately the image corresponds to the prompt, and (B) how aesthetic it is, e.g. how keen would you be on hanging it in your living room?
|
||||||
|
|
||||||
|
All calculations will be redone automatically, and the ratings resorted. However, the colours and border styles on the graphs won’t move with any changing ratings - this has to be done manually, which takes some time. I find this easiest to do by copying column A into column D to change the labels into descriptions of their colour and border style, and then when I’m done, copying column B into column D to restore the names. In the colour descriptions, a colour name like 3darkgreen means “the third step from the bottom of the green column, moving upward” (“darkgreen” would mean the bottom, "2darkgreen the second, etc), while a colour name like “3lightmaroon” would mean “the third step from the lighest colour in the maroon column, moving downward”. Something just like “green” would mean the saturated primary colour at the top of the green column. If this is too much work or too confusing, just let me know when you’re entirely finished and I’ll update the graphs when I get a chance.
|
||||||
|
|
||||||
|
**ED:** Note based on a comment below: when I write _“fully converged”_, it probably would be better to write something like _“has reached its full aesthetic potential”_, since not all models _literally_ converge.
|
||||||
|
|
||||||
|
--------
|
||||||
|
# What is ancestral sampling?
|
||||||
|
|
||||||
|
https://www.reddit.com/r/deeplearning/comments/cgqpde/what_is_ancestral_sampling/
|
||||||
|
|
||||||
|
[mpatacchiola](https://www.reddit.com/user/mpatacchiola/)
|
||||||
|
|
||||||
|
•[5y ago](https://www.reddit.com/r/deeplearning/comments/cgqpde/comment/eukxvz4/)•Edited 5y ago•
|
||||||
|
|
||||||
|
The easiest way of understanding ancestral sampling is through a simple Bayesian network with two nodes, a parent node X and a child node Y. Let's suppose that the two nodes have an associated Bernoulli distribution with two states True and False. You can think of X as a random variable indicating if the sky is cloudy, and Y as a random variable indicating the presence of rain. We can safely assume that X causes Y, meaning that there is a direct edge from X to Y.
|
||||||
|
|
||||||
|
Node X (cloudy) has the following prior distribution: True=25%; False=75%
|
||||||
|
|
||||||
|
Node Y (rain) has a prior distribution that depends on the value of X, this is called a Conditional Probability Table (CPT):
|
||||||
|
|
||||||
|
If X=True then Y is True=60% or False=40%
|
||||||
|
|
||||||
|
if X=False then Y is True=20% or False=80%
|
||||||
|
|
||||||
|
Now we are asked to estimate the joint probability P(X=True, Y=False), meaning the probability that the sky is cloudy and it is not raining. How to do it? Ancestral sampling is one way. You start from the parent node (node X in our case) and you draw a sample from its distribution. Let's say we pick X=False (it has 75% probability, then it is more likely). Now we sample from the CPT of node Y taking into account that X is False, we have 20% chances that Y is True and 80% chances that it is False. Let's say we pick Y=False.
|
||||||
|
|
||||||
|
You have to repeat this process N times and count how often you get the target combination X=True, Y=False. The proportion of successful attempts M over the total number of attempts N, gives you the probability of P(X=True, Y=False). As the size of N increases you are guaranteed to converge to the true probability. Please notice that in this trivial example P(X=True, Y=False) can be found pretty easily, however in complex graphs this is no more the case.
|
||||||
|
|
||||||
|
I hope that at this point it should be clear to you the origin of the name "ancestral" (or forward) sampling. It simply means that we are starting from the parent nodes (the ancestors) and then moving forward to the children nodes.
|
||||||
|
|
||||||
|
--------
|
||||||
|
# Sampling Method
|
||||||
|
|
||||||
|
https://www.reddit.com/r/StableDiffusion/comments/zgu6wd/comment/izkhkxc/?context=3
|
||||||
|
|
||||||
|
[ManBearScientist](https://www.reddit.com/user/ManBearScientist/)
|
||||||
|
|
||||||
|
First, you have to understand what samplers _are_. These are discretized differential equations. I'm not going to go into these **at all** in this post, but I've covered them before.
|
||||||
|
|
||||||
|
DDIM and PLMS were the original samplers. They were part of [Latent Diffusion's repository](https://github.com/CompVis/latent-diffusion). They stand for the papers that introduced them, Denoising Diffusion Implicit Models and Pseudo Numerical Methods for Diffusion Models on Manifolds.
|
||||||
|
|
||||||
|
Almost **all** other samplers come from work done by @RiversHaveWings or Katherine Crowson, which is mostly contained in her work at [this repository](https://github.com/crowsonkb/k-diffusion/blob/master/k_diffusion/sampling.py). She is listed as the principal researcher at Stability AI. Her notes for those samplers are as follows:
|
||||||
|
|
||||||
|
- Euler - Implements Algorithm 2 (Euler steps) from Karras et al. (2022)
|
||||||
|
|
||||||
|
- Euler_a - Ancestral sampling with Euler method steps.
|
||||||
|
|
||||||
|
- LMS - No information, but can be inferred that the name comes from linear multistep coefficients
|
||||||
|
|
||||||
|
- Heun - Implements Algorithm 2 (Heun steps) from Karras et al. (2022).
|
||||||
|
|
||||||
|
- DPM2 - A sampler inspired by DPM-Solver-2 and Algorithm 2 from Karras et al. (2022).
|
||||||
|
|
||||||
|
- DPM2 a - Ancestral sampling with DPM-Solver second-order steps
|
||||||
|
|
||||||
|
- DPM++ 2s a - Ancestral sampling with DPM-Solver++(2S) second-order steps
|
||||||
|
|
||||||
|
- DPM++ 2M - DPM-Solver++(2M)
|
||||||
|
|
||||||
|
- DPM++ SDE - DPM-Solver++ (stochastic)
|
||||||
|
|
||||||
|
- DPM fast - DPM-Solver-Fast (fixed step size). See [https://arxiv.org/abs/2206.00927](https://arxiv.org/abs/2206.00927)
|
||||||
|
|
||||||
|
- DPM adaptive - DPM-Solver-12 and 23 (adaptive step size). See [https://arxiv.org/abs/2206.00927](https://arxiv.org/abs/2206.00927)
|
||||||
|
|
||||||
|
|
||||||
|
The 'Karras' versions of these weren't made by Karras as far as I can tell, but instead are using a variance-exploding scheduler from the Karras paper, which of course is extra confusing given that most of the other samplers were inspired by that paper in the first place.
|
||||||
|
|
||||||
|
In terms of "what will I get at high step counts", most of the time you will get similar pictures from:
|
||||||
|
|
||||||
|
- Group A: Euler_a, DPM2 a, DPM++ 2S a, DPM fast (after many steps), DPM adaptive, DPM2 a Karras
|
||||||
|
|
||||||
|
- Group B: Euler, LMS, Heun, DPM2, DPM++ 2M, DDIM, PLMS
|
||||||
|
|
||||||
|
- Group C: LMS Karras, DPM2 Karras, DPM++ 2M Karras
|
||||||
|
|
||||||
|
|
||||||
|
As far as convergence behavior:
|
||||||
|
|
||||||
|
- Does not converge: Euler_a, DPM2 a, DPM Fast, DDIM, PLMS, DPM adaptive, DPM2 a Karras
|
||||||
|
|
||||||
|
- Converges: Euler, LMS, Heun, DPM2, DPM++ 2M, LMS Karras, DPM2 Karras, DPM++ 2M Karras
|
||||||
|
|
||||||
|
|
||||||
|
By required steps:
|
||||||
|
|
||||||
|
- Euler_a = Euler = DPM++2M = LMS Karras (image degraded at high steps) >
|
||||||
|
|
||||||
|
- LMS = DPM++ 2M Karras = Heun (slower) = DPM++ 2S a (slower) = DPM++ 2S a Karras >
|
||||||
|
|
||||||
|
- DDIM = PLMS = DPM2 (slower) = DPM 2 Karras>
|
||||||
|
|
||||||
|
- DPM Fast = DPM2 a (slower)
|
||||||
|
|
||||||
|
|
||||||
|
These all give somewhat different results so a person could prefer the output of any of the models at a given CFG or step range. I do think that there is an argument to be made that DPM++ 2M and Euler_a are good generic samplers for most people, however, as they both resolve to a good picture at low seeds (sub-20) without a hit to iteration speed. DPM++ 2M has the advantage of converging to a single image more often (if you choose to run the same image at higher seed), but is slightly more prone to deformations at high CFG.
|
||||||
|
|
||||||
|
To combine all the above:
|
||||||
|
|
||||||
|
- Fast, new, converges: DPM++ 2M, DPM++ 2M Karras
|
||||||
|
|
||||||
|
- Fast, doesn't converge: Euler_a, DPM2 a Karras
|
||||||
|
|
||||||
|
- Others worth considering: DPM2 a, LMS, DPM++ 2S a Karras
|
||||||
|
|
||||||
|
- Bugged: LMS Karras (at high steps
|
||||||
|
|
||||||
|
- Older, fast but maybe lower quality final result: Euler, LMS, Heun
|
||||||
|
|
||||||
|
- Slow: DDIM, PLMS, DPM2, DPM 2 Karras, DPM Fast, DPM2 a
|
||||||
|
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
#### TL;DR
|
||||||
|
|
||||||
|
These are confusingly named and mostly come from academic papers. The actual mechanisms of each sampler aren't really relevant to their outputs. In general PLMS, DDIM, or DPM fast are slower and give worse results.
|
||||||
|
|
||||||
|
Instead, try out DPM++ 2M and Euler_a, along with DPM++ 2M Karras. These should all give good results at a low seed value.
|
||||||
Loading…
Reference in New Issue